Towards Multi-modal Transformers in Federated Learning

0
Sign in to get full access
Overview
- Proposes a novel approach called "Transfer MFL" for federated learning with multimodal data
- Aims to improve model performance and efficiency in federated settings with heterogeneous data
- Introduces a framework for transferring knowledge between modalities and clients in a federated setup
Plain English Explanation
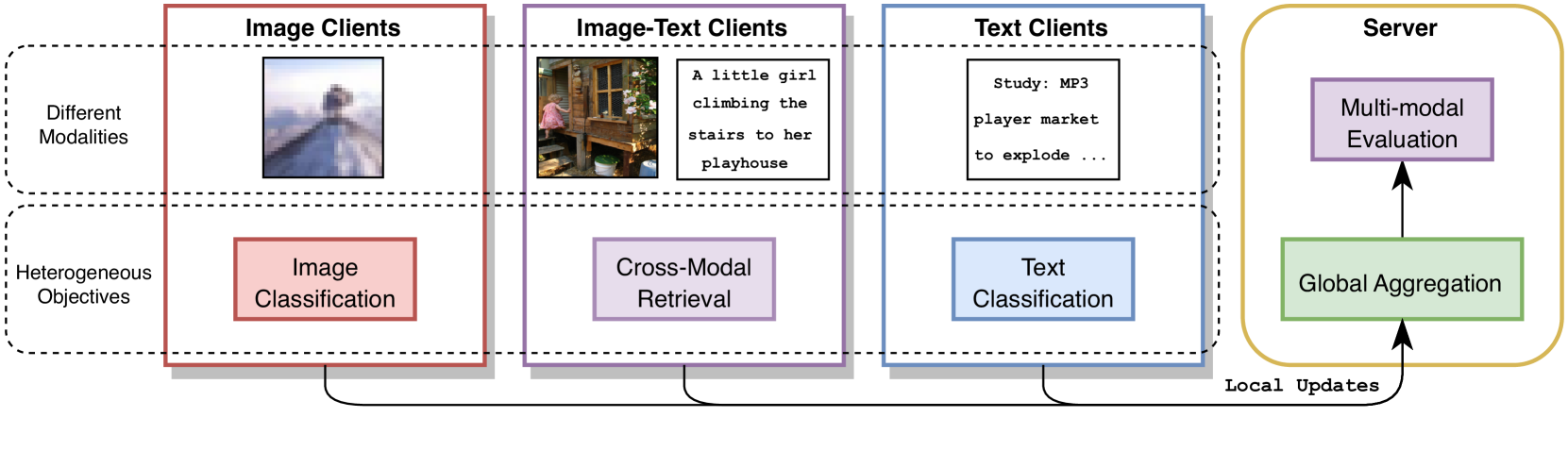
This paper presents a new method called "Transfer MFL" that addresses challenges in federated learning with multimodal data, such as images, text, and sensor readings. Federated learning allows multiple devices or clients to collaboratively train a shared model without sharing their raw data, which is important for privacy.
However, federated learning can be difficult when the data on different clients varies greatly in type and distribution, known as data heterogeneity. The proposed Transfer MFL approach tries to overcome this by enabling the transfer of knowledge between modalities (e.g., from images to text) and across different client devices. This allows the model to leverage complementary information and improve its overall performance, even when the clients have very different data.
The paper introduces a technical framework for implementing this Transfer MFL approach and demonstrates its benefits through experiments. The key idea is to enable the model to learn representations that are transferable across modalities and clients, leading to better performance compared to traditional federated learning methods.
Technical Explanation
The core of the Transfer MFL approach is a multi-modal transformer architecture that can effectively capture and transfer knowledge between different data modalities. This is combined with a federated learning setup where multiple clients collaboratively train the model without sharing their raw data.
The key innovations include:
- A modality-specific encoder that learns representations for each data type (e.g., images, text, sensor data)
- A shared multimodal transformer that can fuse and transfer knowledge between these modalities
- A federated learning algorithm that coordinates the training process across clients, enabling knowledge transfer between them
Through experiments, the authors show that Transfer MFL can outperform standard federated learning methods, especially when the client data is highly heterogeneous. This suggests the approach is effective at mitigating the challenges of data heterogeneity in federated multimodal learning.
The paper also discusses strategies for federated distillation to further improve the efficiency and performance of the trained models. Additionally, the authors provide insights on overcoming communication constraints in federated learning, which is crucial for deploying such approaches in real-world scenarios with limited bandwidth.
Critical Analysis
The authors acknowledge that their approach relies on the availability of multimodal data on each client, which may not always be the case in practice. They also note that the performance improvements depend on the degree of heterogeneity in the client data, and the method may not provide significant benefits in more homogeneous settings.
One potential limitation is that the proposed architecture may be computationally and memory-intensive, especially when scaling to large-scale models and datasets. Further research is needed to explore more efficient implementation strategies, potentially leveraging techniques like heterogeneous federated learning with split language models.
Additionally, the paper does not address potential issues related to data privacy and security in federated learning, which are critical considerations for real-world deployment. Future work could explore ways to enhance the privacy-preserving properties of the Transfer MFL approach.
Conclusion
The "Transfer MFL" framework proposed in this paper represents a significant step forward in addressing the challenges of federated learning with multimodal data. By enabling cross-modal and cross-client knowledge transfer, the approach can improve model performance and efficiency, especially in the presence of data heterogeneity.
The technical innovations and experimental insights presented in this work could pave the way for more advanced federated learning systems that can effectively leverage diverse data sources and modalities. Further research and development in this direction could have important implications for a wide range of applications, from healthcare to smart city management, where privacy-preserving and data-efficient AI solutions are in high demand.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Multi-modal Transformers in Federated Learning
Guangyu Sun, Matias Mendieta, Aritra Dutta, Xin Li, Chen Chen
Multi-modal transformers mark significant progress in different domains, but siloed high-quality data hinders their further improvement. To remedy this, federated learning (FL) has emerged as a promising privacy-preserving paradigm for training models without direct access to the raw data held by different clients. Despite its potential, a considerable research direction regarding the unpaired uni-modal clients and the transformer architecture in FL remains unexplored. To fill this gap, this paper explores a transfer multi-modal federated learning (MFL) scenario within the vision-language domain, where clients possess data of various modalities distributed across different datasets. We systematically evaluate the performance of existing methods when a transformer architecture is utilized and introduce a novel framework called Federated modality complementary and collaboration (FedCola) by addressing the in-modality and cross-modality gaps among clients. Through extensive experiments across various FL settings, FedCola demonstrates superior performance over previous approaches, offering new perspectives on future federated training of multi-modal transformers.
Read more7/18/2024
⚙️
0
Leveraging Foundation Models for Multi-modal Federated Learning with Incomplete Modality
Liwei Che, Jiaqi Wang, Xinyue Liu, Fenglong Ma
Federated learning (FL) has obtained tremendous progress in providing collaborative training solutions for distributed data silos with privacy guarantees. However, few existing works explore a more realistic scenario where the clients hold multiple data modalities. In this paper, we aim to solve a novel challenge in multi-modal federated learning (MFL) -- modality missing -- the clients may lose part of the modalities in their local data sets. To tackle the problems, we propose a novel multi-modal federated learning method, Federated Multi-modal contrastiVe training with Pre-trained completion (FedMVP), which integrates the large-scale pre-trained models to enhance the federated training. In the proposed FedMVP framework, each client deploys a large-scale pre-trained model with frozen parameters for modality completion and representation knowledge transfer, enabling efficient and robust local training. On the server side, we utilize generated data to uniformly measure the representation similarity among the uploaded client models and construct a graph perspective to aggregate them according to their importance in the system. We demonstrate that the model achieves superior performance over two real-world image-text classification datasets and is robust to the performance degradation caused by missing modality.
Read more6/18/2024

