Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization

0
Sign in to get full access
Overview
- The paper presents a novel approach for weakly supervised temporal action localization in videos using a probabilistic vision-language representation.
- The method leverages both video and text data to learn a shared representation that can detect and localize actions in untrimmed videos.
- The model is trained in a weakly supervised manner, only requiring video-level action labels without any temporal annotations.
Plain English Explanation
The researchers developed a new way to automatically identify and locate actions within untrimmed, or longer, videos. Their approach uses both visual information from the video and textual descriptions to learn a shared representation that can detect and pinpoint the timing of actions.
Typically, training models for this task requires detailed annotations that mark the start and end times of each action in the videos. However, this can be very time-consuming and expensive to obtain. Instead, the researchers' method only needs video-level labels that simply indicate which actions occur, without specifying when they happen.
By leveraging both the visual and textual data, the model is able to learn patterns that allow it to identify and localize actions in new videos, even without the granular annotations. This makes the approach more scalable and practical for real-world applications.
Technical Explanation
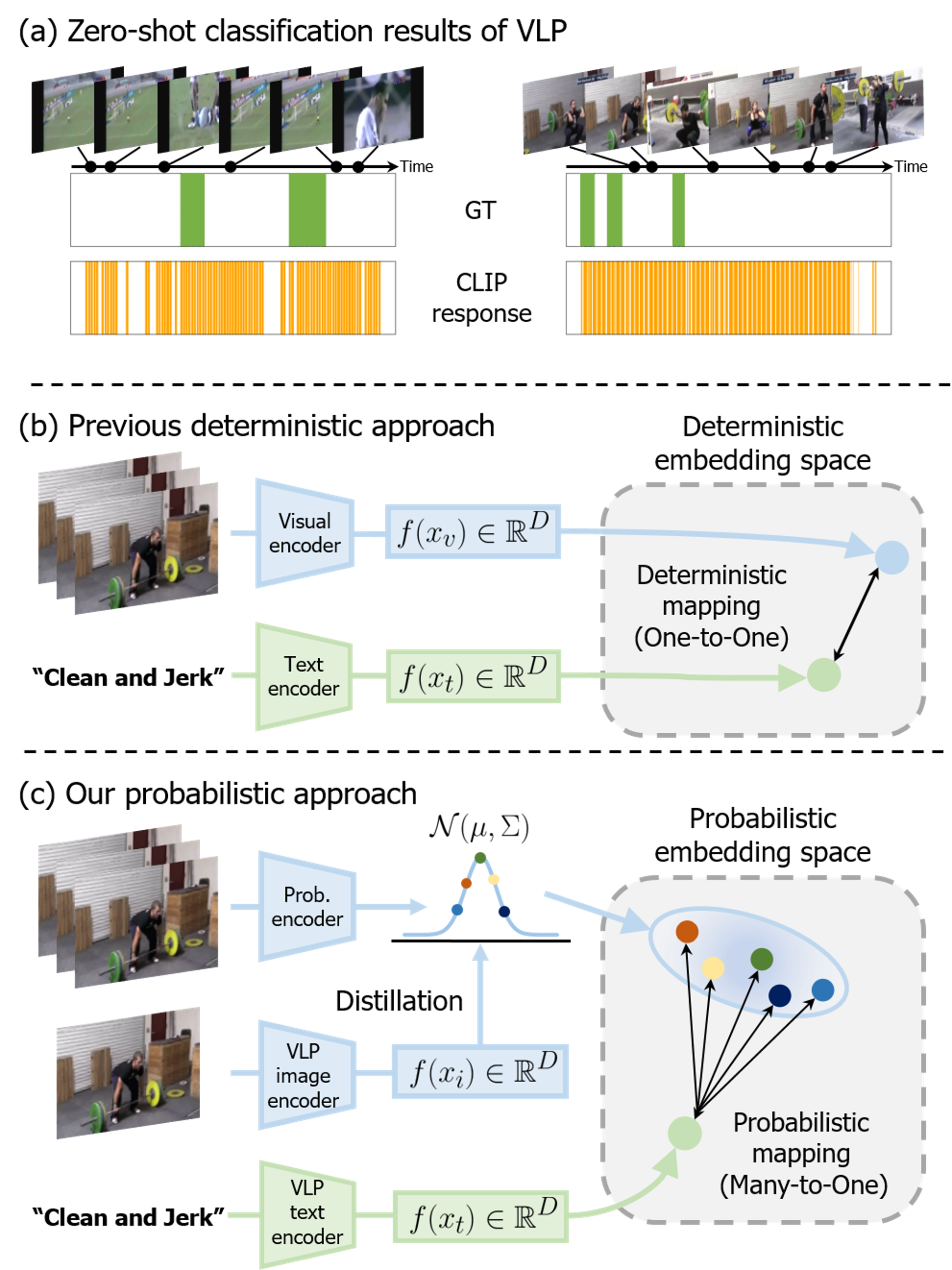
The key innovation in the paper is a probabilistic vision-language representation that the authors use to tackle weakly supervised temporal action localization.
The model consists of several components:
- Video Encoder: This encodes the visual features from the input video using a convolutional neural network.
- Text Encoder: This encodes textual descriptions of the actions using a language model like BERT.
- Multi-Modal Fusion: The visual and text encodings are combined into a shared representation using cross-attention mechanisms.
- Temporal Action Localization: This component uses the fused representation to predict the start and end times of actions in the video.
The model is trained in a weakly supervised manner, only requiring video-level action labels. It learns to align the visual and textual features, allowing it to localize actions without requiring temporal annotations.
Experiments show the approach outperforms prior weakly supervised methods on standard benchmarks for temporal action localization. The probabilistic formulation also enables zero-shot localization of novel actions not seen during training.
Critical Analysis
The paper presents a compelling approach that effectively leverages both visual and textual data to address the challenge of weakly supervised temporal action localization. The probabilistic modeling and multi-modal fusion techniques are technically sound and yield strong empirical results.
However, the authors do not deeply explore the limitations or potential issues with their method. For example, the approach may struggle with actions that are difficult to describe textually or have ambiguous temporal boundaries. Additionally, the reliance on pre-trained language models could make the system vulnerable to biases or mistakes in the text data.
Further research could investigate ways to enhance the pseudo-label quality or explore alternative multi-modal fusion strategies. Robustness to noisy or incomplete textual descriptions could also be an important area for improvement.
Overall, the paper makes a valuable contribution, but there remain opportunities to refine and extend the methodology to broaden its applicability and address potential shortcomings.
Conclusion
This paper introduces a novel probabilistic vision-language representation for weakly supervised temporal action localization in videos. By combining visual and textual data, the model can detect and localize actions without requiring detailed temporal annotations, making it more scalable and practical than previous approaches.
The technical innovations, including the multi-modal fusion and probabilistic formulation, yield strong empirical results on benchmark datasets. While the paper does not deeply explore limitations, the general approach represents an important step forward in addressing the challenging problem of weakly supervised action localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization
Geuntaek Lim, Hyunwoo Kim, Joonsoo Kim, Yukyung Choi
Weakly supervised temporal action localization (WTAL) aims to detect action instances in untrimmed videos using only video-level annotations. Since many existing works optimize WTAL models based on action classification labels, they encounter the task discrepancy problem (i.e., localization-by-classification). To tackle this issue, recent studies have attempted to utilize action category names as auxiliary semantic knowledge through vision-language pre-training (VLP). However, there are still areas where existing research falls short. Previous approaches primarily focused on leveraging textual information from language models but overlooked the alignment of dynamic human action and VLP knowledge in a joint space. Furthermore, the deterministic representation employed in previous studies struggles to capture fine-grained human motions. To address these problems, we propose a novel framework that aligns human action knowledge and VLP knowledge in a probabilistic embedding space. Moreover, we propose intra- and inter-distribution contrastive learning to enhance the probabilistic embedding space based on statistical similarities. Extensive experiments and ablation studies reveal that our method significantly outperforms all previous state-of-the-art methods. Code is available at https://github.com/sejong-rcv/PVLR.
Read more8/13/2024

