Open-Set Domain Adaptation for Semantic Segmentation

0
🛸
Sign in to get full access
Overview
- This paper explores a new technique called BUS (Boundary Uncertainty-guided Source-free) for open-set unsupervised domain adaptation in semantic segmentation tasks.
- The key idea is to leverage the uncertainty information in the target domain to guide the model adaptation, which helps overcome negative transfer and improve performance.
- The paper also compares BUS with other baselines and analyzes the sensitivity of the pseudo-labeling threshold.
Plain English Explanation
The paper introduces a new method called BUS (Boundary Uncertainty-guided Source-free) for a specific machine learning task called semantic segmentation. Semantic segmentation is the process of dividing an image into different meaningful regions, such as distinguishing between a person, a car, and the background.
The key challenge the paper addresses is the situation where you have a machine learning model trained on one dataset (the "source" domain), but you want to use that model to make predictions on a different dataset (the "target" domain). This is called unsupervised domain adaptation, and it's challenging because the data distributions in the source and target domains can be quite different.
The main insight behind the BUS method is to use information about the "uncertainty" of the model's predictions on the target domain data. Regions where the model is very uncertain about its predictions are likely to be areas where the source and target domains differ, and the model needs to adapt. By focusing the adaptation process on these uncertain regions, the BUS method is able to overcome the problem of "negative transfer," where the model actually performs worse on the target domain after adaptation.
The paper compares the BUS method to other baseline approaches and also analyzes how sensitive the method is to the choice of a key hyperparameter, the pseudo-labeling threshold. Overall, the BUS method is shown to outperform other techniques and provide an effective way to adapt a model to a new domain without requiring any labeled target domain data.
Technical Explanation
The BUS method leverages the uncertainty information in the target domain to guide the model adaptation process for open-set unsupervised domain adaptation in semantic segmentation tasks. The key idea is to use the model's prediction uncertainty to identify the regions in the target domain that are most different from the source domain, and focus the adaptation process on those regions.
The BUS architecture consists of a feature extractor, a segmentation head, and an uncertainty estimation module. During adaptation, the model first generates pseudo-labels for the target domain samples based on a confidence threshold. It then computes the uncertainty of the pseudo-labels and uses this information to selectively update the model parameters, prioritizing the regions with high uncertainty.
The paper also compares the BUS method with other baselines, including style adaptation, multi-target adaptation, and online selection of distant domains. The results show that BUS outperforms these methods on various benchmark datasets for semantic segmentation.
Additionally, the paper analyzes the sensitivity of the BUS method to the pseudo-labeling threshold. The experiments demonstrate that BUS is relatively robust to the choice of this hyperparameter, as long as it is set within a reasonable range.
Critical Analysis
The paper provides a compelling approach to addressing the challenge of unsupervised domain adaptation in semantic segmentation tasks. The key strength of the BUS method is its ability to overcome the problem of negative transfer, which is a common issue with naive domain adaptation techniques.
However, the paper does not fully address the limitations of the BUS method. For example, it is unclear how the method would perform in scenarios with more significant domain shifts, or how sensitive it is to the quality of the uncertainty estimation module. Additionally, the paper does not explore the potential computational overhead of the uncertainty-guided adaptation process compared to simpler approaches.
Furthermore, the paper could have provided more insights into the underlying reasons why the BUS method is effective. While the authors explain the intuition behind the approach, a deeper analysis of the factors contributing to its success could have strengthened the overall contribution.
Nonetheless, the BUS method represents an important step forward in the field of unsupervised domain adaptation, and the insights from this paper could inspire future research in this area, such as rethinking barely supervised segmentation or other approaches to overcome negative transfer.
Conclusion
The paper introduces the BUS method, a novel technique for open-set unsupervised domain adaptation in semantic segmentation tasks. By leveraging the uncertainty information in the target domain, BUS is able to overcome the issue of negative transfer and outperform other baseline approaches.
The key contribution of this work is the insight that selectively adapting the model based on uncertainty can lead to more effective domain adaptation, particularly in scenarios where the source and target domains differ significantly. This finding has important implications for the broader field of unsupervised domain adaptation, and could inspire future research in this direction.
