CTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
2406.07923
0
0
Abstract
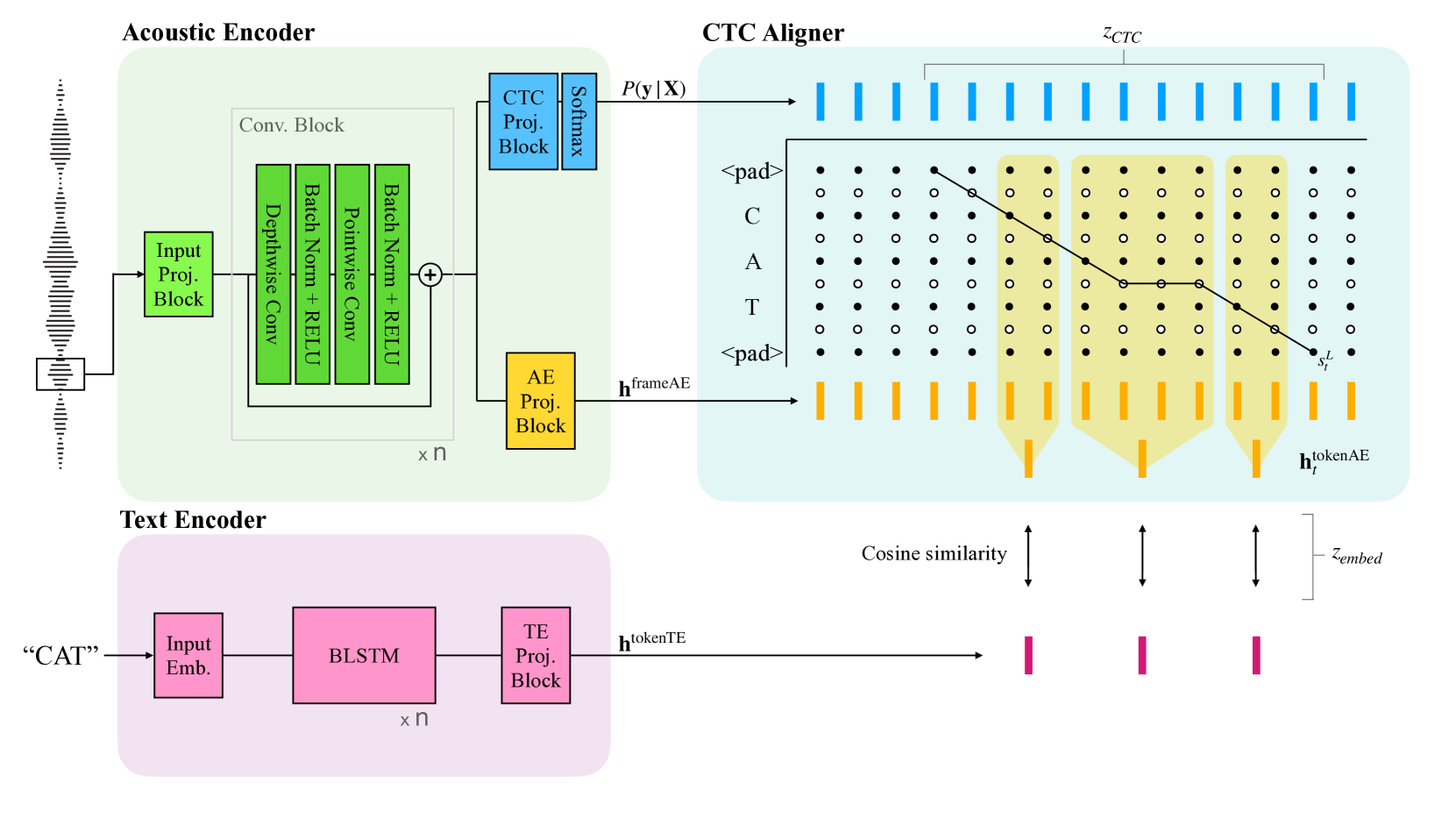
This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
Create account to get full access
Overview
- This paper presents a novel approach for open-vocabulary keyword spotting, which enables the detection of keywords without a predefined vocabulary.
- The key innovation is the use of a CTC-aligned audio-text embedding model that jointly learns representations for both audio and text.
- This allows the system to perform keyword spotting on audio streams by matching the embeddings of the audio to a set of text keywords, without being limited to a fixed vocabulary.
Plain English Explanation
The paper describes a way to build an AI system that can detect specific words or phrases in audio recordings, even if those words are not part of a predefined list. [This is similar to how open-vocabulary keyword spotting systems work.]
The key idea is to have the system learn a shared representation, or "embedding", for both the audio and the text of the keywords. [This is related to how multi-modal prompts can be used for keyword spotting.]
By mapping the audio and text to a common space, the system can then match the audio of the recording to the text of the keywords, allowing it to spot keywords that it hasn't explicitly been trained on before. [This approach helps bridge the language gap between audio and text.]
The key advantage of this is that the system is not limited to a fixed set of keywords, and can potentially detect any word or phrase, as long as it has seen examples of that text during training. [This is similar to how text-independent phone-to-audio models can handle open-vocabulary recognition.]
Technical Explanation
The paper introduces a CTC-aligned audio-text embedding model for open-vocabulary keyword spotting. The model takes in both audio and text as input, and learns a shared embedding space that represents the semantic and acoustic properties of the data.
