Learning Personalized Decision Support Policies

0
🤔
Sign in to get full access
Overview
- This paper explores how to personalize access to decision support tools to improve decision-making outcomes for individual users.
- The authors propose a general problem of learning a decision support policy that chooses the appropriate form of support for each user.
- They develop an interactive tool called Modiste that uses stochastic contextual bandit techniques to personalize the decision support policy.
- The experiments include various realistic forms of support, such as expert consensus and large language model predictions, and the authors validate their findings through human subject experiments.
Plain English Explanation
When individuals need to make decisions, different types of decision support tools can be helpful. For example, getting advice from experts, or using AI-powered predictions, could assist the decision-maker. However, the optimal type of support may vary from person to person.
The researchers in this paper propose a way to personalize the decision support provided to each individual. They develop an interactive tool called Modiste that learns which type of support works best for each user, based on the user's interactions with the tool.
Imagine you're trying to decide which college to attend. One person might benefit most from seeing predictions about their future career prospects from a large language model, while another person might prefer to get advice from a panel of experts in that field. Modiste learns the optimal type of support for each individual user, rather than providing the same support to everyone.
The researchers found that this personalized approach outperformed generic, one-size-fits-all decision support policies. They also showed that this personalized approach can balance performance with the cost of providing different types of support, reducing the overall cost while maintaining good decision outcomes.
Technical Explanation
The authors frame the problem as learning a "decision support policy" that, given a user and their current decision context, chooses the best form of decision support to provide. They develop Modiste, an interactive tool that uses stochastic contextual bandit techniques to personalize this decision support policy for each user.
In their experiments, the authors consider various realistic forms of decision support, such as:
- Expert consensus: aggregating the opinions of domain experts
- Large language model predictions: using a powerful AI model to generate predictions
They evaluate Modiste on both vision and language tasks, and also explore a "cost-aware" setting where the goal is to minimize the cost of the decision support provided while maintaining good decision outcomes.
The key finding is that the personalized decision support policies learned by Modiste outperform generic, offline policies. In the cost-aware setting, the personalized policies are able to reduce the incurred cost with minimal degradation to performance.
The authors also conduct human subject experiments, which validate their computational results and demonstrate the benefits of personalization for real users interacting with Modiste.
Critical Analysis
The paper presents a well-designed study that addresses an important problem of personalizing decision support tools. The authors have thoughtfully considered various realistic forms of decision support and explored the tradeoffs between performance and cost, which is a crucial practical consideration.
One potential limitation is the reliance on simulated decision tasks, which may not fully capture the nuances and complexities of real-world decision-making. While the human subject experiments help to validate the findings, further research with a more diverse set of decision scenarios and user populations would be valuable.
Additionally, the authors acknowledge that Modiste currently assumes the decision-maker has no prior information. Extending the approach to incorporate the user's existing knowledge and preferences could further improve the personalization capabilities.
It would also be interesting to explore how Modiste could be integrated with other human-AI collaboration techniques, such as white-box language models or optimizing human-centric objectives, to further enhance the decision-making process.
Conclusion
This paper presents an innovative approach to personalizing decision support tools, which can significantly improve decision-making outcomes for individual users. The Modiste tool developed by the researchers uses advanced techniques to learn the optimal form of decision support for each user, and the results demonstrate the benefits of this personalized approach.
