Ontology-driven Reinforcement Learning for Personalized Student Support

0
Sign in to get full access
Overview
- This paper explores the use of ontology-driven reinforcement learning to provide personalized student support in educational settings.
- The researchers developed an approach that combines domain knowledge encoded in an ontology with reinforcement learning to tailor instructional strategies to individual students' needs.
- The goal is to create an intelligent tutoring system that can dynamically adapt its teaching methods to help each student learn more effectively.
Plain English Explanation
The researchers in this study wanted to create a smarter way for computers to teach students. They used a technique called reinforcement learning, which is a type of machine learning where the computer learns by getting feedback on its actions. The computer tries different teaching strategies and learns which ones work best for each individual student.
To make the reinforcement learning more effective, the researchers also incorporated an ontology. An ontology is a way of organizing and defining the key concepts and relationships in a particular domain, in this case, education. By including this domain knowledge, the computer can better understand the subject matter and tailor its teaching methods accordingly.
The idea is to develop an intelligent tutoring system that can dynamically adjust its approach based on how each student is responding. Just like a human tutor might change their teaching style to best suit a student's needs, this system aims to provide personalized support to help every student learn and succeed.
Technical Explanation
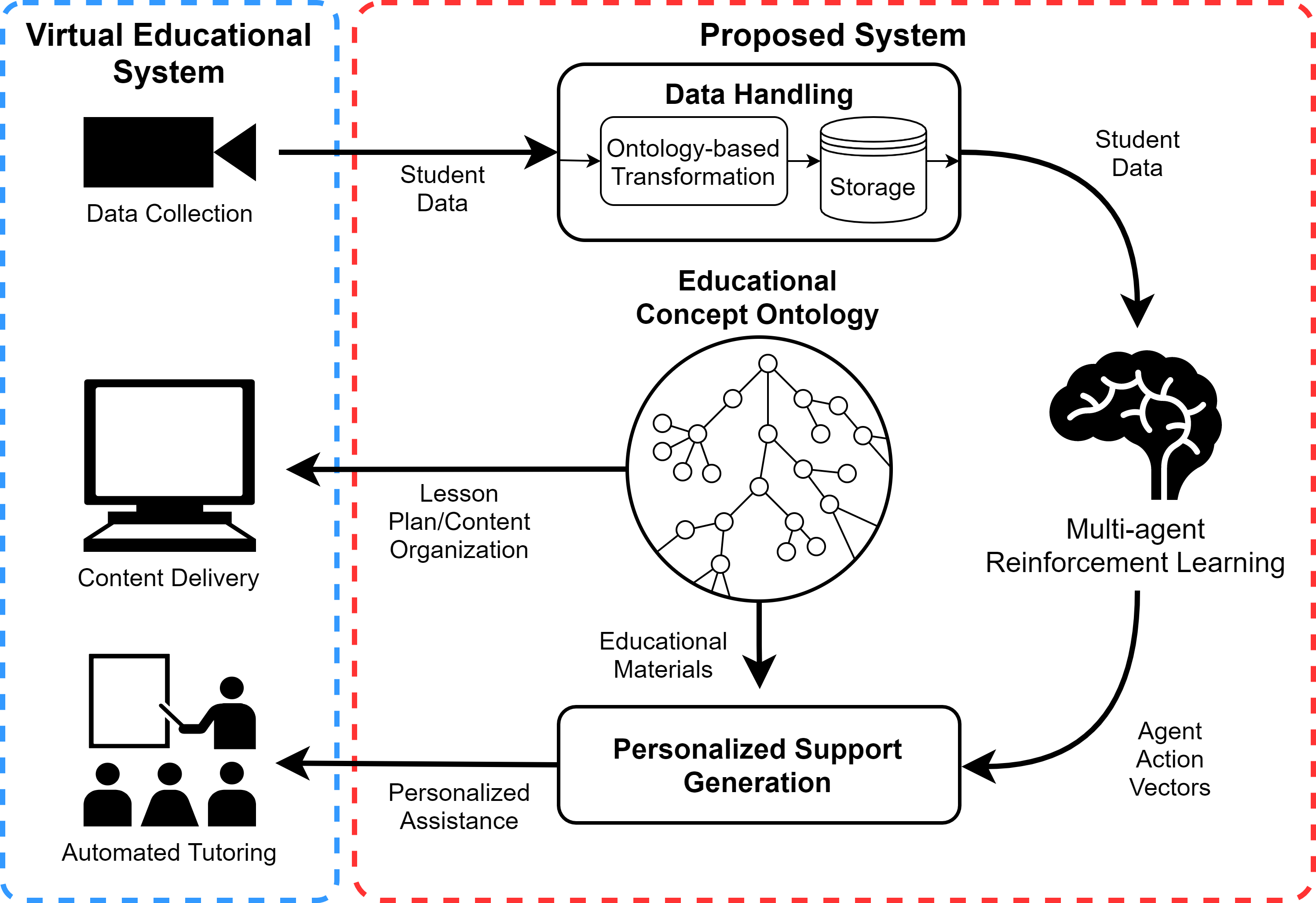
The core of the researchers' approach is an ontology-driven reinforcement learning framework for student support. They start by defining an ontology that captures the key concepts, relationships, and constraints in the educational domain. This includes things like learning objectives, instructional strategies, student attributes, and performance metrics.
They then use this ontology to guide the reinforcement learning process. The agent (i.e., the tutoring system) selects teaching actions based not only on the student's current state and performance, but also on the semantic knowledge encoded in the ontology. This allows the agent to reason about the pedagogical implications of its decisions and choose actions that are more likely to help the student achieve their learning goals.
