Preliminary Investigation of SSL for Complex Work Activity Recognition in Industrial Domain via MoIL

0
Sign in to get full access
Overview
- Investigates self-supervised learning (SSL) for complex work activity recognition in the industrial domain
- Proposes a novel SSL method called Motif Identification Learning (MoIL) for wearable sensor data
- Evaluates MoIL on a challenging industrial dataset and compares it to supervised and other SSL methods
Plain English Explanation
This research paper explores a new way to recognize complex work activities in an industrial setting using data from wearable sensors, such as cameras or motion trackers. Traditional methods for this task often require a lot of labeled training data, which can be time-consuming and expensive to collect. The researchers propose a self-supervised learning (SSL) approach called Motif Identification Learning (MoIL) that can learn useful representations from the sensor data without needing as much labeled data.
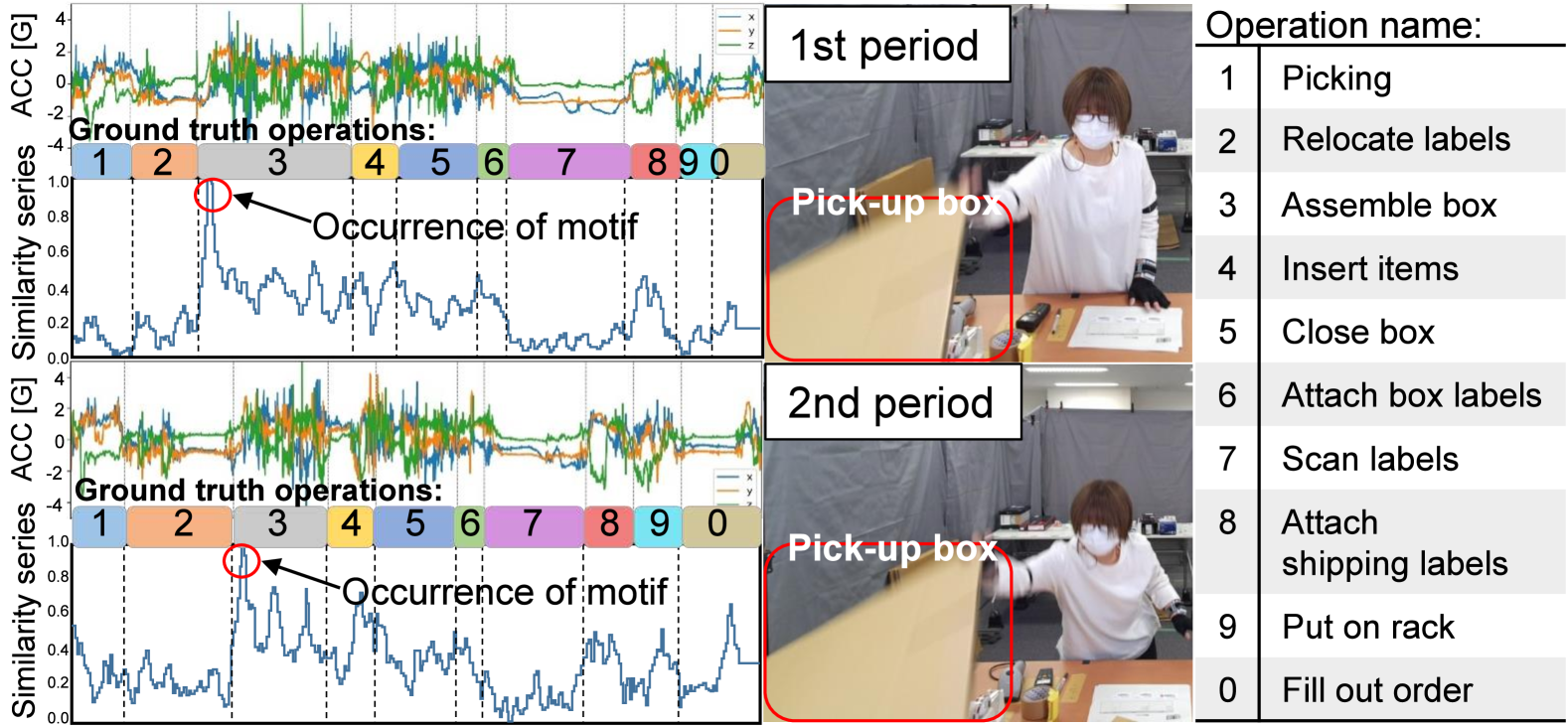
The core idea behind MoIL is to look for "motifs" or repeated patterns in the sensor data, and then use these motifs as a way to pre-train the model before fine-tuning it on the task of activity recognition. This allows the model to learn important features of the data in a more efficient and data-efficient way, without relying as heavily on having lots of labeled examples.