0
MLLM-FL: Multimodal Large Language Model Assisted Federated Learning on Heterogeneous and Long-tailed Data
Jianyi Zhang, Hao Frank Yang, Ang Li, Xin Guo, Pu Wang, Haiming Wang, Yiran Chen, Hai Li
Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-FL), which which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, prior to local training on local datasets of clients, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of multimodal large language models. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.
Read more9/11/2024

0
Resource-Efficient Federated Multimodal Learning via Layer-wise and Progressive Training
Ye Lin Tun, Chu Myaet Thwal, Minh N. H. Nguyen, Choong Seon Hong
Combining different data modalities enables deep neural networks to tackle complex tasks more effectively, making multimodal learning increasingly popular. To harness multimodal data closer to end users, it is essential to integrate multimodal learning with privacy-preserving training approaches such as federated learning (FL). However, compared to conventional unimodal learning, multimodal setting requires dedicated encoders for each modality, resulting in larger and more complex models that demand significant resources. This presents a substantial challenge for FL clients operating with limited computational resources and communication bandwidth. To address these challenges, we introduce LW-FedMML, a layer-wise federated multimodal learning approach, which decomposes the training process into multiple steps. Each step focuses on training only a portion of the model, thereby significantly reducing the memory and computational requirements. Moreover, FL clients only need to exchange the trained model portion with the central server, lowering the resulting communication cost. We conduct extensive experiments across various FL scenarios and multimodal learning setups to validate the effectiveness of our proposed method. The results demonstrate that LW-FedMML can compete with conventional end-to-end federated multimodal learning (FedMML) while significantly reducing the resource burden on FL clients. Specifically, LW-FedMML reduces memory usage by up to $2.7times$, computational operations (FLOPs) by $2.4times$, and total communication cost by $2.3times$. We also introduce a progressive training approach called Prog-FedMML. While it offers lesser resource efficiency than LW-FedMML, Prog-FedMML has the potential to surpass the performance of end-to-end FedMML, making it a viable option for scenarios with fewer resource constraints.
Read more7/23/2024