LoCo: Low-Bit Communication Adaptor for Large-scale Model Training

0
📈
Sign in to get full access
Overview
- Large-scale models require efficient gradient communication between GPU nodes to train effectively
- Low-bit gradient communication compresses full-precision gradients to improve synchronization efficiency
- However, this compression often leads to a loss of training quality due to information loss
Plain English Explanation
The paper proposes a solution called the Low-bit Communication Adaptor (LoCo) to address the shortcomings of low-bit gradient communication. LoCo compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality.
Specifically, LoCo uses a moving average of historical compensation errors to estimate the current compression error. It then uses this estimate to compensate for the gradient compression, resulting in a less lossy compression. This mechanism allows LoCo to be compatible with general optimizers like Adam and sharding strategies like FSDP.
The paper's theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results demonstrate that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, boosting Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
Technical Explanation
The key innovation of LoCo is its use of a moving average of historical compensation errors to estimate the current compression error. This allows LoCo to compensate for the gradient compression in a way that minimizes the loss of information, unlike traditional low-bit gradient communication methods.
Specifically, LoCo maintains a moving average of the errors introduced by the gradient compression in previous iterations. It then uses this estimate to compensate the current gradients before they are compressed, effectively canceling out the expected compression error. This mechanism ensures that the compressed gradients sent to other GPU nodes are close to the original full-precision gradients, improving communication efficiency without compromising training quality.
LoCo's design allows it to be compatible with a wide range of optimizers and sharding strategies. The paper's theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not slow down their convergence on nonconvex problems.
The experimental results presented in the paper demonstrate the effectiveness of LoCo across different large-scale model training frameworks. On tasks like training large language models like LLAMAs and Mixture-of-Experts (MoE) models, LoCo was able to improve the training speed of Adam by 14% to 40% without any performance degradation.
Critical Analysis
The paper provides a thorough analysis of the LoCo method and its performance on large-scale model training tasks. However, it is important to note that the effectiveness of LoCo may depend on the specific characteristics of the models and tasks being trained.
The paper does not explore the potential limitations of LoCo, such as its performance on different types of models or its scalability to extremely large-scale training scenarios. Additionally, the paper does not discuss the computational overhead or memory requirements of the LoCo method, which could be important considerations in real-world deployments.
Further research could investigate the broader applicability of LoCo, its performance on a wider range of models and tasks, and any potential trade-offs or limitations that were not addressed in this paper.
Conclusion
The Low-bit Communication Adaptor (LoCo) proposed in this paper offers a promising solution to the challenge of efficient gradient communication in large-scale model training. By compensating gradients before compression and leveraging a moving average of historical compensation errors, LoCo is able to improve communication efficiency without compromising training quality.
The paper's theoretical and experimental results demonstrate the effectiveness of LoCo across various large-scale model training frameworks, with significant improvements in training speed for optimizers like Adam. As the demand for ever-larger and more complex models continues to grow, innovations like LoCo will play a crucial role in enabling efficient and scalable training of these models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
LoCo: Low-Bit Communication Adaptor for Large-scale Model Training
Xingyu Xie, Zhijie Lin, Kim-Chuan Toh, Pan Zhou
To efficiently train large-scale models, low-bit gradient communication compresses full-precision gradients on local GPU nodes into low-precision ones for higher gradient synchronization efficiency among GPU nodes. However, it often degrades training quality due to compression information loss. To address this, we propose the Low-bit Communication Adaptor (LoCo), which compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality. Specifically, LoCo designs a moving average of historical compensation errors to stably estimate concurrent compression error and then adopts it to compensate for the concurrent gradient compression, yielding a less lossless compression. This mechanism allows it to be compatible with general optimizers like Adam and sharding strategies like FSDP. Theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results show that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, e.g., improving Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
Read more7/8/2024
0
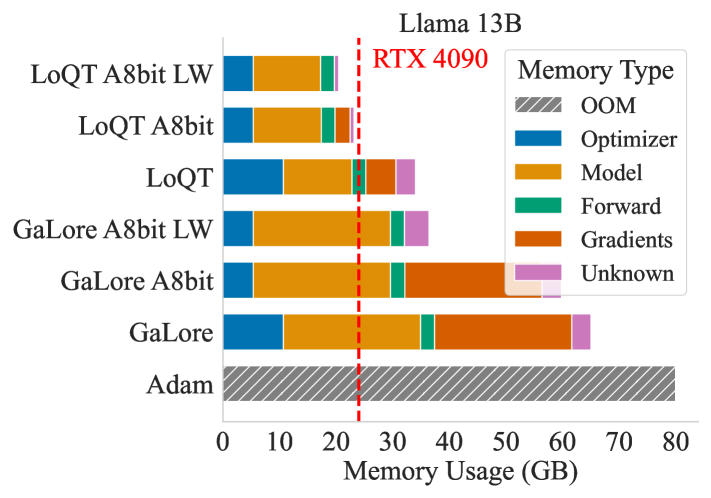
LoQT: Low Rank Adapters for Quantized Training
Sebastian Loeschcke, Mads Toftrup, Michael J. Kastoryano, Serge Belongie, V'esteinn Sn{ae}bjarnarson
Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Read more9/10/2024

0
LoCoCo: Dropping In Convolutions for Long Context Compression
Ruisi Cai, Yuandong Tian, Zhangyang Wang, Beidi Chen
This paper tackles the memory hurdle of processing long context sequences in Large Language Models (LLMs), by presenting a novel approach, Dropping In Convolutions for Long Context Compression (LoCoCo). LoCoCo employs only a fixed-size Key-Value (KV) cache, and can enhance efficiency in both inference and fine-tuning stages. Diverging from prior methods that selectively drop KV pairs based on heuristics, LoCoCo leverages a data-driven adaptive fusion technique, blending previous KV pairs with incoming tokens to minimize the loss of contextual information and ensure accurate attention modeling. This token integration is achieved through injecting one-dimensional convolutional kernels that dynamically calculate mixing weights for each KV cache slot. Designed for broad compatibility with existing LLM frameworks, LoCoCo allows for straightforward drop-in integration without needing architectural modifications, while incurring minimal tuning overhead. Experiments demonstrate that LoCoCo maintains consistently outstanding performance across various context lengths and can achieve a high context compression rate during both inference and fine-tuning phases. During inference, we successfully compressed up to 3482 tokens into a 128-size KV cache, while retaining comparable performance to the full sequence - an accuracy improvement of up to 0.2791 compared to baselines at the same cache size. During post-training tuning, we also effectively extended the context length from 4K to 32K using a KV cache of fixed size 512, achieving performance similar to fine-tuning with entire sequences.
