Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
2312.07039
0
0
Abstract
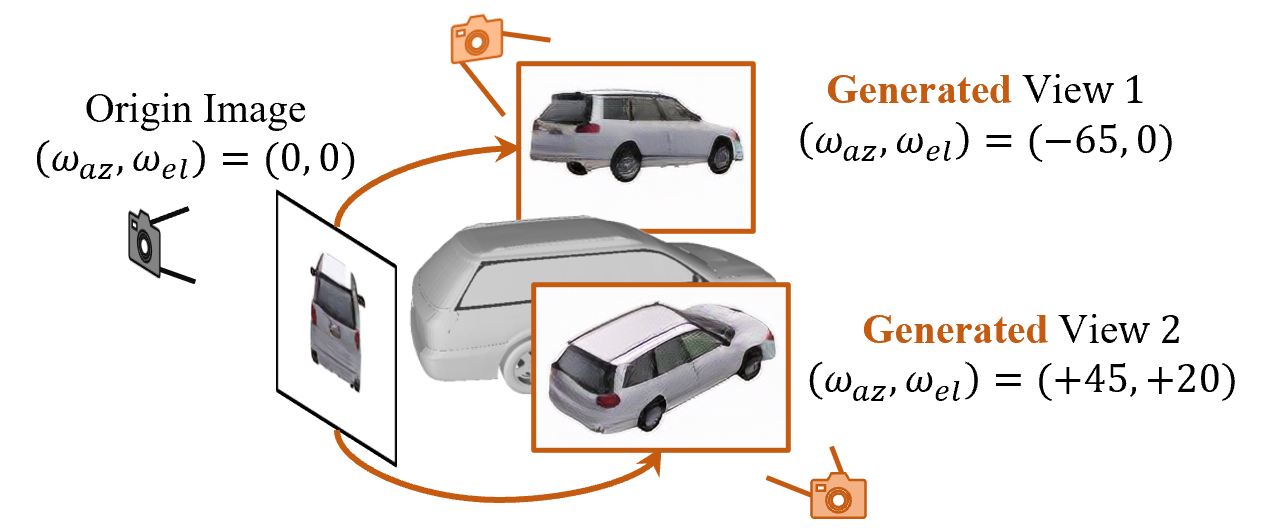
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
Create account to get full access
Overview
- Proposes a novel method called Diff-OP3D for zero-shot 3D pose classification of objects
- Leverages a 2D diffusion model to learn a rich representation that can be transferred to 3D pose estimation
- Enables zero-shot classification of 3D poses for objects not seen during training
Plain English Explanation
The paper introduces a new approach called Diff-OP3D that allows for classifying the 3D poses of objects without ever seeing those objects before. This is known as zero-shot learning.
The key insight is to use a 2D diffusion model - a type of machine learning model that can generate realistic images - to learn a powerful representation of object appearances. This representation can then be transferred to the task of 3D pose estimation, enabling the model to recognize the 3D poses of novel objects.
The advantage of this approach is that it avoids the need for costly 3D pose annotations during training. Instead, the model can leverage abundant 2D image data to learn a rich visual understanding that generalizes to 3D. This makes the system much more flexible and scalable compared to traditional 3D pose estimation methods.
Technical Explanation
The paper proposes the Diff-OP3D framework, which bridges 2D diffusion models and 3D pose estimation to enable zero-shot 3D pose classification. The core idea is to leverage the powerful representation learning capabilities of 2D diffusion models and transfer the learned features to the 3D pose estimation task.
The Diff-OP3D model consists of two main components: a 2D diffusion model and a 3D pose classifier. The diffusion model is trained on 2D image data to learn a rich visual representation. This representation is then extracted and fed into the 3D pose classifier, which is trained to map the features to the corresponding 3D poses.
Crucially, the 3D pose classifier is trained in a zero-shot manner, meaning it is able to recognize the poses of objects that were not seen during training. This is enabled by the generalized visual representation learned by the diffusion model, which captures high-level object properties rather than just memorizing specific instances.
The authors demonstrate the effectiveness of Diff-OP3D on several 3D pose estimation benchmarks, showing strong performance compared to other zero-shot and few-shot methods. The results highlight the benefits of bridging 2D and 3D representations for improved generalization and data efficiency.
