Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
2404.09931
0
0

Abstract
Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a method for detecting buildings in mobile LiDAR point cloud data using a language-vision model, enabling zero-shot detection without any labeled training data.
- The approach leverages the ability of large language models to encode semantic information, combined with a point cloud recognition model, to identify building structures in 3D scans.
- The system is designed to be generalizable, allowing it to detect buildings without requiring manually labeled training examples.
Plain English Explanation
This research paper introduces a new way to automatically detect buildings in 3D point cloud data captured by mobile laser scanning devices, without needing any pre-labeled training examples. The key idea is to combine the natural language understanding capabilities of large language models with a 3D object recognition model.
Language models like GPT-3 have become incredibly good at encoding semantic information about the world into their parameters. The researchers leverage this by using the language model to provide a semantic description of what a "building" is. They then connect this with a 3D object detection model, allowing the system to recognize buildings in the point cloud data without requiring any manually labeled training examples.
This "zero-shot" approach, where the model can detect new concepts without prior training, is a powerful capability that could enable rapid deployment of 3D perception systems in new environments or applications. Instead of painstakingly labeling thousands of examples, the model can adapt to new settings by simply incorporating the relevant semantic knowledge.
Technical Explanation
The paper proposes a language-vision model for zero-shot 3D object detection. The core idea is to leverage large language models, which have been shown to effectively encode semantic knowledge about the world, and combine this with a 3D point cloud recognition model.
Specifically, the authors use a pre-trained language model to generate a semantic descriptor for the concept of a "building". This descriptor is then used to guide the 3D object detection model, enabling it to identify building structures in the input point cloud data, without requiring any manually labeled training examples.
The [3D object detection model is trained in a weakly supervised fashion, using the language-derived building descriptor as the only supervisory signal. This allows the system to generalize to detecting buildings in new environments, without requiring manually annotated training data.
The experiments demonstrate the effectiveness of this approach, showing that the language-guided 3D detection model can accurately identify building structures in mobile LiDAR scans, despite being trained without any labeled examples.
Critical Analysis
The paper presents a promising approach for enabling zero-shot 3D object detection, which could have significant practical applications. However, the authors acknowledge several important limitations and avenues for further research.
One key constraint is that the performance of the system is still lower than that of fully supervised methods that use manually labeled training data. The authors suggest that incorporating additional language-based cues or improving the 3D detection model could help bridge this gap.
Additionally, the experiments are limited to a single object category (buildings) and a specific type of 3D data (mobile LiDAR). Further work is needed to evaluate the generalizability of the approach to a wider range of 3D object classes and data modalities.
Another potential concern is the reliance on pre-trained language models, which can sometimes exhibit biases or lack robustness. The authors do not extensively explore the sensitivity of their approach to the choice of language model or the quality of the semantic descriptors it provides.
Overall, this research represents an interesting step towards more flexible and data-efficient 3D perception systems. However, additional work is needed to fully realize the potential of language-guided 3D object detection in real-world applications.
Conclusion
This paper presents a novel approach for zero-shot detection of buildings in mobile LiDAR point cloud data, using a language-guided 3D object recognition model. By leveraging the semantic knowledge encoded in large language models, the system can identify building structures without requiring any manually labeled training examples.
The authors demonstrate the effectiveness of this approach through experiments on mobile LiDAR scans, showing that the language-vision model can accurately detect buildings despite being trained in a weakly supervised manner. This zero-shot capability could enable rapid deployment of 3D perception systems in new environments or applications, without the need for time-consuming data annotation.