0
STAT: Towards Generalizable Temporal Action Localization
Yangcen Liu, Ziyi Liu, Yuanhao Zhai, Wen Li, David Doerman, Junsong Yuan
Weakly-supervised temporal action localization (WTAL) aims to recognize and localize action instances with only video-level labels. Despite the significant progress, existing methods suffer from severe performance degradation when transferring to different distributions and thus may hardly adapt to real-world scenarios . To address this problem, we propose the Generalizable Temporal Action Localization task (GTAL), which focuses on improving the generalizability of action localization methods. We observed that the performance decline can be primarily attributed to the lack of generalizability to different action scales. To address this problem, we propose STAT (Self-supervised Temporal Adaptive Teacher), which leverages a teacher-student structure for iterative refinement. Our STAT features a refinement module and an alignment module. The former iteratively refines the model's output by leveraging contextual information and helps adapt to the target scale. The latter improves the refinement process by promoting a consensus between student and teacher models. We conduct extensive experiments on three datasets, THUMOS14, ActivityNet1.2, and HACS, and the results show that our method significantly improves the Baseline methods under the cross-distribution evaluation setting, even approaching the same-distribution evaluation performance.
Read more4/23/2024

0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024

0
Test-Time Zero-Shot Temporal Action Localization
Benedetta Liberatori, Alessandro Conti, Paolo Rota, Yiming Wang, Elisa Ricci
Zero-Shot Temporal Action Localization (ZS-TAL) seeks to identify and locate actions in untrimmed videos unseen during training. Existing ZS-TAL methods involve fine-tuning a model on a large amount of annotated training data. While effective, training-based ZS-TAL approaches assume the availability of labeled data for supervised learning, which can be impractical in some applications. Furthermore, the training process naturally induces a domain bias into the learned model, which may adversely affect the model's generalization ability to arbitrary videos. These considerations prompt us to approach the ZS-TAL problem from a radically novel perspective, relaxing the requirement for training data. To this aim, we introduce a novel method that performs Test-Time adaptation for Temporal Action Localization (T3AL). In a nutshell, T3AL adapts a pre-trained Vision and Language Model (VLM). T3AL operates in three steps. First, a video-level pseudo-label of the action category is computed by aggregating information from the entire video. Then, action localization is performed adopting a novel procedure inspired by self-supervised learning. Finally, frame-level textual descriptions extracted with a state-of-the-art captioning model are employed for refining the action region proposals. We validate the effectiveness of T3AL by conducting experiments on the THUMOS14 and the ActivityNet-v1.3 datasets. Our results demonstrate that T3AL significantly outperforms zero-shot baselines based on state-of-the-art VLMs, confirming the benefit of a test-time adaptation approach.
Read more4/12/2024