OpenDlign: Enhancing Open-World 3D Learning with Depth-Aligned Images
2404.16538
0
0
💬
Abstract
Recent open-world 3D representation learning methods using Vision-Language Models (VLMs) to align 3D data with image-text information have shown superior 3D zero-shot performance. However, CAD-rendered images for this alignment often lack realism and texture variation, compromising alignment robustness. Moreover, the volume discrepancy between 3D and 2D pretraining datasets highlights the need for effective strategies to transfer the representational abilities of VLMs to 3D learning. In this paper, we present OpenDlign, a novel open-world 3D model using depth-aligned images generated from a diffusion model for robust multimodal alignment. These images exhibit greater texture diversity than CAD renderings due to the stochastic nature of the diffusion model. By refining the depth map projection pipeline and designing depth-specific prompts, OpenDlign leverages rich knowledge in pre-trained VLM for 3D representation learning with streamlined fine-tuning. Our experiments show that OpenDlign achieves high zero-shot and few-shot performance on diverse 3D tasks, despite only fine-tuning 6 million parameters on a limited ShapeNet dataset. In zero-shot classification, OpenDlign surpasses previous models by 8.0% on ModelNet40 and 16.4% on OmniObject3D. Additionally, using depth-aligned images for multimodal alignment consistently enhances the performance of other state-of-the-art models.
Create account to get full access
Overview
- Recent advances in Vision and Language Models (VLMs) have improved open-world 3D representation, enabling 3D zero-shot capability in unseen categories.
- Existing open-world methods pre-train an extra 3D encoder to align features from 3D data (e.g., depth maps or point clouds) with CAD-rendered images and corresponding texts.
- However, the limited color and texture variations in CAD images can compromise the alignment robustness, and the volume discrepancy between pre-training datasets of the 3D encoder and VLM leads to sub-optimal 2D to 3D knowledge transfer.
Plain English Explanation
To understand 3D objects in the real world, researchers have developed advanced Vision and Language Models (VLMs) that can recognize and describe 3D objects, even those they've never seen before. These models are trained on a combination of 2D images and text descriptions.
However, the current approach has some limitations. The 3D data used to train these models, such as depth maps or point clouds, is often paired with computer-generated (CAD) images, which lack the rich color and texture details of real-world objects. This can make it harder for the model to accurately align the 2D image features with the 3D data.
Additionally, the datasets used to train the 3D encoder and the VLM are often different, which can lead to a mismatch in the knowledge they've acquired, reducing the model's ability to effectively transfer information between the 2D and 3D domains.
Technical Explanation
To address these issues, the researchers propose a new framework called OpenDlign. Instead of using CAD-rendered images, OpenDlign generates depth-aligned images from point cloud-projected depth maps. These generated images provide rich, realistic color and texture diversity while preserving the geometric and semantic consistency with the depth maps.
OpenDlign also optimizes the depth map projection and integrates depth-specific text prompts, which helps the model better adapt the 2D VLM knowledge for efficient 3D learning and fine-tuning.
The researchers' experiments show that OpenDlign significantly outperforms existing benchmarks in zero-shot and few-shot 3D tasks, exceeding prior scores by 8.0% on ModelNet40 and 16.4% on OmniObject3D with just 6 million tuned parameters. Additionally, integrating the generated depth-aligned images into existing 3D learning pipelines consistently improves their performance.
Critical Analysis
The paper presents a promising solution to the limitations of existing open-world 3D representation methods. By generating depth-aligned images with realistic color and texture, OpenDlign addresses the issue of alignment robustness caused by the limited visual fidelity of CAD-rendered images.
However, the paper does not discuss the potential computational overhead or training complexity introduced by the image generation process. Additionally, the researchers could have explored the impact of different depth map projection techniques or the generalization of the method to other types of 3D data, such as meshes or volumetric representations.
Further research could also investigate the transferability of the learned representations to downstream tasks beyond zero-shot and few-shot learning, such as 3D scene reconstruction or cross-modal self-training.
Conclusion
The OpenDlign framework presents a innovative approach to improving 3D zero-shot learning by leveraging depth-aligned images generated from point cloud-projected depth maps. This technique addresses the limitations of existing methods by providing richer visual information and better aligning the 2D and 3D data domains. The promising results demonstrate the potential of this approach to advance open-world 3D representation and enable more robust and versatile 3D understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
Weiguang Zhao, Guanyu Yang, Rui Zhang, Chenru Jiang, Chaolong Yang, Yuyao Yan, Amir Hussain, Kaizhu Huang
0
0
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
4/17/2024

Cross-Modal Self-Training: Aligning Images and Pointclouds to Learn Classification without Labels
Amaya Dharmasiri, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan
0
0
Large-scale vision 2D vision language models, such as CLIP can be aligned with a 3D encoder to learn generalizable (open-vocabulary) 3D vision models. However, current methods require supervised pre-training for such alignment, and the performance of such 3D zero-shot models remains sub-optimal for real-world adaptation. In this work, we propose an optimization framework: Cross-MoST: Cross-Modal Self-Training, to improve the label-free classification performance of a zero-shot 3D vision model by simply leveraging unlabeled 3D data and their accompanying 2D views. We propose a student-teacher framework to simultaneously process 2D views and 3D point clouds and generate joint pseudo labels to train a classifier and guide cross-model feature alignment. Thereby we demonstrate that 2D vision language models such as CLIP can be used to complement 3D representation learning to improve classification performance without the need for expensive class annotations. Using synthetic and real-world 3D datasets, we further demonstrate that Cross-MoST enables efficient cross-modal knowledge exchange resulting in both image and point cloud modalities learning from each other's rich representations.
