Open-vocabulary Temporal Action Localization using VLMs

0

Sign in to get full access
Overview
- This paper proposes a method for open-vocabulary temporal action localization using vision-language models (VLMs).
- The key idea is to leverage the rich semantic understanding of VLMs to detect actions beyond a fixed set of predefined classes.
- The authors design a two-stage framework that first retrieves relevant video clips given a natural language query, then refines the temporal boundaries of the detected actions.
Plain English Explanation
The paper tackles the problem of temporal action localization, which is the task of identifying when specific actions occur in a video. Traditionally, this has been done using a predefined set of action categories. However, the authors argue that this limits the system's flexibility and ability to recognize a wide range of actions.
To address this, the researchers propose using vision-language models (VLMs). These are AI models that have been trained on both image/video data and text data, allowing them to understand the semantic connections between visual and linguistic information. By leveraging VLMs, the system can locate actions described using open-vocabulary natural language queries, beyond just a fixed set of pre-defined action classes.
The method works in two stages:
- Retrieval: Given a text query, the system first retrieves relevant video clips from a database using the VLM's understanding of language.
- Refinement: It then refines the temporal boundaries of the detected actions within those video clips.
This allows the system to localize actions using natural language, rather than being limited to a predefined set of action categories. The authors demonstrate the effectiveness of their approach on benchmark datasets.
Technical Explanation
The paper presents a two-stage framework for open-vocabulary temporal action localization using VLMs:
-
Retrieval Stage: Given a natural language query, the system first retrieves relevant video clips from a database using a VLM. Specifically, the authors fine-tune a pre-trained VLM (e.g. CLIP) to map both the video clips and text queries into a shared embedding space. This allows the system to identify the video clips most semantically relevant to the input query.
-
Refinement Stage: After retrieving the relevant video clips, the system then refines the temporal boundaries of the detected actions. The authors design a boundary regression module that takes the VLM's video-level features and outputs the start and end timestamps of the action.
The key innovation is leveraging the rich semantic understanding of VLMs to enable open-vocabulary action localization, going beyond just a fixed set of predefined action classes. The authors show that this approach outperforms prior methods that rely on predefined action categories or require additional training data.
Critical Analysis
The paper demonstrates a promising approach for open-vocabulary temporal action localization. By using VLMs, the system is able to detect a wide range of actions described in natural language, rather than being limited to a predefined ontology.
However, the authors note some limitations of their approach. The retrieval stage relies on the VLM's ability to accurately match the text query to relevant video clips, which may be challenging for complex or ambiguous queries. Additionally, the boundary refinement stage assumes that a single action is present in each retrieved clip, which may not always be the case in real-world videos.
Further research could explore ways to address these limitations, such as incorporating more context or developing more sophisticated techniques for temporal localization. Evaluating the method on a broader range of datasets and real-world applications would also help assess its practical utility.
Conclusion
This paper presents a novel approach for open-vocabulary temporal action localization using vision-language models. By leveraging the rich semantic understanding of VLMs, the system can detect a wide range of actions described in natural language, going beyond the limitations of predefined action categories.
The two-stage framework of retrieval and refinement demonstrates the potential of this approach, though there are some remaining challenges to address. Overall, the paper makes an important contribution to the field of video understanding, and suggests promising directions for future research in open-vocabulary action recognition and localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024