While the paper has some limitations, the BUS method represents an important step forward in addressing the challenging problem of adapting machine learning models to new domains without access to labeled target data. As the field of computer vision continues to advance, techniques like BUS will be increasingly important for deploying robust and adaptable models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Open-Set Domain Adaptation for Semantic Segmentation
Seun-An Choe, Ah-Hyung Shin, Keon-Hee Park, Jinwoo Choi, Gyeong-Moon Park
Unsupervised domain adaptation (UDA) for semantic segmentation aims to transfer the pixel-wise knowledge from the labeled source domain to the unlabeled target domain. However, current UDA methods typically assume a shared label space between source and target, limiting their applicability in real-world scenarios where novel categories may emerge in the target domain. In this paper, we introduce Open-Set Domain Adaptation for Semantic Segmentation (OSDA-SS) for the first time, where the target domain includes unknown classes. We identify two major problems in the OSDA-SS scenario as follows: 1) the existing UDA methods struggle to predict the exact boundary of the unknown classes, and 2) they fail to accurately predict the shape of the unknown classes. To address these issues, we propose Boundary and Unknown Shape-Aware open-set domain adaptation, coined BUS. Our BUS can accurately discern the boundaries between known and unknown classes in a contrastive manner using a novel dilation-erosion-based contrastive loss. In addition, we propose OpenReMix, a new domain mixing augmentation method that guides our model to effectively learn domain and size-invariant features for improving the shape detection of the known and unknown classes. Through extensive experiments, we demonstrate that our proposed BUS effectively detects unknown classes in the challenging OSDA-SS scenario compared to the previous methods by a large margin. The code is available at https://github.com/KHU-AGI/BUS.
Read more5/31/2024

0
Uncertainty-guided Open-Set Source-Free Unsupervised Domain Adaptation with Target-private Class Segregation
Mattia Litrico, Davide Talon, Sebastiano Battiato, Alessio Del Bue, Mario Valerio Giuffrida, Pietro Morerio
Standard Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target but usually requires simultaneous access to both source and target data. Moreover, UDA approaches commonly assume that source and target domains share the same labels space. Yet, these two assumptions are hardly satisfied in real-world scenarios. This paper considers the more challenging Source-Free Open-set Domain Adaptation (SF-OSDA) setting, where both assumptions are dropped. We propose a novel approach for SF-OSDA that exploits the granularity of target-private categories by segregating their samples into multiple unknown classes. Starting from an initial clustering-based assignment, our method progressively improves the segregation of target-private samples by refining their pseudo-labels with the guide of an uncertainty-based sample selection module. Additionally, we propose a novel contrastive loss, named NL-InfoNCELoss, that, integrating negative learning into self-supervised contrastive learning, enhances the model robustness to noisy pseudo-labels. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed method over existing approaches, establishing new state-of-the-art performance. Notably, additional analyses show that our method is able to learn the underlying semantics of novel classes, opening the possibility to perform novel class discovery.
Read more4/17/2024
📈
0
Unified Domain Adaptive Semantic Segmentation
Zhe Zhang, Gaochang Wu, Jing Zhang, Xiatian Zhu, Dacheng Tao, Tianyou Chai
Unsupervised Domain Adaptive Semantic Segmentation (UDA-SS) aims to transfer the supervision from a labeled source domain to an unlabeled target domain. The majority of existing UDA-SS works typically consider images whilst recent attempts have extended further to tackle videos by modeling the temporal dimension. Although the two lines of research share the major challenges -- overcoming the underlying domain distribution shift, their studies are largely independent, resulting in fragmented insights, a lack of holistic understanding, and missed opportunities for cross-pollination of ideas. This fragmentation prevents the unification of methods, leading to redundant efforts and suboptimal knowledge transfer across image and video domains. Under this observation, we advocate unifying the study of UDA-SS across video and image scenarios, enabling a more comprehensive understanding, synergistic advancements, and efficient knowledge sharing. To that end, we explore the unified UDA-SS from a general data augmentation perspective, serving as a unifying conceptual framework, enabling improved generalization, and potential for cross-pollination of ideas, ultimately contributing to the overall progress and practical impact of this field of research. Specifically, we propose a Quad-directional Mixup (QuadMix) method, characterized by tackling distinct point attributes and feature inconsistencies through four-directional paths for intra- and inter-domain mixing in a feature space. To deal with temporal shifts with videos, we incorporate optical flow-guided feature aggregation across spatial and temporal dimensions for fine-grained domain alignment. Extensive experiments show that our method outperforms the state-of-the-art works by large margins on four challenging UDA-SS benchmarks. Our source code and models will be released at url{https://github.com/ZHE-SAPI/UDASS}.
