OpenPack: A Large-scale Dataset for Recognizing Packaging Works in IoT-enabled Logistic Environments

0
✨
Sign in to get full access
Overview
- Existing datasets for work activity recognition in industrial settings are limited due to challenges in collecting realistic data.
- This study introduces a new large-scale dataset called OpenPack for packaging work recognition, containing 53.8 hours of multimodal sensor data from 16 subjects.
- The dataset is intended to contribute to the sensor-based action/activity recognition research community by providing challenging tasks.
Plain English Explanation
In the real world, it can be difficult to collect useful data on how people do their jobs, especially in industrial settings. This makes it hard for researchers to develop and test new methods for recognizing work activities using sensor data. To address this challenge, the researchers behind this study created a new dataset called OpenPack.
OpenPack contains over 50 hours of sensor data recorded while 16 people with different levels of experience did packaging work. The data includes things like acceleration measurements, video of hand movements, and readings from handheld scanners. This multimodal data provides a rich source for researchers to explore techniques for recognizing complex work activities in industrial settings.
By making this dataset publicly available, the researchers hope to advance the field of sensor-based activity recognition, which could lead to new applications for monitoring and improving industrial workflows. The dataset presents challenging real-world problems for the research community to tackle.
Technical Explanation
The researchers created the OpenPack dataset to address the lack of publicly available sensor data for work activity recognition in industrial domains. Collecting realistic data from industrial sites is difficult, as it requires close collaboration with these facilities.
OpenPack contains 53.8 hours of multimodal sensor data from 16 distinct subjects with varying levels of packaging work experience. The data includes:
- Acceleration data
- Keypoint data (tracking hand/body movements)
- Depth images
- Readings from IoT-enabled devices like handheld barcode scanners
The researchers applied state-of-the-art human activity recognition techniques to the OpenPack dataset and identified areas for future work in complex work activity recognition studies.
Critical Analysis
The OpenPack dataset represents an important contribution to the field of sensor-based activity recognition, as it provides a realistic and challenging benchmark for industrial work activities. By including multimodal sensor data, the dataset allows researchers to explore the combination of different data sources for improved recognition performance.
However, the dataset is limited to packaging work and may not generalize to other industrial domains. Additionally, the paper does not provide a detailed analysis of the dataset's limitations or potential biases in the data collection process.
Future research could explore applying the OpenPack dataset to emerging sensor technologies or developing novel activity recognition methods specifically designed for complex industrial workflows.
Conclusion
The OpenPack dataset represents a significant step forward in providing realistic sensor data for work activity recognition research in industrial settings. By making this dataset publicly available, the researchers have created new opportunities for the development of intelligent systems that can monitor and optimize industrial workflows. The dataset's challenges will push the research community to develop more robust and versatile activity recognition techniques, ultimately leading to improvements in industrial efficiency and productivity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
OpenPack: A Large-scale Dataset for Recognizing Packaging Works in IoT-enabled Logistic Environments
Naoya Yoshimura, Jaime Morales, Takuya Maekawa, Takahiro Hara
Unlike human daily activities, existing publicly available sensor datasets for work activity recognition in industrial domains are limited by difficulties in collecting realistic data as close collaboration with industrial sites is required. This also limits research on and development of methods for industrial applications. To address these challenges and contribute to research on machine recognition of work activities in industrial domains, in this study, we introduce a new large-scale dataset for packaging work recognition called OpenPack. OpenPack contains 53.8 hours of multimodal sensor data, including acceleration data, keypoints, depth images, and readings from IoT-enabled devices (e.g., handheld barcode scanners), collected from 16 distinct subjects with different levels of packaging work experience. We apply state-of-the-art human activity recognition techniques to the dataset and provide future directions of complex work activity recognition studies in the pervasive computing community based on the results. We believe that OpenPack will contribute to the sensor-based action/activity recognition community by providing challenging tasks. The OpenPack dataset is available at https://open-pack.github.io.
Read more4/23/2024
👁️
0
Self-supervised Learning for Human Activity Recognition Using 700,000 Person-days of Wearable Data
Hang Yuan, Shing Chan, Andrew P. Creagh, Catherine Tong, Aidan Acquah, David A. Clifton, Aiden Doherty
Advances in deep learning for human activity recognition have been relatively limited due to the lack of large labelled datasets. In this study, we leverage self-supervised learning techniques on the UK-Biobank activity tracker dataset--the largest of its kind to date--containing more than 700,000 person-days of unlabelled wearable sensor data. Our resulting activity recognition model consistently outperformed strong baselines across seven benchmark datasets, with an F1 relative improvement of 2.5%-100% (median 18.4%), the largest improvements occurring in the smaller datasets. In contrast to previous studies, our results generalise across external datasets, devices, and environments. Our open-source model will help researchers and developers to build customisable and generalisable activity classifiers with high performance.
