Learning a Category-level Object Pose Estimator without Pose Annotations
2404.05626
0
0
Abstract
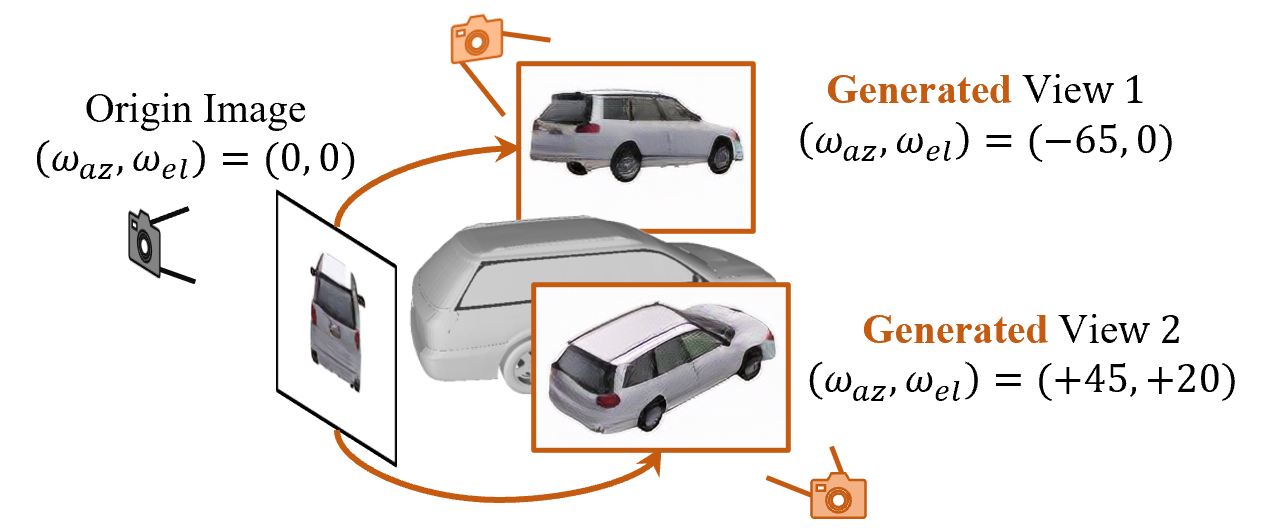
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
Create account to get full access
Overview
- This paper presents a novel approach to learning a category-level object pose estimator without requiring any pose annotations during training.
- The method leverages self-supervised learning and geometric constraints to estimate the 6D poses of objects from a given category, without the need for manually labeled pose data.
- This is a significant advancement over previous methods that required extensive manual labeling of object poses, which is a time-consuming and costly process.
Plain English Explanation
The paper describes a new way to teach a computer system how to estimate the 3D position and orientation (6D pose) of objects belonging to a specific category, without the need for extensive human-labeled training data.
Previous approaches required researchers to manually label the poses of many individual objects, which is a tedious and labor-intensive task. This new method instead uses self-supervised learning techniques and geometric constraints to allow the system to learn the object poses on its own, without any manually labeled pose data.
The key idea is to leverage the inherent 3D structure and geometric properties of objects within a category to infer their poses, rather than relying on explicitly labeled training data. This makes the pose estimation process much more efficient and scalable, as it eliminates the need for the costly and time-consuming manual labeling step.
By automating this process, the researchers hope to enable more widespread deployment of 6D pose estimation systems, which have many important applications in areas like robotics, augmented reality, and 3D scene understanding.
Technical Explanation
The paper introduces a self-supervised learning approach to 6D object pose estimation that does not require any manually annotated pose data during training.
The key innovation is the use of geometric constraints to learn a category-level pose estimator. Specifically, the method leverages the known 3D shape of object categories to derive self-supervisory signals for training a neural network to predict the 6D poses of instances from those categories.
The training process involves two main steps:
-
Pose Initialization: First, the system initializes the pose of each training object instance by aligning its 3D shape model to the observed 2D image using a freeze-train-free approach.
-
Pose Refinement: Next, the initialized poses are further refined by enforcing consistency between the predicted 2D projections of the 3D shape model and the observed 2D image features, using a differentiable rendering-based loss.
By iterating between these two steps, the system is able to learn a category-level 6D pose estimator without any manual pose annotations, leveraging only the 3D shape models and 2D image data.
Critical Analysis
The proposed approach represents a significant advancement in 6D object pose estimation, as it eliminates the need for the costly and time-consuming manual labeling of pose data. This is a notable achievement, as the availability of such labeled data has been a major bottleneck in deploying pose estimation systems in real-world applications.
However, the paper does acknowledge some limitations of the method. For example, the approach relies on the availability of accurate 3D shape models for the object categories of interest, which may not always be readily available. Additionally, the method may struggle with highly occluded or truncated objects, where the geometric constraints are less effective.