Read more9/14/2024
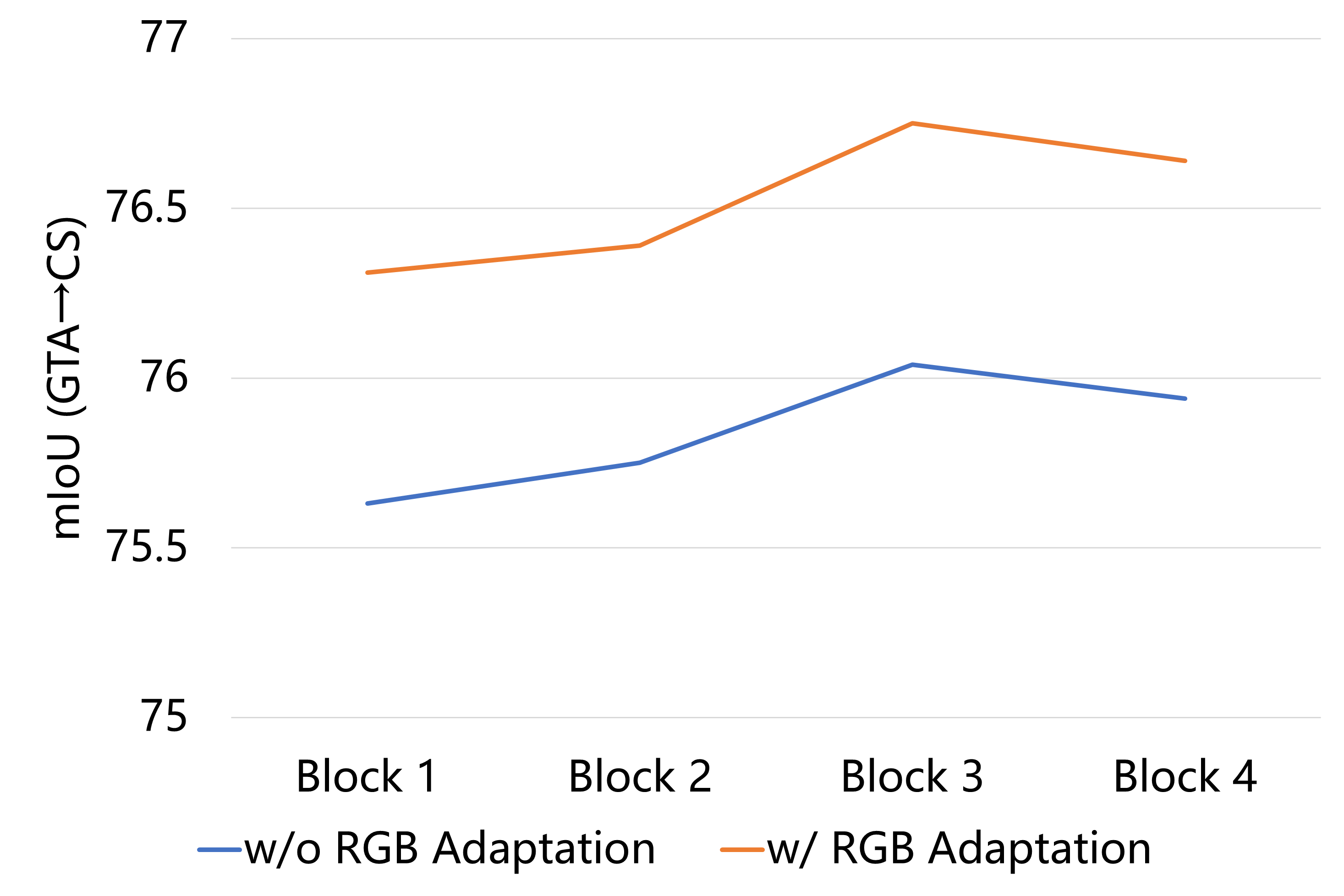
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024