Closed Loop Interactive Embodied Reasoning for Robot Manipulation

0
🖼️
Sign in to get full access
Overview
- This paper introduces a new simulation environment and benchmark for developing embodied reasoning systems that can perform complex physical tasks in response to natural language queries.
- The authors propose a Closed Loop Interactive Reasoning (CLIER) approach that accounts for non-visual object properties, scene changes, and uncertain robotic actions.
- The system is evaluated in simulation and on real-world manipulation tasks, achieving success rates above 76% and 64% respectively.
Plain English Explanation
The paper discusses embodied reasoning systems - AI systems that can physically interact with objects and environments to perform complex tasks. These systems typically respond to natural language queries about a specific physical scene, such as "Sort the objects from lightest to heaviest."
To facilitate the development of such systems, the authors introduce a new simulation environment that combines the MuJoCo physics engine and the Blender rendering engine. This provides realistic visual observations that accurately reflect the physical state of the simulated scene.
The authors also propose a new benchmark composed of 10 multi-step reasoning scenarios. These scenarios require the system to make simultaneous visual and physical measurements to complete the task.
Finally, the researchers developed a new Closed Loop Interactive Reasoning (CLIER) approach. This approach takes into account not only the visual properties of objects, but also their non-visual properties, changes in the scene caused by external factors, and the uncertain outcomes of robotic actions.
The CLIER system was extensively evaluated in simulation and on real-world manipulation tasks, achieving success rates of over 76% and 64% respectively.
Technical Explanation
The paper introduces a new simulation environment that combines the MuJoCo physics engine and the Blender rendering engine to provide realistic visual observations that accurately reflect the physical state of the simulated scene. This environment is used to develop and evaluate a new Closed Loop Interactive Reasoning (CLIER) approach for embodied reasoning systems.
The CLIER approach takes into account not only the visual properties of objects, but also their non-visual properties, changes in the scene caused by external factors, and the uncertain outcomes of robotic actions. This is in contrast to traditional vision-language-based physical reasoning approaches, which focus solely on visual information.
The authors evaluate their CLIER system on a new benchmark composed of 10 multi-step reasoning scenarios that require simultaneous visual and physical measurements. The system achieves success rates of over 76% in simulation and 64% on real-world manipulation tasks.
Critical Analysis
The paper presents a comprehensive approach to developing embodied reasoning systems that can interact with physical environments to perform complex tasks. The simulation environment and benchmark provide a valuable testbed for evaluating such systems.
One potential limitation of the research is the use of a custom simulation environment, which may not fully capture the complexity and uncertainty of real-world environments. Additionally, the CLIER approach, while promising, may need further refinement and validation to ensure its robustness in diverse scenarios.
Future research could explore the integration of embodied generalist agents that can leverage general-purpose physical reasoning capabilities to tackle a wider range of tasks, beyond the specific scenarios presented in this paper.
Conclusion
This paper makes a significant contribution to the field of embodied reasoning systems by introducing a new simulation environment, benchmark, and Closed Loop Interactive Reasoning (CLIER) approach. The system's strong performance in both simulation and real-world manipulation tasks suggests that it could be a valuable tool for developing AI systems that can seamlessly interact with physical environments to solve complex problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Closed Loop Interactive Embodied Reasoning for Robot Manipulation
Michal Nazarczuk, Jan Kristof Behrens, Karla Stepanova, Matej Hoffmann, Krystian Mikolajczyk
Embodied reasoning systems integrate robotic hardware and cognitive processes to perform complex tasks typically in response to a natural language query about a specific physical environment. This usually involves changing the belief about the scene or physically interacting and changing the scene (e.g. 'Sort the objects from lightest to heaviest'). In order to facilitate the development of such systems we introduce a new simulating environment that makes use of MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. Together with the simulator we propose a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements. Finally, we develop a new modular Closed Loop Interactive Reasoning (CLIER) approach that takes into account the measurements of non-visual object properties, changes in the scene caused by external disturbances as well as uncertain outcomes of robotic actions. We extensively evaluate our reasoning approach in simulation and in the real world manipulation tasks with a success rate above 76% and 64%, respectively.
