OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training

28
Sign in to get full access
Overview
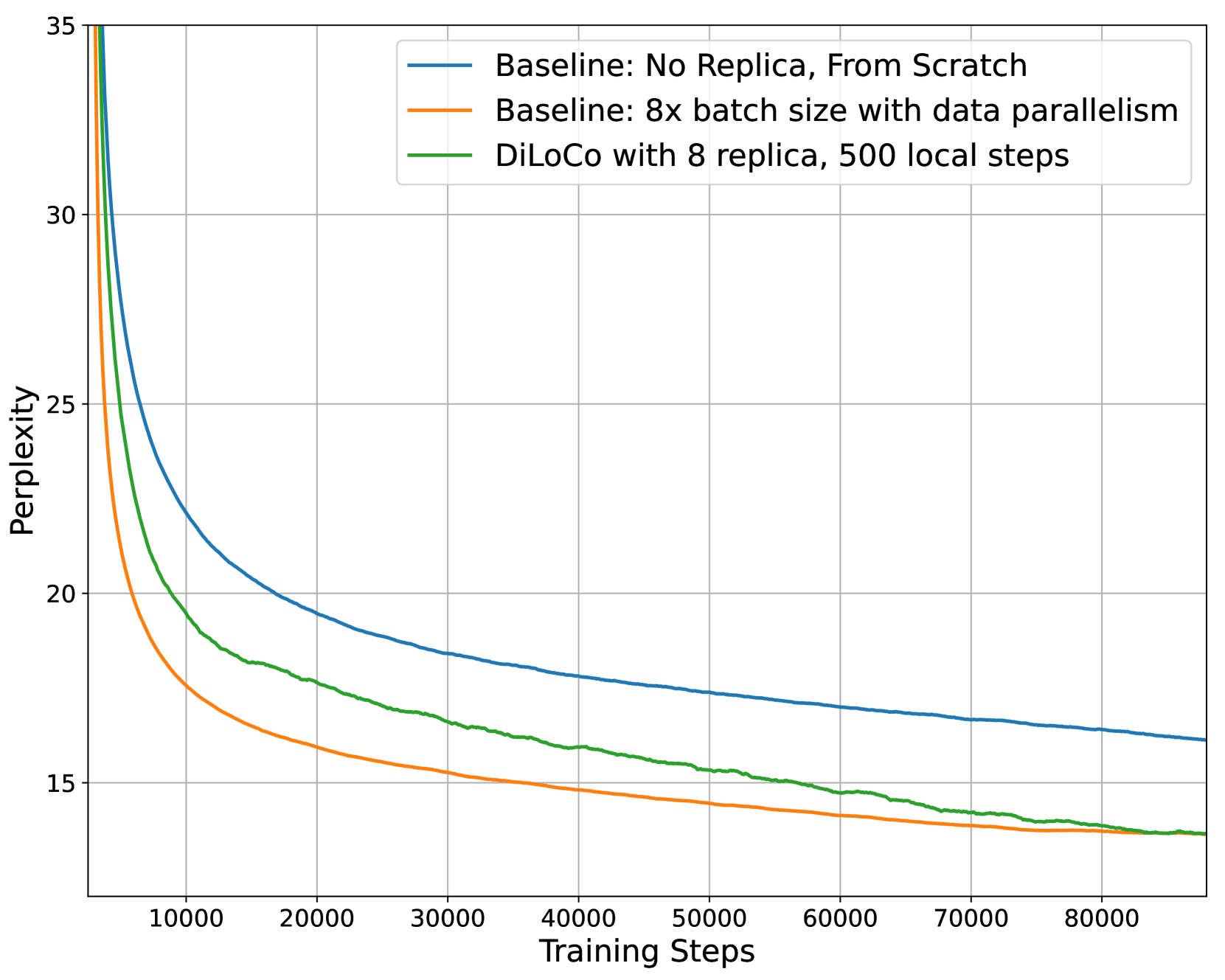
- OpenDiLoCo is an open-source framework for globally distributed low-communication training of machine learning models.
- It focuses on enabling efficient and scalable distributed training with minimal communication overhead between participants.
- The framework builds upon the DiLoCo and LOCO approaches, which leverage local updates and low-bit communication to reduce the communication burden.
Plain English Explanation
OpenDiLoCo is a tool that makes it easier to train large machine learning models across many different computers located around the world. Traditional approaches to distributed training often require a lot of communication between the computers, which can be slow and expensive. OpenDiLoCo tackles this problem by using techniques like local updates and low-bit communication to reduce the amount of data that needs to be shared between the computers. This allows the training to happen more efficiently, even when the computers are located far apart from each other. The end result is a trained model that can be used for various AI applications.
Technical Explanation
OpenDiLoCo builds upon the DiLoCo and LOCO approaches to enable globally distributed training with low communication overhead. The framework uses local updates, where each participant performs updates to the model using only their local data. These local updates are then communicated to the other participants using low-bit quantization techniques to reduce the amount of data that needs to be shared. Additionally, the framework includes mechanisms for synchronizing the global model state across the participants and handling stragglers or node failures.
Critical Analysis
The paper provides a thorough technical description of the OpenDiLoCo framework and its key components. However, it does not delve deeply into the potential limitations or challenges of the approach. For example, the paper does not discuss how the framework handles issues like data heterogeneity or the impact of varying network conditions on the training performance. Additionally, the paper does not provide a comprehensive evaluation of the framework's scalability and real-world applicability. Further research is needed to understand the practical implications and limitations of the OpenDiLoCo approach, especially in the context of diffuse-based locomotion control and other AI applications.
Conclusion
OpenDiLoCo is an open-source framework that aims to enable efficient and scalable distributed training of machine learning models with minimal communication overhead. By building upon the DiLoCo and LOCO approaches, the framework leverages local updates and low-bit communication to reduce the communication burden. While the technical details are well-explained, further research is needed to fully understand the framework's limitations and real-world applicability, especially in the context of emerging AI applications like diffuse-based locomotion control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
28
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
Sami Jaghouar, Jack Min Ong, Johannes Hagemann