This is achieved by training the model using a contrastive loss that encourages the embeddings of matching audio-text pairs to be close together, while pushing non-matching pairs apart. Importantly, the text embeddings are aligned with the audio using a CTC (Connectionist Temporal Classification) objective, which allows the model to handle variable-length audio and text sequences.
Once trained, the model can be used for keyword spotting by encoding the audio stream and comparing the resulting embedding to a set of text keyword embeddings. The closest matching keyword is then detected as the spotted keyword.
The paper evaluates this approach on several standard keyword spotting benchmarks, and demonstrates that it outperforms previous open-vocabulary methods, while also achieving competitive performance on fixed-vocabulary tasks.
Critical Analysis
The paper presents a well-designed and technically sound approach for open-vocabulary keyword spotting. The key strength is the use of the CTC-aligned audio-text embedding, which allows the model to handle variable-length inputs and learn a shared representation between audio and text.
One potential limitation is that the performance of the system may be dependent on the quality and diversity of the training data, particularly for rare or esoteric keywords. The paper does not explore this in depth, and it would be valuable to understand how the system performs on lower-resource language pairs or domains.
Additionally, the paper focuses on the task of keyword spotting, but does not explore the potential for this approach to be applied to other audio-text alignment or retrieval tasks. [It would be interesting to see how this technique could be extended to problems like relational proxy loss for audio-text based keyword search.]
Overall, the paper makes a valuable contribution to the field of open-vocabulary keyword spotting, and the proposed approach represents a promising direction for further research and development.
Conclusion
This paper introduces a CTC-aligned audio-text embedding model for open-vocabulary keyword spotting. By learning a shared representation for audio and text, the system can detect keywords in audio streams without being limited to a fixed vocabulary.
The key innovation is the use of the CTC objective to align the audio and text embeddings, which allows the model to handle variable-length inputs. This enables the system to perform accurate keyword spotting on a wide range of keywords, going beyond the constraints of traditional fixed-vocabulary approaches.
The paper demonstrates the effectiveness of this approach through extensive evaluation on standard benchmarks, and the results suggest that this technique could have significant implications for practical applications of open-vocabulary keyword spotting, such as in voice assistants, audio indexing, and other speech-based interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Open vocabulary keyword spotting through transfer learning from speech synthesis
Kesavaraj V, Anil Kumar Vuppala
0
0
Identifying keywords in an open-vocabulary context is crucial for personalizing interactions with smart devices. Previous approaches to open vocabulary keyword spotting dependon a shared embedding space created by audio and text encoders. However, these approaches suffer from heterogeneous modality representations (i.e., audio-text mismatch). To address this issue, our proposed framework leverages knowledge acquired from a pre-trained text-to-speech (TTS) system. This knowledge transfer allows for the incorporation of awareness of audio projections into the text representations derived from the text encoder. The performance of the proposed approach is compared with various baseline methods across four different datasets. The robustness of our proposed model is evaluated by assessing its performance across different word lengths and in an Out-of-Vocabulary (OOV) scenario. Additionally, the effectiveness of transfer learning from the TTS system is investigated by analyzing its different intermediate representations. The experimental results indicate that, in the challenging LibriPhrase Hard dataset, the proposed approach outperformed the cross-modality correspondence detector (CMCD) method by a significant improvement of 8.22% in area under the curve (AUC) and 12.56% in equal error rate (EER).
4/19/2024

MM-KWS: Multi-modal Prompts for Multilingual User-defined Keyword Spotting
Zhiqi Ai, Zhiyong Chen, Shugong Xu
0
0
In this paper, we propose MM-KWS, a novel approach to user-defined keyword spotting leveraging multi-modal enrollments of text and speech templates. Unlike previous methods that focus solely on either text or speech features, MM-KWS extracts phoneme, text, and speech embeddings from both modalities. These embeddings are then compared with the query speech embedding to detect the target keywords. To ensure the applicability of MM-KWS across diverse languages, we utilize a feature extractor incorporating several multilingual pre-trained models. Subsequently, we validate its effectiveness on Mandarin and English tasks. In addition, we have integrated advanced data augmentation tools for hard case mining to enhance MM-KWS in distinguishing confusable words. Experimental results on the LibriPhrase and WenetPhrase datasets demonstrate that MM-KWS outperforms prior methods significantly.
6/12/2024

Bridging Language Gaps in Audio-Text Retrieval
Zhiyong Yan, Heinrich Dinkel, Yongqing Wang, Jizhong Liu, Junbo Zhang, Yujun Wang, Bin Wang
0
0
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
6/18/2024
🔄
TIPAA-SSL: Text Independent Phone-to-Audio Alignment based on Self-Supervised Learning and Knowledge Transfer
No'e Tits, Prernna Bhatnagar, Thierry Dutoit
0
0
In this paper, we present a novel approach for text independent phone-to-audio alignment based on phoneme recognition, representation learning and knowledge transfer. Our method leverages a self-supervised model (wav2vec2) fine-tuned for phoneme recognition using a Connectionist Temporal Classification (CTC) loss, a dimension reduction model and a frame-level phoneme classifier trained thanks to forced-alignment labels (using Montreal Forced Aligner) to produce multi-lingual phonetic representations, thus requiring minimal additional training. We evaluate our model using synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Our proposed model outperforms the state-of-the-art (charsiu) in statistical metrics and has applications in language learning and speech processing systems. We leave experiments on other languages for future work but the design of the system makes it easily adaptable to other languages.
5/6/2024