Evaluating and Optimizing Educational Content with Large Language Model Judgments
2403.02795
0
0
Abstract
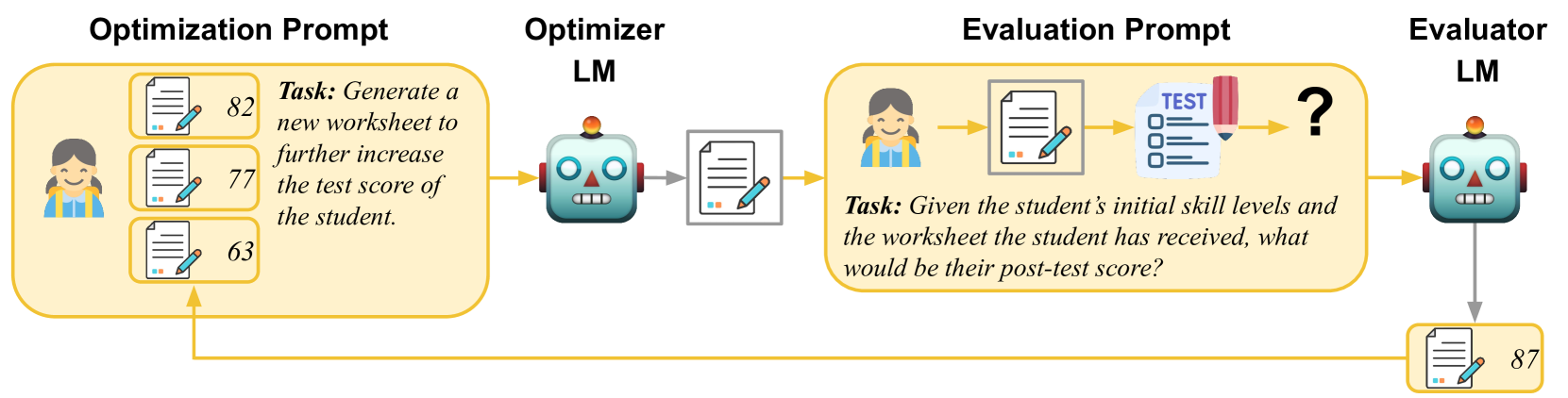
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
Create account to get full access
Overview
- This paper explores using large language models (LLMs) to evaluate and optimize educational content.
- The authors investigate how LLMs can be used to simulate student understanding and provide feedback on the quality and effectiveness of instructional materials.
- Key findings include that LLMs can accurately assess the quality of educational content and provide specific suggestions for improvement.
Plain English Explanation
The paper discusses using advanced AI language models, known as large language models (LLMs), to evaluate and improve educational content. These AI models are trained on vast amounts of text data and can understand and generate human-like language.
The researchers explored how LLMs could be used to simulate student learning and provide feedback on the quality and effectiveness of instructional materials, such as lesson plans or explanations. By having the LLM "read" the educational content, the authors found that the model could accurately assess things like how well the content was explained, whether key concepts were covered, and what areas might be confusing for students.
The LLM could then provide specific suggestions for how to improve the content to better support student understanding. This could be a powerful tool for educators and content creators, allowing them to quickly and easily get feedback to refine their materials before using them with real students.
The paper demonstrates how advanced AI can be leveraged to enhance educational practices and content in an automated and scalable way. This could lead to more effective and personalized learning experiences for students.
Technical Explanation
The paper proposes a framework for using large language models (LLMs) to evaluate and optimize educational content. The key elements of their approach include:
-
Simulating Student Understanding: The authors fine-tuned an LLM on a dataset of student responses to assess how well the model could simulate student understanding of the educational content. This built on prior research on using LLMs to simulate students.
-
Evaluating Content Quality: The LLM was then used to evaluate the quality and effectiveness of instructional materials, such as lesson plans and explanations. The model assessed factors like clarity, completeness, and alignment with learning objectives.
-
Providing Optimization Feedback: Based on its evaluation, the LLM provided specific suggestions for how the educational content could be improved to better support student learning. This included identifying areas that needed more explanation or examples.
The authors conducted experiments to validate their approach, showing that the LLM-based evaluations aligned well with human assessments of the content quality. They also demonstrated the model's ability to generate relevant feedback for improving the materials.
Critical Analysis
The paper presents a promising approach for leveraging LLMs to enhance educational content and practices. The ability to automatically assess instructional materials and provide targeted feedback could be a valuable tool for educators and content creators.