Read more6/11/2024
28
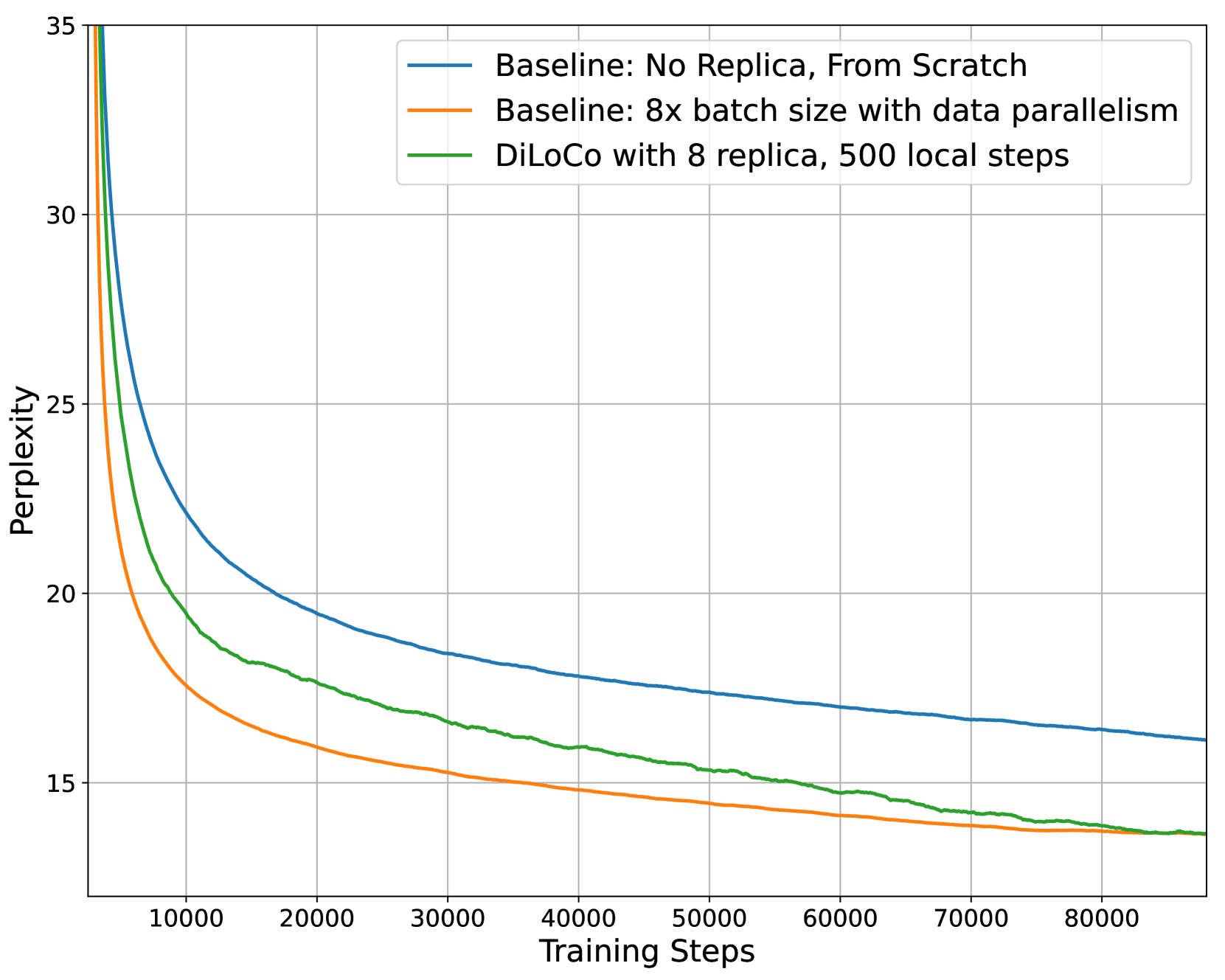
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
Sami Jaghouar, Jack Min Ong, Johannes Hagemann
OpenDiLoCo is an open-source implementation and replication of the Distributed Low-Communication (DiLoCo) training method for large language models. We provide a reproducible implementation of the DiLoCo experiments, offering it within a scalable, decentralized training framework using the Hivemind library. We demonstrate its effectiveness by training a model across two continents and three countries, while maintaining 90-95% compute utilization. Additionally, we conduct ablations studies focusing on the algorithm's compute efficiency, scalability in the number of workers and show that its gradients can be all-reduced using FP16 without any performance degradation. Furthermore, we scale OpenDiLoCo to 3x the size of the original work, demonstrating its effectiveness for billion parameter models.
Read more7/11/2024