OpenDiLoCo is an open-source implementation and replication of the Distributed Low-Communication (DiLoCo) training method for large language models. We provide a reproducible implementation of the DiLoCo experiments, offering it within a scalable, decentralized training framework using the Hivemind library. We demonstrate its effectiveness by training a model across two continents and three countries, while maintaining 90-95% compute utilization. Additionally, we conduct ablations studies focusing on the algorithm's compute efficiency, scalability in the number of workers and show that its gradients can be all-reduced using FP16 without any performance degradation. Furthermore, we scale OpenDiLoCo to 3x the size of the original work, demonstrating its effectiveness for billion parameter models.
Read more7/11/2024
📈
0
LoCo: Low-Bit Communication Adaptor for Large-scale Model Training
Xingyu Xie, Zhijie Lin, Kim-Chuan Toh, Pan Zhou
To efficiently train large-scale models, low-bit gradient communication compresses full-precision gradients on local GPU nodes into low-precision ones for higher gradient synchronization efficiency among GPU nodes. However, it often degrades training quality due to compression information loss. To address this, we propose the Low-bit Communication Adaptor (LoCo), which compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality. Specifically, LoCo designs a moving average of historical compensation errors to stably estimate concurrent compression error and then adopts it to compensate for the concurrent gradient compression, yielding a less lossless compression. This mechanism allows it to be compatible with general optimizers like Adam and sharding strategies like FSDP. Theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results show that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, e.g., improving Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
Read more7/8/2024

0
Communication-Efficient and Privacy-Preserving Decentralized Meta-Learning
Hansi Yang, James T. Kwok
Distributed learning, which does not require gathering training data in a central location, has become increasingly important in the big-data era. In particular, random-walk-based decentralized algorithms are flexible in that they do not need a central server trusted by all clients and do not require all clients to be active in all iterations. However, existing distributed learning algorithms assume that all learning clients share the same task. In this paper, we consider the more difficult meta-learning setting, in which different clients perform different (but related) tasks with limited training data. To reduce communication cost and allow better privacy protection, we propose LoDMeta (Local Decentralized Meta-learning) with the use of local auxiliary optimization parameters and random perturbations on the model parameter. Theoretical results are provided on both convergence and privacy analysis. Empirical results on a number of few-shot learning data sets demonstrate that LoDMeta has similar meta-learning accuracy as centralized meta-learning algorithms, but does not require gathering data from each client and is able to better protect data privacy for each client.
Read more6/21/2024

0
Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Feng Liang, Zhen Zhang, Haifeng Lu, Victor C. M. Leung, Yanyi Guo, Xiping Hu
With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
Read more4/10/2024