4/17/2024
🤔
Language-Image Models with 3D Understanding
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krahenbuhl, Yan Wang, Marco Pavone
0
0
Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
5/7/2024
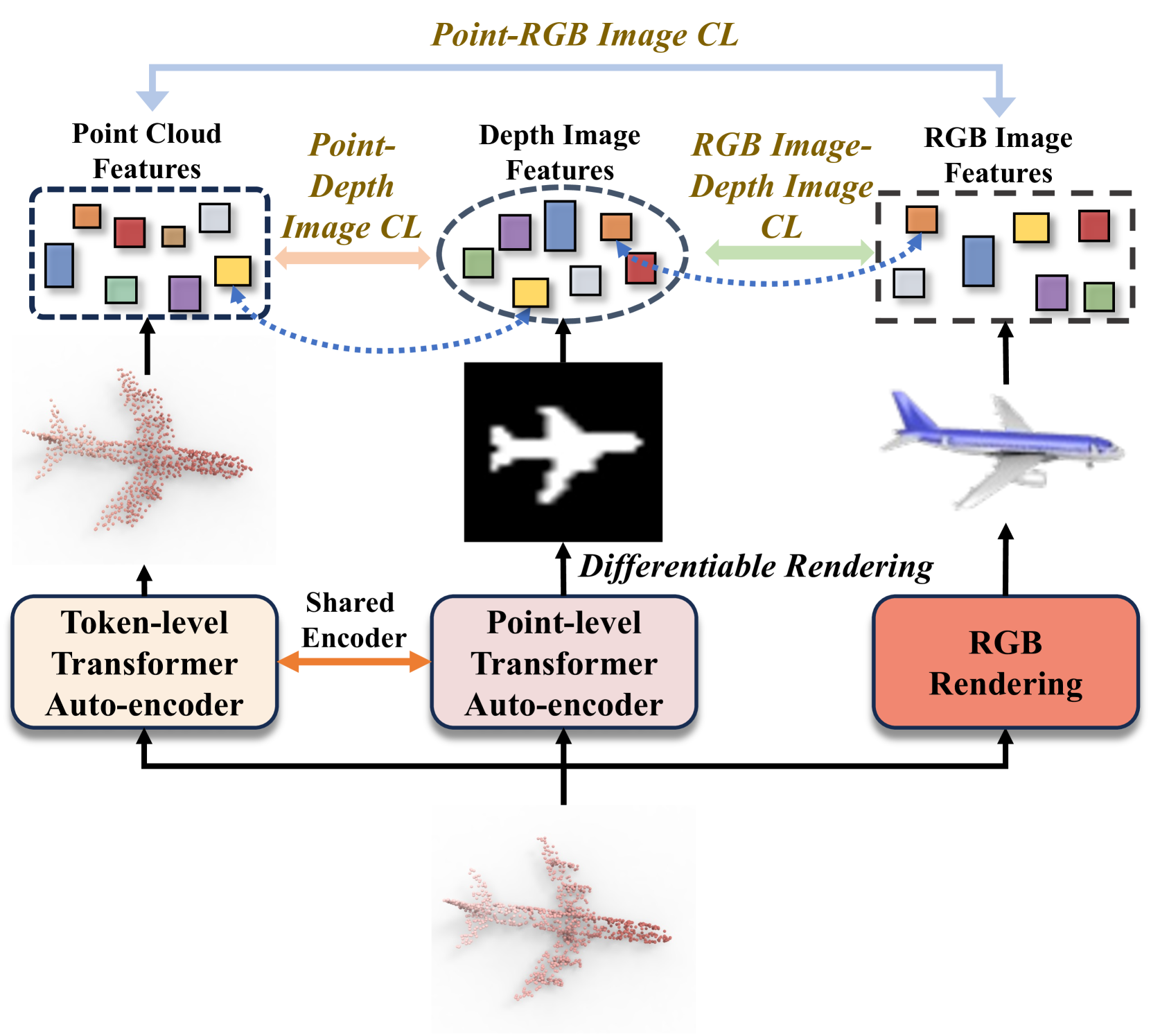
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
0
0
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
4/23/2024