The researchers evaluated their approach in a simulation environment that models student-tutor interactions. They showed that the ontology-driven reinforcement learning agent outperformed a baseline reinforcement learning agent that did not have access to the ontological knowledge.
Critical Analysis
One of the key strengths of this research is the integration of domain knowledge (in the form of an ontology) with reinforcement learning. This allows the system to make more informed and pedagogically-grounded decisions, rather than relying solely on trial-and-error learning.
However, the researchers acknowledge that their evaluation was limited to a simulated environment. Deploying such a system in a real-world educational setting would likely introduce additional challenges, such as dealing with noisy or incomplete student data, managing student privacy and consent, and aligning the system's objectives with broader educational goals.
Additionally, the researchers do not discuss potential biases or fairness issues that could arise from such a personalized tutoring system. There is a risk that the system could perpetuate or even exacerbate existing inequities in education if not designed and deployed carefully.
Further research is needed to address these practical and ethical considerations, as well as to explore the long-term impacts of ontology-driven reinforcement learning on student learning and engagement.
Conclusion
This paper presents a promising approach for developing personalized student support systems using ontology-driven reinforcement learning. By combining domain knowledge with adaptive learning algorithms, the researchers aim to create intelligent tutoring systems that can dynamically tailor their instructional strategies to the needs of individual students.
While the results from the simulated environment are encouraging, there are still many challenges to overcome before such a system could be deployed in real-world educational settings. Nonetheless, this research represents an important step towards more effective and equitable personalized learning technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ontology-driven Reinforcement Learning for Personalized Student Support
Ryan Hare, Ying Tang
In the search for more effective education, there is a widespread effort to develop better approaches to personalize student education. Unassisted, educators often do not have time or resources to personally support every student in a given classroom. Motivated by this issue, and by recent advancements in artificial intelligence, this paper presents a general-purpose framework for personalized student support, applicable to any virtual educational system such as a serious game or an intelligent tutoring system. To fit any educational situation, we apply ontologies for their semantic organization, combining them with data collection considerations and multi-agent reinforcement learning. The result is a modular system that can be adapted to any virtual educational software to provide useful personalized assistance to students.
Read more9/6/2024

0
EduAgent: Generative Student Agents in Learning
Songlin Xu, Xinyu Zhang, Lianhui Qin
Student simulation in online education is important to address dynamic learning behaviors of students with diverse backgrounds. Existing simulation models based on deep learning usually need massive training data, lacking prior knowledge in educational contexts. Large language models (LLMs) may contain such prior knowledge since they are pre-trained from a large corpus. However, because student behaviors are dynamic and multifaceted with individual differences, directly prompting LLMs is not robust nor accurate enough to capture fine-grained interactions among diverse student personas, learning behaviors, and learning outcomes. This work tackles this problem by presenting a newly annotated fine-grained large-scale dataset and proposing EduAgent, a novel generative agent framework incorporating cognitive prior knowledge (i.e., theoretical findings revealed in cognitive science) to guide LLMs to first reason correlations among various behaviors and then make simulations. Our two experiments show that EduAgent could not only mimic and predict learning behaviors of real students but also generate realistic learning behaviors of virtual students without real data.
Read more4/12/2024
0
AI and personalized learning: bridging the gap with modern educational goals
Kristjan-Julius Laak, Jaan Aru
Personalized learning (PL) aspires to provide an alternative to the one-size-fits-all approach in education. Technology-based PL solutions have shown notable effectiveness in enhancing learning performance. However, their alignment with the broader goals of modern education is inconsistent across technologies and research areas. In this paper, we examine the characteristics of AI-driven PL solutions in light of the OECD Learning Compass 2030 goals. Our analysis indicates a gap between the objectives of modern education and the current direction of PL. We identify areas where most present-day PL technologies could better embrace essential elements of contemporary education, such as collaboration, cognitive engagement, and the development of general competencies. While the present PL solutions are instrumental in aiding learning processes, the PL envisioned by educational experts extends beyond simple technological tools and requires a holistic change in the educational system. Finally, we explore the potential of large language models, such as ChatGPT, and propose a hybrid model that blends artificial intelligence with a collaborative, teacher-facilitated approach to personalized learning.
Read more4/4/2024
🤔
0
Learning Personalized Decision Support Policies
Umang Bhatt, Valerie Chen, Katherine M. Collins, Parameswaran Kamalaruban, Emma Kallina, Adrian Weller, Ameet Talwalkar
Individual human decision-makers may benefit from different forms of support to improve decision outcomes, but when each form of support will yield better outcomes? In this work, we posit that personalizing access to decision support tools can be an effective mechanism for instantiating the appropriate use of AI assistance. Specifically, we propose the general problem of learning a decision support policy that, for a given input, chooses which form of support to provide to decision-makers for whom we initially have no prior information. We develop $texttt{Modiste}$, an interactive tool to learn personalized decision support policies. $texttt{Modiste}$ leverages stochastic contextual bandit techniques to personalize a decision support policy for each decision-maker and supports extensions to the multi-objective setting to account for auxiliary objectives like the cost of support. We find that personalized policies outperform offline policies, and, in the cost-aware setting, reduce the incurred cost with minimal degradation to performance. Our experiments include various realistic forms of support (e.g., expert consensus and predictions from a large language model) on vision and language tasks. Our human subject experiments validate our computational experiments, demonstrating that personalization can yield benefits in practice for real users, who interact with $texttt{Modiste}$.
Read more5/28/2024