However, the research also acknowledges some key limitations and areas for further exploration. For example, the LLM evaluations may not fully capture the nuances of how real students learn and understand the material. There are also open questions around the scalability and generalizability of the approach across different educational domains and contexts.
Additionally, while the LLM-based feedback can suggest improvements, ultimately human judgment and subject matter expertise will be needed to refine the content in meaningful ways. The paper does not address potential biases or errors that could be introduced by the LLM evaluations.
Further research is needed to rigorously evaluate the effectiveness of this approach in real-world educational settings and explore ways to integrate human oversight to ensure the quality and appropriateness of the LLM-generated feedback.
Conclusion
This paper demonstrates the potential for using large language models to enhance the development and optimization of educational content. By simulating student understanding and providing targeted feedback, LLMs could become a powerful tool to support more effective and personalized learning experiences.
However, the research also highlights the need for continued exploration and validation of this approach, particularly around its scalability, generalizability, and the integration of human expertise. As AI continues to advance, finding ways to leverage these technologies to improve education will be an important area of ongoing research and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
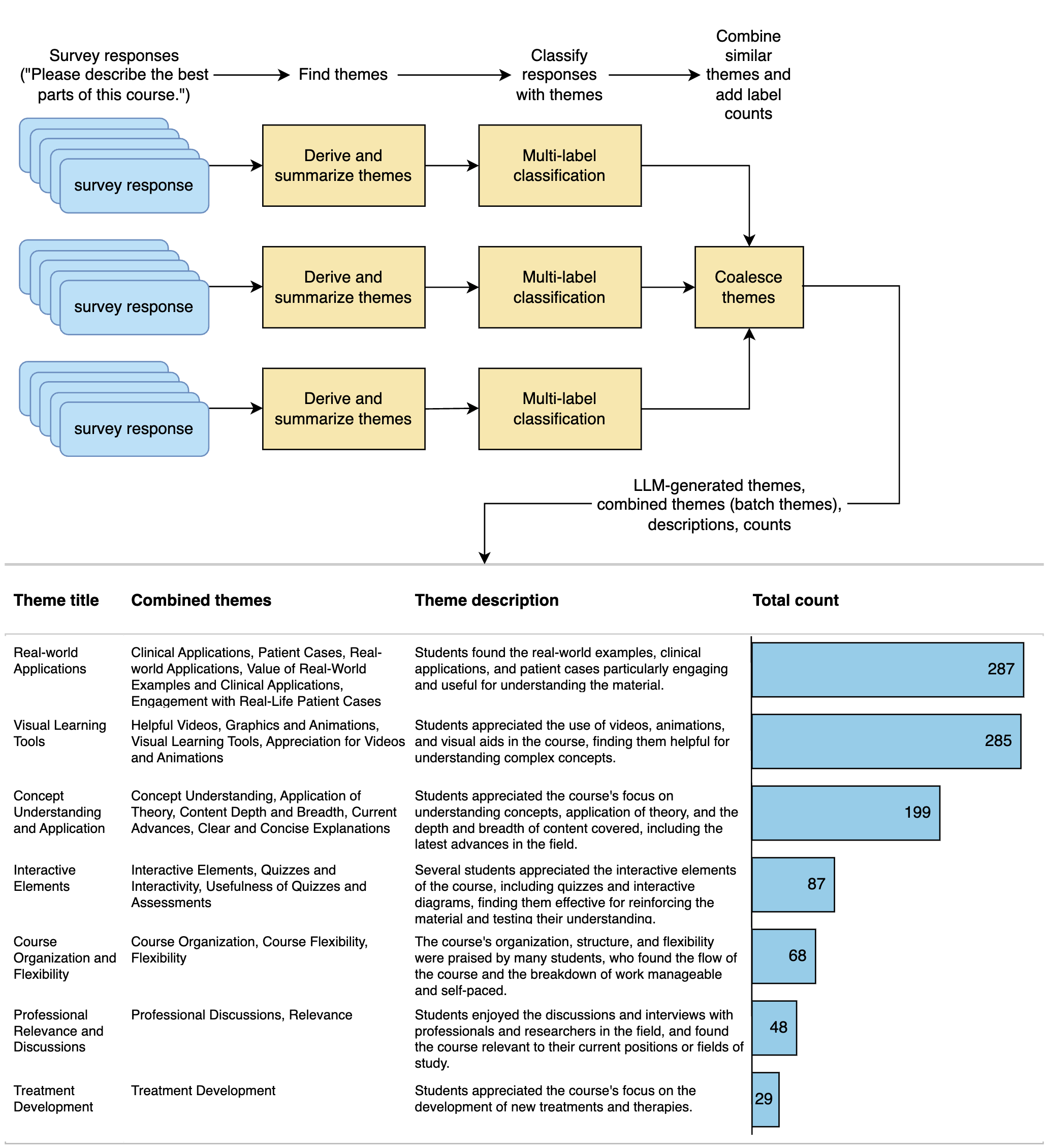
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024
💬
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
0
0
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
4/17/2024

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024
Large Language Models for Education: A Survey and Outlook
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, Qingsong Wen
0
0
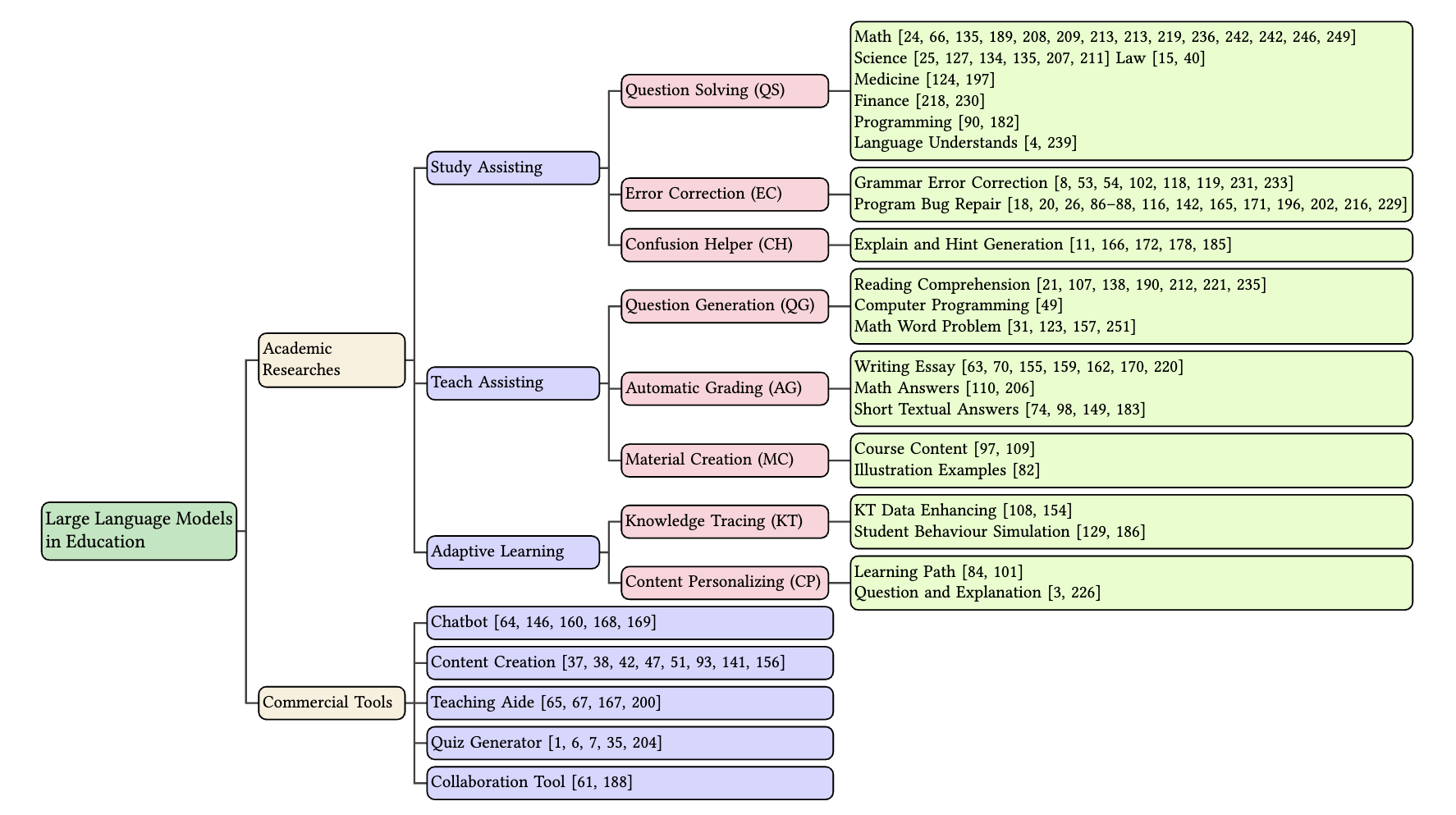
The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
4/3/2024