OP-Align: Object-level and Part-level Alignment for Self-supervised Category-level Articulated Object Pose Estimation

0

Sign in to get full access
Overview
- This paper presents OP-Align, a self-supervised framework for category-level articulated object pose estimation.
- OP-Align aligns object-level and part-level 3D representations to learn a category-level pose estimator without explicit 3D supervision.
- The method can handle complex articulated objects and does not require any 3D annotations during training.
Plain English Explanation
OP-Align is a new technique for teaching computers to estimate the 3D pose of articulated objects, such as chairs, laptops, or robots. Traditionally, this kind of 3D object pose estimation has required providing the computer with lots of labeled 3D data during training.
OP-Align takes a different approach. Instead of relying on 3D labels, it uses an unsupervised learning technique to figure out the 3D pose of articulated objects on its own. The key idea is to align the 3D representations of the
This is a powerful approach because it means OP-Align can be used to estimate the 3D pose of a wide variety of articulated objects, without the need to manually label lots of 3D data for each type of object. The method can handle complex, articulated objects that have multiple moving parts, which is an important capability for applications like robotics and augmented reality.
Technical Explanation
OP-Align consists of two key components:
The object-level alignment module learns to map 2D images of articulated objects to a shared 3D object-level latent space. This allows the model to reason about the 3D structure and pose of the entire object, even for unseen object instances.
The part-level alignment module then learns to map the individual parts of the object (e.g. the legs of a chair) to a shared part-level latent space. By aligning the part-level and object-level representations, the model can infer the relative 3D pose of the object parts.
During training, OP-Align uses self-supervision signals, such as 2D keypoint annotations and multi-view consistency, to learn these object-level and part-level alignments without any 3D ground truth data.
The authors demonstrate that OP-Align can effectively estimate the 3D pose of a wide range of articulated objects, outperforming previous unsupervised methods on standard benchmarks.
Critical Analysis
The key strength of OP-Align is its ability to learn 3D pose estimation in a self-supervised manner, without requiring any 3D ground truth data. This is an important advance, as collecting and annotating 3D data for a wide range of articulated objects can be extremely challenging and time-consuming.
However, the paper does note some limitations. First, the method relies on the availability of 2D keypoint annotations, which may not always be easy to obtain. Additionally, the part-level alignment module may struggle with objects that have a large number of parts or complex part arrangements.
Further research could explore ways to reduce the reliance on 2D keypoint supervision, perhaps by incorporating other self-supervised signals. Investigating how OP-Align performs on a broader range of articulated objects, including those with more complex structures, would also be valuable.
Conclusion
OP-Align presents a promising approach for learning category-level 3D pose estimation of articulated objects in a self-supervised manner. By aligning object-level and part-level representations, the method can infer the 3D pose of unseen object instances without any 3D ground truth data. This is an important step towards more scalable and flexible 3D object pose estimation, with potential applications in areas like robotics, augmented reality, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OP-Align: Object-level and Part-level Alignment for Self-supervised Category-level Articulated Object Pose Estimation
Yuchen Che, Ryo Furukawa, Asako Kanezaki
Category-level articulated object pose estimation focuses on the pose estimation of unknown articulated objects within known categories. Despite its significance, this task remains challenging due to the varying shapes and poses of objects, expensive dataset annotation costs, and complex real-world environments. In this paper, we propose a novel self-supervised approach that leverages a single-frame point cloud to solve this task. Our model consistently generates reconstruction with a canonical pose and joint state for the entire input object, and it estimates object-level poses that reduce overall pose variance and part-level poses that align each part of the input with its corresponding part of the reconstruction. Experimental results demonstrate that our approach significantly outperforms previous self-supervised methods and is comparable to the state-of-the-art supervised methods. To assess the performance of our model in real-world scenarios, we also introduce a new real-world articulated object benchmark dataset.
Read more8/30/2024