As AI systems become more prevalent in supporting human decision-making, this work highlights the importance of tailoring these tools to individual users' needs and preferences. By doing so, we can harness the power of AI to enhance, rather than replace, human decision-making, ultimately leading to better outcomes for individuals and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Learning Personalized Decision Support Policies
Umang Bhatt, Valerie Chen, Katherine M. Collins, Parameswaran Kamalaruban, Emma Kallina, Adrian Weller, Ameet Talwalkar
Individual human decision-makers may benefit from different forms of support to improve decision outcomes, but when each form of support will yield better outcomes? In this work, we posit that personalizing access to decision support tools can be an effective mechanism for instantiating the appropriate use of AI assistance. Specifically, we propose the general problem of learning a decision support policy that, for a given input, chooses which form of support to provide to decision-makers for whom we initially have no prior information. We develop $texttt{Modiste}$, an interactive tool to learn personalized decision support policies. $texttt{Modiste}$ leverages stochastic contextual bandit techniques to personalize a decision support policy for each decision-maker and supports extensions to the multi-objective setting to account for auxiliary objectives like the cost of support. We find that personalized policies outperform offline policies, and, in the cost-aware setting, reduce the incurred cost with minimal degradation to performance. Our experiments include various realistic forms of support (e.g., expert consensus and predictions from a large language model) on vision and language tasks. Our human subject experiments validate our computational experiments, demonstrating that personalization can yield benefits in practice for real users, who interact with $texttt{Modiste}$.
Read more5/28/2024
0
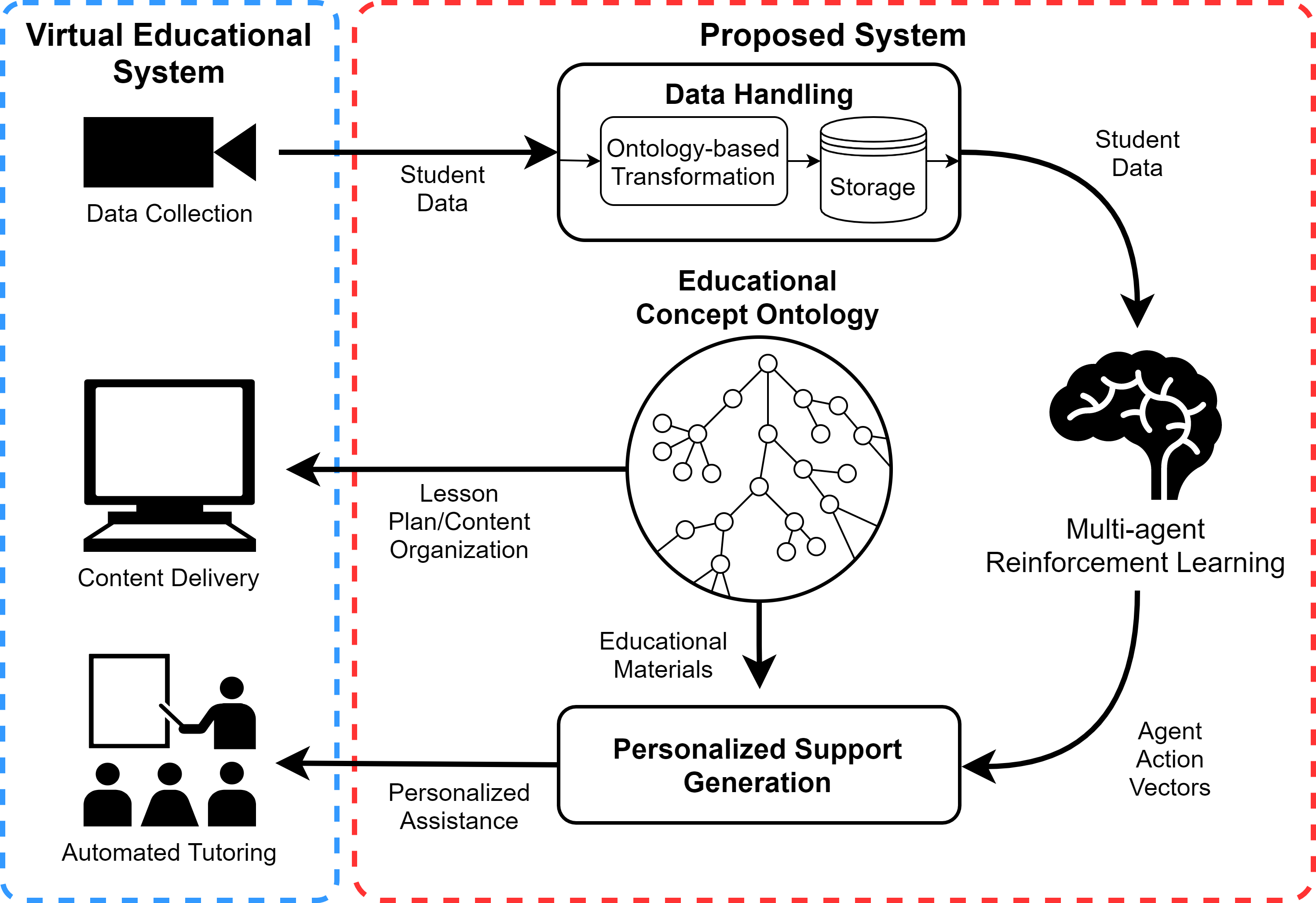
Ontology-driven Reinforcement Learning for Personalized Student Support
Ryan Hare, Ying Tang
In the search for more effective education, there is a widespread effort to develop better approaches to personalize student education. Unassisted, educators often do not have time or resources to personally support every student in a given classroom. Motivated by this issue, and by recent advancements in artificial intelligence, this paper presents a general-purpose framework for personalized student support, applicable to any virtual educational system such as a serious game or an intelligent tutoring system. To fit any educational situation, we apply ontologies for their semantic organization, combining them with data collection considerations and multi-agent reinforcement learning. The result is a modular system that can be adapted to any virtual educational software to provide useful personalized assistance to students.
Read more9/6/2024
0
Leveraging automatic strategy discovery to teach people how to select better projects