The researchers evaluate MoIL on a challenging industrial dataset and compare its performance to both supervised learning methods and other SSL approaches. Their results suggest that MoIL can achieve competitive or even better performance than these other methods, while requiring less labeled data to train effectively.
Technical Explanation
The paper proposes a novel self-supervised learning (SSL) method called Motif Identification Learning (MoIL) for complex work activity recognition from wearable sensor data in the industrial domain. MoIL builds on the idea of discovering and learning useful "motifs" or recurring patterns in the sensor data, which can then be used as a pre-training step before fine-tuning the model on the downstream activity recognition task.
The authors first extract candidate motifs from the unlabeled sensor data using a sliding window approach. They then train a model to classify these motifs, incentivizing the model to learn representations that capture the key features of the motifs. This pre-trained model is then fine-tuned on the labeled activity recognition dataset, allowing it to leverage the learned motif representations to perform the task more effectively.
The researchers evaluate MoIL on the challenging OpenPack dataset, which contains wearable sensor data for complex packaging work activities. They compare MoIL's performance to both supervised learning baselines as well as other SSL methods like contrastive learning and dropout-based regularization. Their results show that MoIL can achieve competitive or even better performance than these other approaches, while requiring less labeled data to train effectively.
Critical Analysis
The paper presents a promising approach to tackling the challenge of human activity recognition from wearable sensor data in the industrial domain, where labeled data can be scarce and expensive to obtain. The authors' use of self-supervised learning to discover and leverage motifs in the sensor data is an innovative strategy that allows the model to learn useful representations in a more data-efficient manner.
However, the paper does not fully address some potential limitations of the MoIL approach. For example, the motif extraction process could be sensitive to noise or irrelevant variations in the sensor data, which could limit the quality of the learned representations. Additionally, the paper does not explore the robustness of MoIL to different sensor modalities or industrial settings, which would be important for assessing its broader applicability.
Further research could also investigate ways to further improve the data efficiency of MoIL, such as by incorporating techniques from few-shot learning or meta-learning. Exploring how MoIL could be combined with other SSL methods, such as contrastive learning, may also lead to even stronger performance.
Conclusion
This paper presents a novel self-supervised learning approach called Motif Identification Learning (MoIL) for complex work activity recognition in the industrial domain. MoIL leverages the discovery and learning of recurring patterns or "motifs" in wearable sensor data to enable more data-efficient model training, without relying as heavily on labeled examples.
The researchers' evaluation of MoIL on the challenging OpenPack dataset shows that it can achieve competitive or even superior performance compared to supervised learning and other SSL methods, while requiring less labeled data. This suggests that MoIL is a promising direction for tackling the challenge of human activity recognition in industrial settings, where labeled data can be scarce and expensive to obtain.