0
Unsupervised Learning of Category-Level 3D Pose from Object-Centric Videos
Leonhard Sommer, Artur Jesslen, Eddy Ilg, Adam Kortylewski
Category-level 3D pose estimation is a fundamentally important problem in computer vision and robotics, e.g. for embodied agents or to train 3D generative models. However, so far methods that estimate the category-level object pose require either large amounts of human annotations, CAD models or input from RGB-D sensors. In contrast, we tackle the problem of learning to estimate the category-level 3D pose only from casually taken object-centric videos without human supervision. We propose a two-step pipeline: First, we introduce a multi-view alignment procedure that determines canonical camera poses across videos with a novel and robust cyclic distance formulation for geometric and appearance matching using reconstructed coarse meshes and DINOv2 features. In a second step, the canonical poses and reconstructed meshes enable us to train a model for 3D pose estimation from a single image. In particular, our model learns to estimate dense correspondences between images and a prototypical 3D template by predicting, for each pixel in a 2D image, a feature vector of the corresponding vertex in the template mesh. We demonstrate that our method outperforms all baselines at the unsupervised alignment of object-centric videos by a large margin and provides faithful and robust predictions in-the-wild. Our code and data is available at https://github.com/GenIntel/uns-obj-pose3d.
Read more7/8/2024
0
Learning a Category-level Object Pose Estimator without Pose Annotations
Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
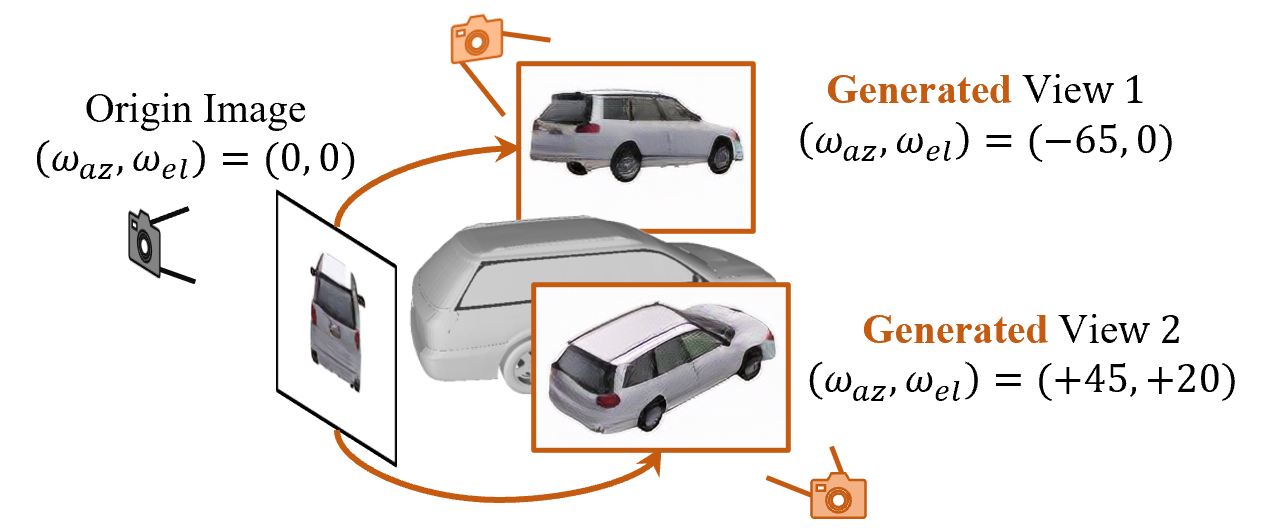
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
Read more4/9/2024
🤿
0
Deep Learning-Based Object Pose Estimation: A Comprehensive Survey
Jian Liu, Wei Sun, Hui Yang, Zhiwen Zeng, Chongpei Liu, Jin Zheng, Xingyu Liu, Hossein Rahmani, Nicu Sebe, Ajmal Mian
Object pose estimation is a fundamental computer vision problem with broad applications in augmented reality and robotics. Over the past decade, deep learning models, due to their superior accuracy and robustness, have increasingly supplanted conventional algorithms reliant on engineered point pair features. Nevertheless, several challenges persist in contemporary methods, including their dependency on labeled training data, model compactness, robustness under challenging conditions, and their ability to generalize to novel unseen objects. A recent survey discussing the progress made on different aspects of this area, outstanding challenges, and promising future directions, is missing. To fill this gap, we discuss the recent advances in deep learning-based object pose estimation, covering all three formulations of the problem, emph{i.e.}, instance-level, category-level, and unseen object pose estimation. Our survey also covers multiple input data modalities, degrees-of-freedom of output poses, object properties, and downstream tasks, providing the readers with a holistic understanding of this field. Additionally, it discusses training paradigms of different domains, inference modes, application areas, evaluation metrics, and benchmark datasets, as well as reports the performance of current state-of-the-art methods on these benchmarks, thereby facilitating the readers in selecting the most suitable method for their application. Finally, the survey identifies key challenges, reviews the prevailing trends along with their pros and cons, and identifies promising directions for future research. We also keep tracing the latest works at https://github.com/CNJianLiu/Awesome-Object-Pose-Estimation.
Read more6/3/2024