Lovis Heindrich, Falk Lieder
The decisions of individuals and organizations are often suboptimal because normative decision strategies are too demanding in the real world. Recent work suggests that some errors can be prevented by leveraging artificial intelligence to discover and teach prescriptive decision strategies that take people's constraints into account. So far, this line of research has been limited to simplified decision problems. This article is the first to extend this approach to a real-world decision problem, namely project selection. We develop a computational method (MGPS) that automatically discovers project selection strategies that are optimized for real people and develop an intelligent tutor that teaches the discovered strategies. We evaluated MGPS on a computational benchmark and tested the intelligent tutor in a training experiment with two control conditions. MGPS outperformed a state-of-the-art method and was more computationally efficient. Moreover, the intelligent tutor significantly improved people's decision strategies. Our results indicate that our method can improve human decision-making in naturalistic settings similar to real-world project selection, a first step towards applying strategy discovery to the real world.
Read more6/7/2024

0
Contextualized Policy Recovery: Modeling and Interpreting Medical Decisions with Adaptive Imitation Learning
Jannik Deuschel, Caleb N. Ellington, Yingtao Luo, Benjamin J. Lengerich, Pascal Friederich, Eric P. Xing
Interpretable policy learning seeks to estimate intelligible decision policies from observed actions; however, existing models force a tradeoff between accuracy and interpretability, limiting data-driven interpretations of human decision-making processes. Fundamentally, existing approaches are burdened by this tradeoff because they represent the underlying decision process as a universal policy, when in fact human decisions are dynamic and can change drastically under different contexts. Thus, we develop Contextualized Policy Recovery (CPR), which re-frames the problem of modeling complex decision processes as a multi-task learning problem, where each context poses a unique task and complex decision policies can be constructed piece-wise from many simple context-specific policies. CPR models each context-specific policy as a linear map, and generates new policy models $textit{on-demand}$ as contexts are updated with new observations. We provide two flavors of the CPR framework: one focusing on exact local interpretability, and one retaining full global interpretability. We assess CPR through studies on simulated and real data, achieving state-of-the-art performance on predicting antibiotic prescription in intensive care units ($+22%$ AUROC vs. previous SOTA) and predicting MRI prescription for Alzheimer's patients ($+7.7%$ AUROC vs. previous SOTA). With this improvement, CPR closes the accuracy gap between interpretable and black-box methods, allowing high-resolution exploration and analysis of context-specific decision models.
Read more5/9/2024