0
Open Vocabulary Multi-Label Video Classification
Rohit Gupta, Mamshad Nayeem Rizve, Jayakrishnan Unnikrishnan, Ashish Tawari, Son Tran, Mubarak Shah, Benjamin Yao, Trishul Chilimbi
Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
Read more7/15/2024
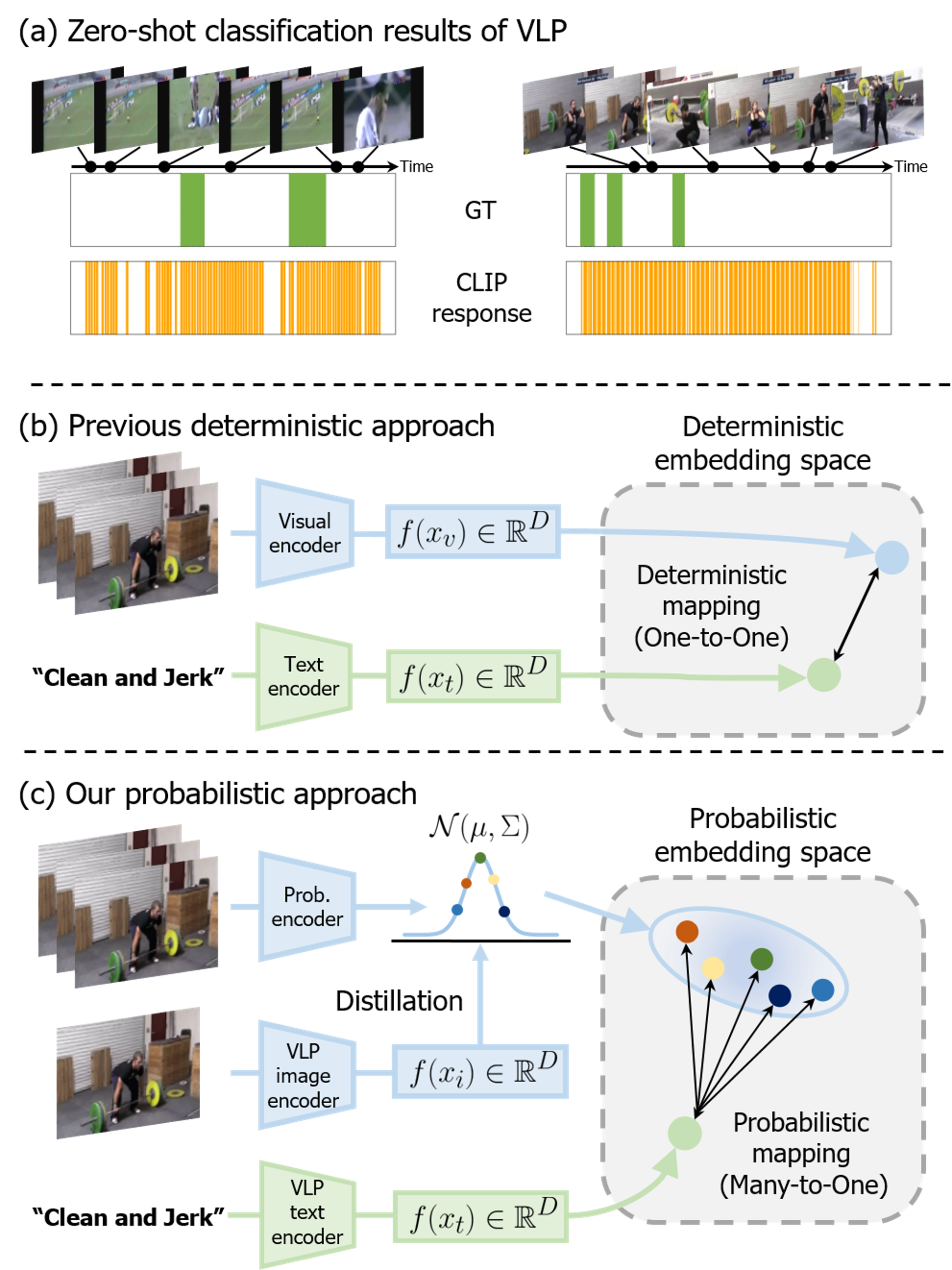
0
Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization
Geuntaek Lim, Hyunwoo Kim, Joonsoo Kim, Yukyung Choi
Weakly supervised temporal action localization (WTAL) aims to detect action instances in untrimmed videos using only video-level annotations. Since many existing works optimize WTAL models based on action classification labels, they encounter the task discrepancy problem (i.e., localization-by-classification). To tackle this issue, recent studies have attempted to utilize action category names as auxiliary semantic knowledge through vision-language pre-training (VLP). However, there are still areas where existing research falls short. Previous approaches primarily focused on leveraging textual information from language models but overlooked the alignment of dynamic human action and VLP knowledge in a joint space. Furthermore, the deterministic representation employed in previous studies struggles to capture fine-grained human motions. To address these problems, we propose a novel framework that aligns human action knowledge and VLP knowledge in a probabilistic embedding space. Moreover, we propose intra- and inter-distribution contrastive learning to enhance the probabilistic embedding space based on statistical similarities. Extensive experiments and ablation studies reveal that our method significantly outperforms all previous state-of-the-art methods. Code is available at https://github.com/sejong-rcv/PVLR.
Read more8/13/2024

0
Open-Vocabulary Temporal Action Localization using Multimodal Guidance
Akshita Gupta, Aditya Arora, Sanath Narayan, Salman Khan, Fahad Shahbaz Khan, Graham W. Taylor
Open-Vocabulary Temporal Action Localization (OVTAL) enables a model to recognize any desired action category in videos without the need to explicitly curate training data for all categories. However, this flexibility poses significant challenges, as the model must recognize not only the action categories seen during training but also novel categories specified at inference. Unlike standard temporal action localization, where training and test categories are predetermined, OVTAL requires understanding contextual cues that reveal the semantics of novel categories. To address these challenges, we introduce OVFormer, a novel open-vocabulary framework extending ActionFormer with three key contributions. First, we employ task-specific prompts as input to a large language model to obtain rich class-specific descriptions for action categories. Second, we introduce a cross-attention mechanism to learn the alignment between class representations and frame-level video features, facilitating the multimodal guided features. Third, we propose a two-stage training strategy which includes training with a larger vocabulary dataset and finetuning to downstream data to generalize to novel categories. OVFormer extends existing TAL methods to open-vocabulary settings. Comprehensive evaluations on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our method. Code and pretrained models will be publicly released.
Read more6/26/2024