Read more4/24/2024
0
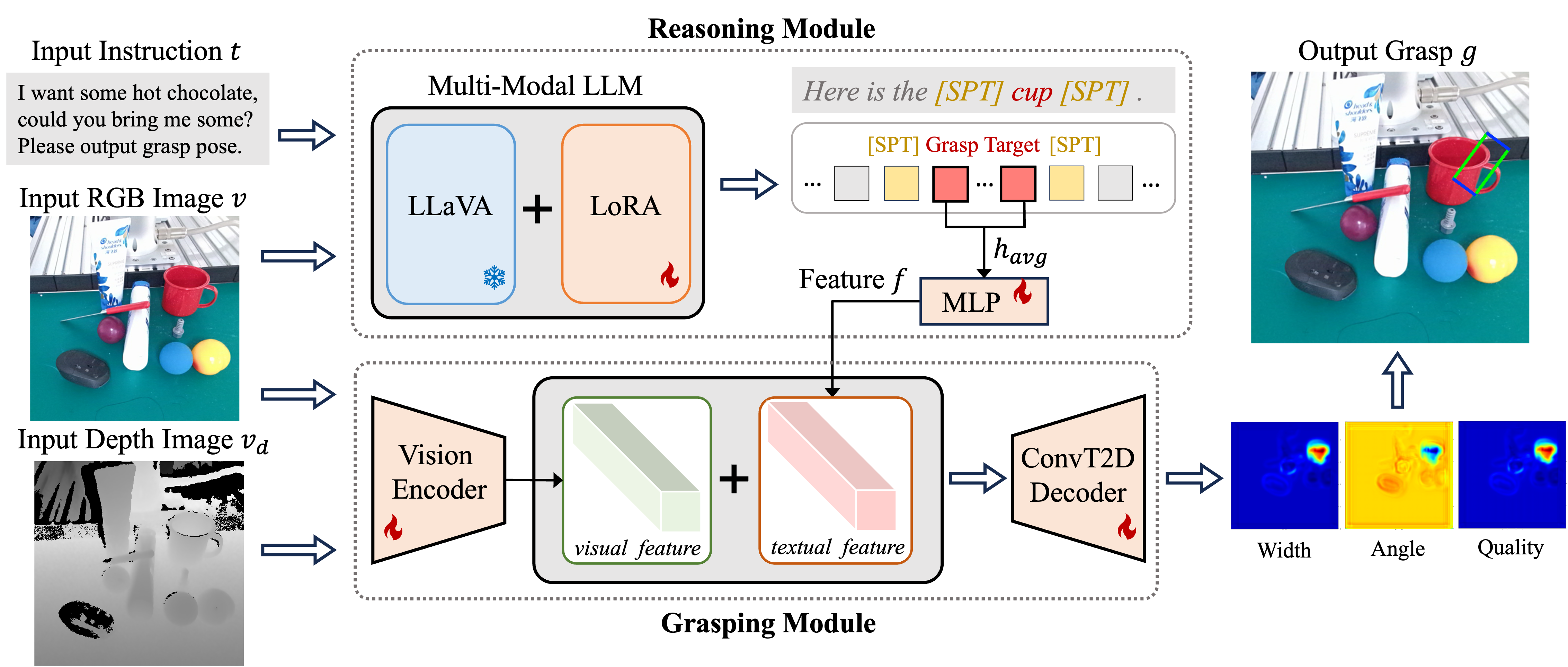
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024

0
New!Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation
Qingwen Bu, Jia Zeng, Li Chen, Yanchao Yang, Guyue Zhou, Junchi Yan, Ping Luo, Heming Cui, Yi Ma, Hongyang Li
Despite significant progress in robotics and embodied AI in recent years, deploying robots for long-horizon tasks remains a great challenge. Majority of prior arts adhere to an open-loop philosophy and lack real-time feedback, leading to error accumulation and undesirable robustness. A handful of approaches have endeavored to establish feedback mechanisms leveraging pixel-level differences or pre-trained visual representations, yet their efficacy and adaptability have been found to be constrained. Inspired by classic closed-loop control systems, we propose CLOVER, a closed-loop visuomotor control framework that incorporates feedback mechanisms to improve adaptive robotic control. CLOVER consists of a text-conditioned video diffusion model for generating visual plans as reference inputs, a measurable embedding space for accurate error quantification, and a feedback-driven controller that refines actions from feedback and initiates replans as needed. Our framework exhibits notable advancement in real-world robotic tasks and achieves state-of-the-art on CALVIN benchmark, improving by 8% over previous open-loop counterparts. Code and checkpoints are maintained at https://github.com/OpenDriveLab/CLOVER.
Read more9/16/2024
🔄
0
Embodied Agents for Efficient Exploration and Smart Scene Description
Roberto Bigazzi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara
The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Read more4/16/2024