Open-Ended Multi-Modal Relational Reasoning for Video Question Answering

0
🤿
Sign in to get full access
Overview
- This paper introduces a robotic agent designed to analyze external environments and assist users through language-based interactions within video-based scenes.
- The agent integrates video recognition technology and natural language processing models to support human-robot interactions.
- The researchers investigate factors affecting trust and interaction efficiency between participants and the robotic agent.
- Their experimental findings demonstrate a 2-3% performance enhancement compared to other benchmark methods.
Plain English Explanation
The researchers have developed a robotic assistant that can analyze video scenes and respond to users' questions using natural language. This robot combines computer vision and language processing capabilities to interact with people and help them understand the video content.
The key focus of this work is to explore how humans and this robot can work together effectively. The researchers looked at factors like trust and efficiency to see how well the robot performs compared to other approaches. They found that their robot outperforms other benchmarks by a small but meaningful margin, suggesting it could be a useful tool for analyzing and understanding video data through conversational interactions.
Technical Explanation
The researchers have created a robotic agent that integrates video recognition technology and natural language processing to assist users within video-based scenes. The agent is designed to engage in language-based interactions, drawing on techniques from the WorldQA and iterative search reasoning approaches.
Through experimental evaluation, the researchers investigate key factors that influence the quality of human-robot interactions, focusing on aspects such as trust and interaction efficiency. Their findings reveal a positive correlation between trust and interaction performance, with their proposed model demonstrating a 2-3% improvement over other benchmark methods in this area.
Critical Analysis
The paper provides a promising approach to developing robotic agents that can effectively assist users in understanding and engaging with video content through natural language interactions. However, the researchers acknowledge that their study has some limitations. For example, they note that their experiments were conducted in controlled settings, and further research is needed to assess the robotic agent's performance in more realistic, uncontrolled environments.
Additionally, while the performance improvement over benchmark methods is noteworthy, the modest 2-3% margin suggests that there is still room for significant advancement in this area. Exploring ways to further enhance the agent's capabilities, such as through closed-loop interactive embodied reasoning, could be a valuable direction for future research.
Conclusion
This paper presents a robotic agent that combines video recognition and natural language processing to assist users in understanding and interacting with video-based scenes. The researchers' findings demonstrate the potential of this approach to improve trust and efficiency in human-robot interactions, with a small but meaningful performance advantage over other benchmark methods.
While the study has some limitations, the work represents an important step towards developing more natural and effective ways for humans to engage with and derive insights from video data through conversational interactions with intelligent robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Open-Ended Multi-Modal Relational Reasoning for Video Question Answering
Haozheng Luo, Ruiyang Qin, Chenwei Xu, Guo Ye, Zening Luo
In this paper, we introduce a robotic agent specifically designed to analyze external environments and address participants' questions. The primary focus of this agent is to assist individuals using language-based interactions within video-based scenes. Our proposed method integrates video recognition technology and natural language processing models within the robotic agent. We investigate the crucial factors affecting human-robot interactions by examining pertinent issues arising between participants and robot agents. Methodologically, our experimental findings reveal a positive relationship between trust and interaction efficiency. Furthermore, our model demonstrates a 2% to 3% performance enhancement in comparison to other benchmark methods.
Read more6/12/2024
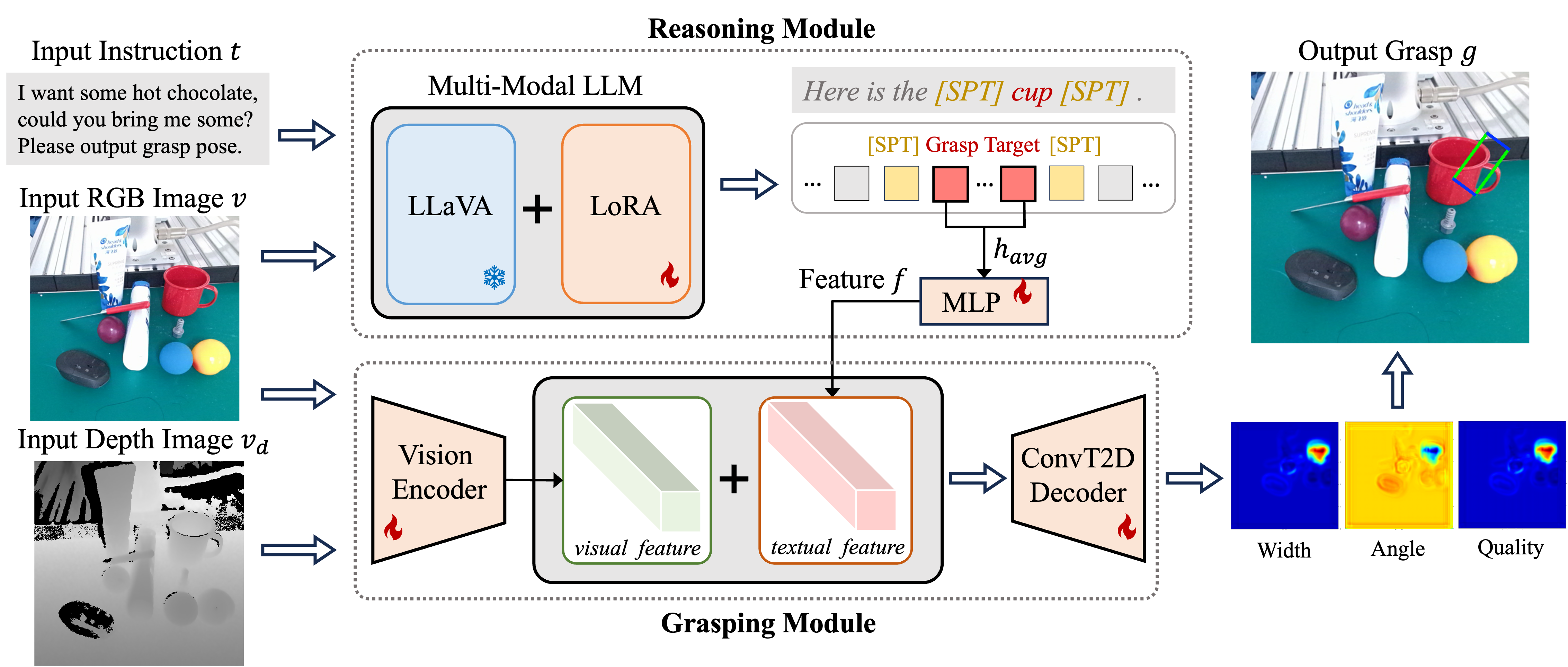
0
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024

0
Multimodal Datasets and Benchmarks for Reasoning about Dynamic Spatio-Temporality in Everyday Environments
Takanori Ugai, Kensho Hara, Shusaku Egami, Ken Fukuda
We used a 3D simulator to create artificial video data with standardized annotations, aiming to aid in the development of Embodied AI. Our question answering (QA) dataset measures the extent to which a robot can understand human behavior and the environment in a home setting. Preliminary experiments suggest our dataset is useful in measuring AI's comprehension of daily life. end{abstract}
Read more8/22/2024
🔄
0
Embodied Agents for Efficient Exploration and Smart Scene Description
Roberto Bigazzi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara
The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Read more4/16/2024