While the current performance is still below that of fully supervised methods, the proposed approach represents an important step towards more flexible and data-efficient 3D object detection. Further research is needed to explore the generalizability of the technique to a wider range of object categories and data modalities, as well as to address any potential biases or limitations of the underlying language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
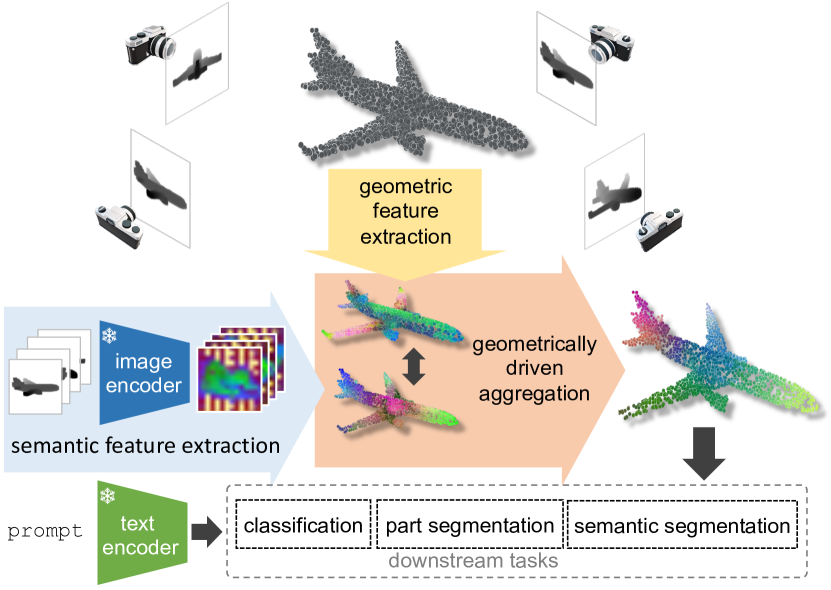
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
0
0
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
4/16/2024

Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
0
0
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
4/11/2024
🤔
Language-Image Models with 3D Understanding
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krahenbuhl, Yan Wang, Marco Pavone
0
0
Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
5/7/2024
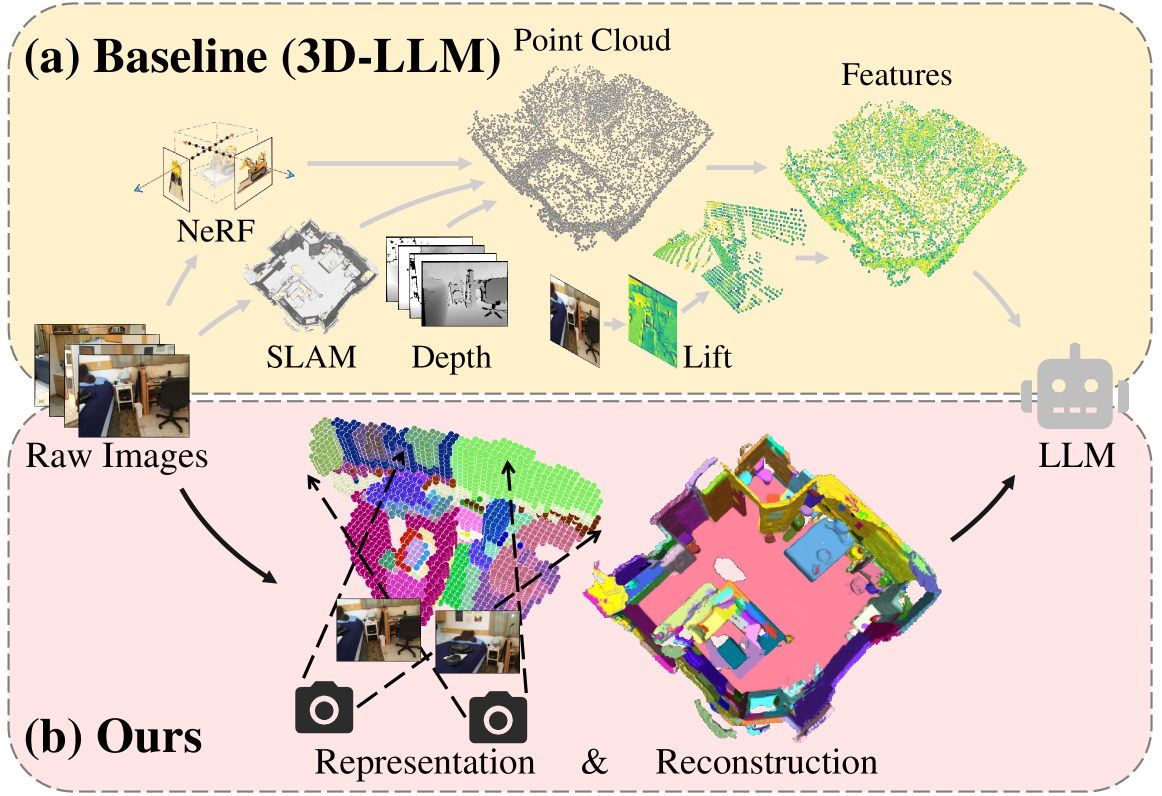
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
0
0
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
4/22/2024