Further research could explore ways to relax these assumptions, such as by incorporating salient visual cues or leveraging open-vocabulary knowledge to enable pose estimation in more challenging scenarios.
Conclusion
This paper presents a novel approach to category-level 6D object pose estimation that eliminates the need for manually annotated pose data during training. By exploiting geometric constraints and self-supervised learning, the method can learn effective pose estimators using only 3D shape models and 2D image data.
This is a significant advancement that has the potential to enable more widespread deployment of 6D pose estimation systems in a variety of real-world applications, such as robotics, augmented reality, and 3D scene understanding. While the method has some limitations, the insights and techniques introduced in this work represent an important step forward in the field of object pose estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Learning-Based Object Pose Estimation: A Comprehensive Survey
Jian Liu, Wei Sun, Hui Yang, Zhiwen Zeng, Chongpei Liu, Jin Zheng, Xingyu Liu, Hossein Rahmani, Nicu Sebe, Ajmal Mian
0
0
Object pose estimation is a fundamental computer vision problem with broad applications in augmented reality and robotics. Over the past decade, deep learning models, due to their superior accuracy and robustness, have increasingly supplanted conventional algorithms reliant on engineered point pair features. Nevertheless, several challenges persist in contemporary methods, including their dependency on labeled training data, model compactness, robustness under challenging conditions, and their ability to generalize to novel unseen objects. A recent survey discussing the progress made on different aspects of this area, outstanding challenges, and promising future directions, is missing. To fill this gap, we discuss the recent advances in deep learning-based object pose estimation, covering all three formulations of the problem, emph{i.e.}, instance-level, category-level, and unseen object pose estimation. Our survey also covers multiple input data modalities, degrees-of-freedom of output poses, object properties, and downstream tasks, providing the readers with a holistic understanding of this field. Additionally, it discusses training paradigms of different domains, inference modes, application areas, evaluation metrics, and benchmark datasets, as well as reports the performance of current state-of-the-art methods on these benchmarks, thereby facilitating the readers in selecting the most suitable method for their application. Finally, the survey identifies key challenges, reviews the prevailing trends along with their pros and cons, and identifies promising directions for future research. We also keep tracing the latest works at https://github.com/CNJianLiu/Awesome-Object-Pose-Estimation.
6/3/2024
Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
Weiguang Zhao, Guanyu Yang, Rui Zhang, Chenru Jiang, Chaolong Yang, Yuyao Yan, Amir Hussain, Kaizhu Huang
0
0
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
4/17/2024

Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses
Seungwoo Yoo, Juil Koo, Kyeongmin Yeo, Minhyuk Sung
0
0
We propose a novel method for learning representations of poses for 3D deformable objects, which specializes in 1) disentangling pose information from the object's identity, 2) facilitating the learning of pose variations, and 3) transferring pose information to other object identities. Based on these properties, our method enables the generation of 3D deformable objects with diversity in both identities and poses, using variations of a single object. It does not require explicit shape parameterization such as skeletons or joints, point-level or shape-level correspondence supervision, or variations of the target object for pose transfer. To achieve pose disentanglement, compactness for generative models, and transferability, we first design the pose extractor to represent the pose as a keypoint-based hybrid representation and the pose applier to learn an implicit deformation field. To better distill pose information from the object's geometry, we propose the implicit pose applier to output an intrinsic mesh property, the face Jacobian. Once the extracted pose information is transferred to the target object, the pose applier is fine-tuned in a self-supervised manner to better describe the target object's shapes with pose variations. The extracted poses are also used to train a cascaded diffusion model to enable the generation of novel poses. Our experiments with the DeformThings4D and Human datasets demonstrate state-of-the-art performance in pose transfer and the ability to generate diverse deformed shapes with various objects and poses.
6/17/2024
👀
FreeZe: Training-free zero-shot 6D pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, Fabio Poiesi
0
0
Estimating the 6D pose of objects unseen during training is highly desirable yet challenging. Zero-shot object 6D pose estimation methods address this challenge by leveraging additional task-specific supervision provided by large-scale, photo-realistic synthetic datasets. However, their performance heavily depends on the quality and diversity of rendered data and they require extensive training. In this work, we show how to tackle the same task but without training on specific data. We propose FreeZe, a novel solution that harnesses the capabilities of pre-trained geometric and vision foundation models. FreeZe leverages 3D geometric descriptors learned from unrelated 3D point clouds and 2D visual features learned from web-scale 2D images to generate discriminative 3D point-level descriptors. We then estimate the 6D pose of unseen objects by 3D registration based on RANSAC. We also introduce a novel algorithm to solve ambiguous cases due to geometrically symmetric objects that is based on visual features. We comprehensively evaluate FreeZe across the seven core datasets of the BOP Benchmark, which include over a hundred 3D objects and 20,000 images captured in various scenarios. FreeZe consistently outperforms all state-of-the-art approaches, including competitors extensively trained on synthetic 6D pose estimation data. Code will be publicly available at https://andreacaraffa.github.io/freeze.
4/4/2024