Read more6/21/2024
0
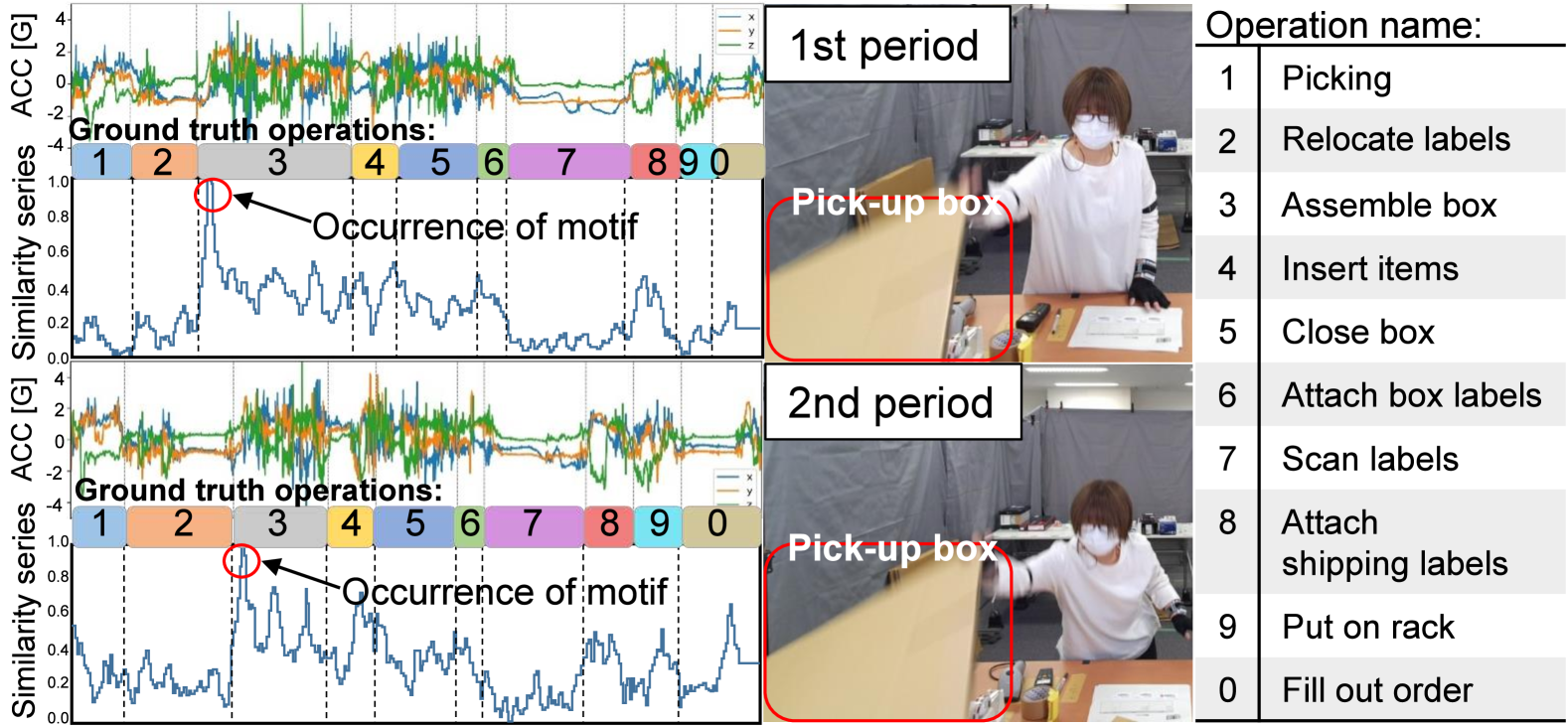
Preliminary Investigation of SSL for Complex Work Activity Recognition in Industrial Domain via MoIL
Qingxin Xia, Takuya Maekawa, Jaime Morales, Takahiro Hara, Hirotomo Oshima, Masamitsu Fukuda, Yasuo Namioka
In this study, we investigate a new self-supervised learning (SSL) approach for complex work activity recognition using wearable sensors. Owing to the cost of labeled sensor data collection, SSL methods for human activity recognition (HAR) that effectively use unlabeled data for pretraining have attracted attention. However, applying prior SSL to complex work activities such as packaging works is challenging because the observed data vary considerably depending on situations such as the number of items to pack and the size of the items in the case of packaging works. In this study, we focus on sensor data corresponding to characteristic and necessary actions (sensor data motifs) in a specific activity such as a stretching packing tape action in an assembling a box activity, and textcolor{black}{try} to train a neural network in self-supervised learning so that it identifies occurrences of the characteristic actions, i.e., Motif Identification Learning (MoIL). The feature extractor in the network is used in the downstream task, i.e., work activity recognition, enabling precise activity recognition containing characteristic actions with limited labeled training data. The MoIL approach was evaluated on real-world work activity data and it achieved state-of-the-art performance under limited training labels.
Read more4/23/2024

0
TSAK: Two-Stage Semantic-Aware Knowledge Distillation for Efficient Wearable Modality and Model Optimization in Manufacturing Lines
Hymalai Bello, Daniel Gei{ss}ler, Sungho Suh, Bo Zhou, Paul Lukowicz
Smaller machine learning models, with less complex architectures and sensor inputs, can benefit wearable sensor-based human activity recognition (HAR) systems in many ways, from complexity and cost to battery life. In the specific case of smart factories, optimizing human-robot collaboration hinges on the implementation of cutting-edge, human-centric AI systems. To this end, workers' activity recognition enables accurate quantification of performance metrics, improving efficiency holistically. We present a two-stage semantic-aware knowledge distillation (KD) approach, TSAK, for efficient, privacy-aware, and wearable HAR in manufacturing lines, which reduces the input sensor modalities as well as the machine learning model size, while reaching similar recognition performance as a larger multi-modal and multi-positional teacher model. The first stage incorporates a teacher classifier model encoding attention, causal, and combined representations. The second stage encompasses a semantic classifier merging the three representations from the first stage. To evaluate TSAK, we recorded a multi-modal dataset at a smart factory testbed with wearable and privacy-aware sensors (IMU and capacitive) located on both workers' hands. In addition, we evaluated our approach on OpenPack, the only available open dataset mimicking the wearable sensor placements on both hands in the manufacturing HAR scenario. We compared several KD strategies with different representations to regulate the training process of a smaller student model. Compared to the larger teacher model, the student model takes fewer sensor channels from a single hand, has 79% fewer parameters, runs 8.88 times faster, and requires 96.6% less computing power (FLOPS).
Read more8/27/2024