Overall, this work contributes to the growing body of research on self-supervised learning for time series and sensor data analysis, and demonstrates the potential of this approach for real-world applications in the industrial domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Preliminary Investigation of SSL for Complex Work Activity Recognition in Industrial Domain via MoIL
Qingxin Xia, Takuya Maekawa, Jaime Morales, Takahiro Hara, Hirotomo Oshima, Masamitsu Fukuda, Yasuo Namioka
In this study, we investigate a new self-supervised learning (SSL) approach for complex work activity recognition using wearable sensors. Owing to the cost of labeled sensor data collection, SSL methods for human activity recognition (HAR) that effectively use unlabeled data for pretraining have attracted attention. However, applying prior SSL to complex work activities such as packaging works is challenging because the observed data vary considerably depending on situations such as the number of items to pack and the size of the items in the case of packaging works. In this study, we focus on sensor data corresponding to characteristic and necessary actions (sensor data motifs) in a specific activity such as a stretching packing tape action in an assembling a box activity, and textcolor{black}{try} to train a neural network in self-supervised learning so that it identifies occurrences of the characteristic actions, i.e., Motif Identification Learning (MoIL). The feature extractor in the network is used in the downstream task, i.e., work activity recognition, enabling precise activity recognition containing characteristic actions with limited labeled training data. The MoIL approach was evaluated on real-world work activity data and it achieved state-of-the-art performance under limited training labels.
Read more4/23/2024

0
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Asifullah Khan, Anabia Sohail, Mustansar Fiaz, Mehdi Hassan, Tariq Habib Afridi, Sibghat Ullah Marwat, Farzeen Munir, Safdar Ali, Hannan Naseem, Muhammad Zaigham Zaheer, Kamran Ali, Tangina Sultana, Ziaurrehman Tanoli, Naeem Akhter
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to utilize this vast amount of unlabeled data available. Thus it is better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is limited labelled data available. In this survey, we develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Read more9/23/2024

0
Consistency Based Weakly Self-Supervised Learning for Human Activity Recognition with Wearables
Taoran Sheng, Manfred Huber
While the widely available embedded sensors in smartphones and other wearable devices make it easier to obtain data of human activities, recognizing different types of human activities from sensor-based data remains a difficult research topic in ubiquitous computing. One reason for this is that most of the collected data is unlabeled. However, many current human activity recognition (HAR) systems are based on supervised methods, which heavily rely on the labels of the data. We describe a weakly self-supervised approach in this paper that consists of two stages: (1) In stage one, the model learns from the nature of human activities by projecting the data into an embedding space where similar activities are grouped together; (2) In stage two, the model is fine-tuned using similarity information in a few-shot learning fashion using the similarity information of the data. This allows downstream classification or clustering tasks to benefit from the embeddings. Experiments on three benchmark datasets demonstrate the framework's effectiveness and show that our approach can help the clustering algorithm achieve comparable performance in identifying and categorizing the underlying human activities as pure supervised techniques applied directly to a corresponding fully labeled data set.
Read more8/15/2024
🔗
0
Self-supervised Learning for Clustering of Wireless Spectrum Activity
Ljupcho Milosheski, Gregor Cerar, Blav{z} Bertalaniv{c}, Carolina Fortuna, Mihael Mohorv{c}iv{c}
In recent years, much work has been done on processing of wireless spectrum data involving machine learning techniques in domain-related problems for cognitive radio networks, such as anomaly detection, modulation classification, technology classification and device fingerprinting. Most of the solutions are based on labeled data, created in a controlled manner and processed with supervised learning approaches. However, spectrum data measured in real-world environment is highly nondeterministic, making its labeling a laborious and expensive process, requiring domain expertise, thus being one of the main drawbacks of using supervised learning approaches in this domain. In this paper, we investigate the use of self-supervised learning (SSL) for exploring spectrum activities in a real-world unlabeled data. In particular, we compare the performance of two SSL models, one based on a reference DeepCluster architecture and one adapted for spectrum activity identification and clustering, and a baseline model based on K-means clustering algorithm. We show that SSL models achieve superior performance regarding the quality of extracted features and clustering performance. With SSL models we achieve reduction of the feature vectors size by two orders of magnitude, while improving the performance by a factor of 2 to 2.5 across the evaluation metrics, supported by visual assessment. Additionally we show that adaptation of the reference SSL architecture to the domain data provides reduction of model complexity by one order of magnitude, while preserving or even improving the clustering performance.
Read more8/23/2024