Open (Clinical) LLMs are Sensitive to Instruction Phrasings

0
Sign in to get full access
Overview
- Examines the sensitivity of open (clinical) large language models (LLMs) to how instructions are phrased
- Explores how instruction phrasing can impact the outputs and behaviors of these models
- Highlights the importance of carefully crafting prompts and instructions when using open (clinical) LLMs
Plain English Explanation
This paper investigates how the way instructions are phrased can affect the responses of open (clinical) large language models (LLMs) - powerful AI systems trained on vast amounts of text data. The researchers found that these models can be quite sensitive to subtle differences in how instructions are worded.
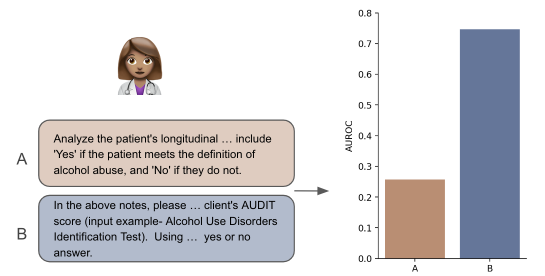
For example, asking an open (clinical) LLM to "summarize the key points" of a medical report might yield different results than asking it to "list the main takeaways." The phrasing of the request can shape the model's output in significant ways. This has important implications for using these models in real-world applications, like clinical decision support systems, where the accuracy and reliability of the model's responses are critical.
The paper highlights the need to carefully craft prompts and instructions when working with open (clinical) LLMs, as small changes in wording can lead to meaningful differences in the models' behaviors and outputs. This aligns with other research on instruction-tuning and prompt engineering for these powerful language models.
Technical Explanation
The researchers conducted a series of experiments to assess the sensitivity of open (clinical) LLMs to instruction phrasing. They used a variety of LLMs, including those fine-tuned on medical and clinical data, and presented the models with different prompts and instructions related to summarizing and analyzing medical reports.
The results showed that subtle changes in the wording of instructions could lead to significant differences in the models' outputs. For example, asking the model to "summarize the key points" resulted in more concise, high-level summaries, while asking it to "list the main takeaways" often yielded more detailed, granular responses.
The researchers also found that the degree of sensitivity varied across different LLMs, with some models demonstrating greater robustness to instruction phrasing than others. This suggests that the architectural design and training data of these models can play a role in their sensitivity to prompt wording.
These findings build on previous work on zero-shot and few-shot learning with LLMs, as well as research on instruction-tuning and prompt engineering for these powerful language models.
Critical Analysis
The paper provides valuable insights into the sensitivity of open (clinical) LLMs to instruction phrasing, highlighting the importance of carefully crafting prompts and instructions when using these models in real-world applications. However, the research is limited to a specific set of LLMs and medical/clinical tasks, and it would be useful to see the findings extended to a broader range of models and use cases.
Additionally, the paper does not delve deeply into the underlying mechanisms driving the models' sensitivity to instruction phrasing. Further research is needed to understand the cognitive and architectural factors that contribute to this phenomenon, which could inform the development of more robust and reliable LLMs for sensitive applications.
It's also worth noting that the paper does not address potential biases or ethical considerations associated with the use of open (clinical) LLMs in clinical settings. As these models become more widely adopted, it will be crucial to continue investigating their limitations and potential risks to ensure they are deployed responsibly and safely.
Conclusion
This paper demonstrates the sensitivity of open (clinical) large language models to the phrasing of instructions, highlighting the need for careful prompt engineering when using these powerful AI systems. The findings have important implications for the development and deployment of LLMs in real-world applications, particularly in sensitive domains like healthcare, where the accuracy and reliability of the models' outputs are critical.
The research underscores the importance of continued exploration and understanding of the capabilities and limitations of open (clinical) LLMs, as the field of large language model research continues to evolve rapidly. By addressing these issues proactively, researchers and practitioners can help ensure that these transformative technologies are leveraged responsibly and in service of the greater good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open (Clinical) LLMs are Sensitive to Instruction Phrasings
Alberto Mario Ceballos Arroyo, Monica Munnangi, Jiuding Sun, Karen Y. C. Zhang, Denis Jered McInerney, Byron C. Wallace, Silvio Amir
Instruction-tuned Large Language Models (LLMs) can perform a wide range of tasks given natural language instructions to do so, but they are sensitive to how such instructions are phrased. This issue is especially concerning in healthcare, as clinicians are unlikely to be experienced prompt engineers and the potential consequences of inaccurate outputs are heightened in this domain. This raises a practical question: How robust are instruction-tuned LLMs to natural variations in the instructions provided for clinical NLP tasks? We collect prompts from medical doctors across a range of tasks and quantify the sensitivity of seven LLMs -- some general, others specialized -- to natural (i.e., non-adversarial) instruction phrasings. We find that performance varies substantially across all models, and that -- perhaps surprisingly -- domain-specific models explicitly trained on clinical data are especially brittle, compared to their general domain counterparts. Further, arbitrary phrasing differences can affect fairness, e.g., valid but distinct instructions for mortality prediction yield a range both in overall performance, and in terms of differences between demographic groups.
Read more7/15/2024
💬
0
Instruction-tuned Large Language Models for Machine Translation in the Medical Domain
Miguel Rios
Large Language Models (LLMs) have shown promising results on machine translation for high resource language pairs and domains. However, in specialised domains (e.g. medical) LLMs have shown lower performance compared to standard neural machine translation models. The consistency in the machine translation of terminology is crucial for users, researchers, and translators in specialised domains. In this study, we compare the performance between baseline LLMs and instruction-tuned LLMs in the medical domain. In addition, we introduce terminology from specialised medical dictionaries into the instruction formatted datasets for fine-tuning LLMs. The instruction-tuned LLMs significantly outperform the baseline models with automatic metrics.
Read more8/30/2024
💬
0
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
Read more6/11/2024
💬
0
Optimizing Psychological Counseling with Instruction-Tuned Large Language Models
Wenjie Li, Tianyu Sun, Kun Qian, Wenhong Wang
The advent of large language models (LLMs) has significantly advanced various fields, including natural language processing and automated dialogue systems. This paper explores the application of LLMs in psychological counseling, addressing the increasing demand for mental health services. We present a method for instruction tuning LLMs with specialized prompts to enhance their performance in providing empathetic, relevant, and supportive responses. Our approach involves developing a comprehensive dataset of counseling-specific prompts, refining them through feedback from professional counselors, and conducting rigorous evaluations using both automatic metrics and human assessments. The results demonstrate that our instruction-tuned model outperforms several baseline LLMs, highlighting its potential as a scalable and accessible tool for mental health support.
Read more6/21/2024