Critical Analysis
The Diff-OP3D approach presents an interesting and promising direction for zero-shot 3D pose estimation. By leveraging the representation learning capabilities of 2D diffusion models, the method is able to circumvent the need for costly 3D annotations during training, which is a significant advantage.
However, the paper does not provide a thorough analysis of the limitations and potential drawbacks of the approach. For example, it is unclear how well Diff-OP3D would scale to more complex and diverse object categories, or how sensitive the performance is to the quality and diversity of the 2D training data.
Additionally, the authors do not explore the potential trade-offs between the generalization capabilities enabled by the zero-shot learning approach and the potential loss of accuracy compared to fully supervised 3D pose estimation methods. Further research is needed to understand the broader applicability and limitations of the Diff-OP3D framework.
Conclusion
The Diff-OP3D paper presents a novel and promising approach for zero-shot 3D pose estimation. By bridging 2D diffusion models and 3D pose classification, the method is able to leverage abundant 2D image data to learn a rich visual representation that can be transferred to the 3D domain.
This breakthrough has the potential to significantly impact the field of 3D object understanding, as it reduces the need for costly 3D annotations and enables more flexible and scalable pose estimation systems. The authors demonstrate strong empirical results, but further research is needed to fully understand the limitations and broader implications of the Diff-OP3D framework.
Overall, this work represents an important step forward in the quest for more efficient and generalizable 3D pose estimation methods, with important implications for a wide range of applications, from robotics to augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
FreeZe: Training-free zero-shot 6D pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, Fabio Poiesi
0
0
Estimating the 6D pose of objects unseen during training is highly desirable yet challenging. Zero-shot object 6D pose estimation methods address this challenge by leveraging additional task-specific supervision provided by large-scale, photo-realistic synthetic datasets. However, their performance heavily depends on the quality and diversity of rendered data and they require extensive training. In this work, we show how to tackle the same task but without training on specific data. We propose FreeZe, a novel solution that harnesses the capabilities of pre-trained geometric and vision foundation models. FreeZe leverages 3D geometric descriptors learned from unrelated 3D point clouds and 2D visual features learned from web-scale 2D images to generate discriminative 3D point-level descriptors. We then estimate the 6D pose of unseen objects by 3D registration based on RANSAC. We also introduce a novel algorithm to solve ambiguous cases due to geometrically symmetric objects that is based on visual features. We comprehensively evaluate FreeZe across the seven core datasets of the BOP Benchmark, which include over a hundred 3D objects and 20,000 images captured in various scenarios. FreeZe consistently outperforms all state-of-the-art approaches, including competitors extensively trained on synthetic 6D pose estimation data. Code will be publicly available at https://andreacaraffa.github.io/freeze.
4/4/2024
Learning a Category-level Object Pose Estimator without Pose Annotations
Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
0
0
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
4/9/2024

ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Wufei Ma, Guanning Zeng, Guofeng Zhang, Qihao Liu, Letian Zhang, Adam Kortylewski, Yaoyao Liu, Alan Yuille
0
0
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
6/17/2024
💬
OpenDlign: Enhancing Open-World 3D Learning with Depth-Aligned Images
Ye Mao, Junpeng Jing, Krystian Mikolajczyk
0
0
Recent open-world 3D representation learning methods using Vision-Language Models (VLMs) to align 3D data with image-text information have shown superior 3D zero-shot performance. However, CAD-rendered images for this alignment often lack realism and texture variation, compromising alignment robustness. Moreover, the volume discrepancy between 3D and 2D pretraining datasets highlights the need for effective strategies to transfer the representational abilities of VLMs to 3D learning. In this paper, we present OpenDlign, a novel open-world 3D model using depth-aligned images generated from a diffusion model for robust multimodal alignment. These images exhibit greater texture diversity than CAD renderings due to the stochastic nature of the diffusion model. By refining the depth map projection pipeline and designing depth-specific prompts, OpenDlign leverages rich knowledge in pre-trained VLM for 3D representation learning with streamlined fine-tuning. Our experiments show that OpenDlign achieves high zero-shot and few-shot performance on diverse 3D tasks, despite only fine-tuning 6 million parameters on a limited ShapeNet dataset. In zero-shot classification, OpenDlign surpasses previous models by 8.0% on ModelNet40 and 16.4% on OmniObject3D. Additionally, using depth-aligned images for multimodal alignment consistently enhances the performance of other state-of-the-art models.
6/26/2024