OpenVIS: Open-vocabulary Video Instance Segmentation

0
🌿
Sign in to get full access
Overview
- OpenVIS can simultaneously detect, segment, and track arbitrary object categories in a video, without being constrained to categories seen during training.
- The proposed framework, InstFormer, achieves powerful open-vocabulary capabilities through lightweight fine-tuning with limited-category data.
Plain English Explanation
The paper presents InstFormer, a system that can analyze videos and identify, outline, and track any objects in the video, even if those objects were not part of the original training data. This "open-vocabulary" capability is achieved through a careful design that includes:
- An open-world mask proposal network that is encouraged to propose all potential instance class-agnostic masks.
- InstCLIP, which is adapted from the pre-trained CLIP model to efficiently encode open-vocabulary instance tokens. These tokens enable open-vocabulary classification and universal tracking.
- A "universal rollout association" technique that transforms the tracking problem into predicting the next frame's instance tracking token, preventing the tracking module from being constrained by the limited training data.
The result is a system that can outperform state-of-the-art approaches on comprehensive open-vocabulary video instance segmentation benchmarks, while also performing well on fully supervised video instance segmentation tasks.
Technical Explanation
The key technical components of the InstFormer framework include:
-
Open-World Mask Proposal Network: This module is encouraged to propose all potential class-agnostic instance masks using a contrastive instance margin loss, laying the groundwork for open-vocabulary capabilities.
-
InstCLIP: This adapts the pre-trained CLIP model to efficiently encode open-vocabulary instance tokens. These tokens not only enable open-vocabulary classification but also offer strong universal tracking capabilities.
-
Universal Rollout Association: To prevent the tracking module from being constrained by the limited training data, this technique transforms the tracking problem into predicting the next frame's instance tracking token.
The researchers evaluated InstFormer on comprehensive open-vocabulary video instance segmentation benchmarks, where it achieved state-of-the-art performance. It also performed competitively on fully supervised video instance segmentation tasks.
Critical Analysis
The paper presents a well-designed and effective framework for open-vocabulary video instance segmentation. However, the authors acknowledge that the performance is still limited compared to humans, especially for rare or novel object categories. Further research is needed to improve generalization and robustness to such cases.
Additionally, the paper does not address potential biases or ethical considerations that may arise from deploying such a system in real-world applications. Careful consideration of these issues would be important before practical deployment.
Conclusion
The InstFormer framework represents a significant advance in open-vocabulary video instance segmentation, a crucial capability for many real-world applications. By leveraging techniques like the open-world mask proposal network, InstCLIP, and universal rollout association, the system can effectively detect, segment, and track arbitrary object categories, even those not seen during training. This flexibility and generalization could enable a wide range of video understanding applications, from autonomous vehicles to video analytics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
OpenVIS: Open-vocabulary Video Instance Segmentation
Pinxue Guo, Tony Huang, Peiyang He, Xuefeng Liu, Tianjun Xiao, Zhaoyu Chen, Wenqiang Zhang
Open-vocabulary Video Instance Segmentation (OpenVIS) can simultaneously detect, segment, and track arbitrary object categories in a video, without being constrained to categories seen during training. In this work, we propose InstFormer, a carefully designed framework for the OpenVIS task that achieves powerful open-vocabulary capabilities through lightweight fine-tuning with limited-category data. InstFormer begins with the open-world mask proposal network, encouraged to propose all potential instance class-agnostic masks by the contrastive instance margin loss. Next, we introduce InstCLIP, adapted from pre-trained CLIP with Instance Guidance Attention, which encodes open-vocabulary instance tokens efficiently. These instance tokens not only enable open-vocabulary classification but also offer strong universal tracking capabilities. Furthermore, to prevent the tracking module from being constrained by the training data with limited categories, we propose the universal rollout association, which transforms the tracking problem into predicting the next frame's instance tracking token. The experimental results demonstrate the proposed InstFormer achieve state-of-the-art capabilities on a comprehensive OpenVIS evaluation benchmark, while also achieves competitive performance in fully supervised VIS task.
Read more8/20/2024

0
Unified Embedding Alignment for Open-Vocabulary Video Instance Segmentation
Hao Fang, Peng Wu, Yawei Li, Xinxin Zhang, Xiankai Lu
Open-Vocabulary Video Instance Segmentation (VIS) is attracting increasing attention due to its ability to segment and track arbitrary objects. However, the recent Open-Vocabulary VIS attempts obtained unsatisfactory results, especially in terms of generalization ability of novel categories. We discover that the domain gap between the VLM features (e.g., CLIP) and the instance queries and the underutilization of temporal consistency are two central causes. To mitigate these issues, we design and train a novel Open-Vocabulary VIS baseline called OVFormer. OVFormer utilizes a lightweight module for unified embedding alignment between query embeddings and CLIP image embeddings to remedy the domain gap. Unlike previous image-based training methods, we conduct video-based model training and deploy a semi-online inference scheme to fully mine the temporal consistency in the video. Without bells and whistles, OVFormer achieves 21.9 mAP with a ResNet-50 backbone on LV-VIS, exceeding the previous state-of-the-art performance by 7.7. Extensive experiments on some Close-Vocabulary VIS datasets also demonstrate the strong zero-shot generalization ability of OVFormer (+ 7.6 mAP on YouTube-VIS 2019, + 3.9 mAP on OVIS). Code is available at https://github.com/fanghaook/OVFormer.
Read more7/15/2024
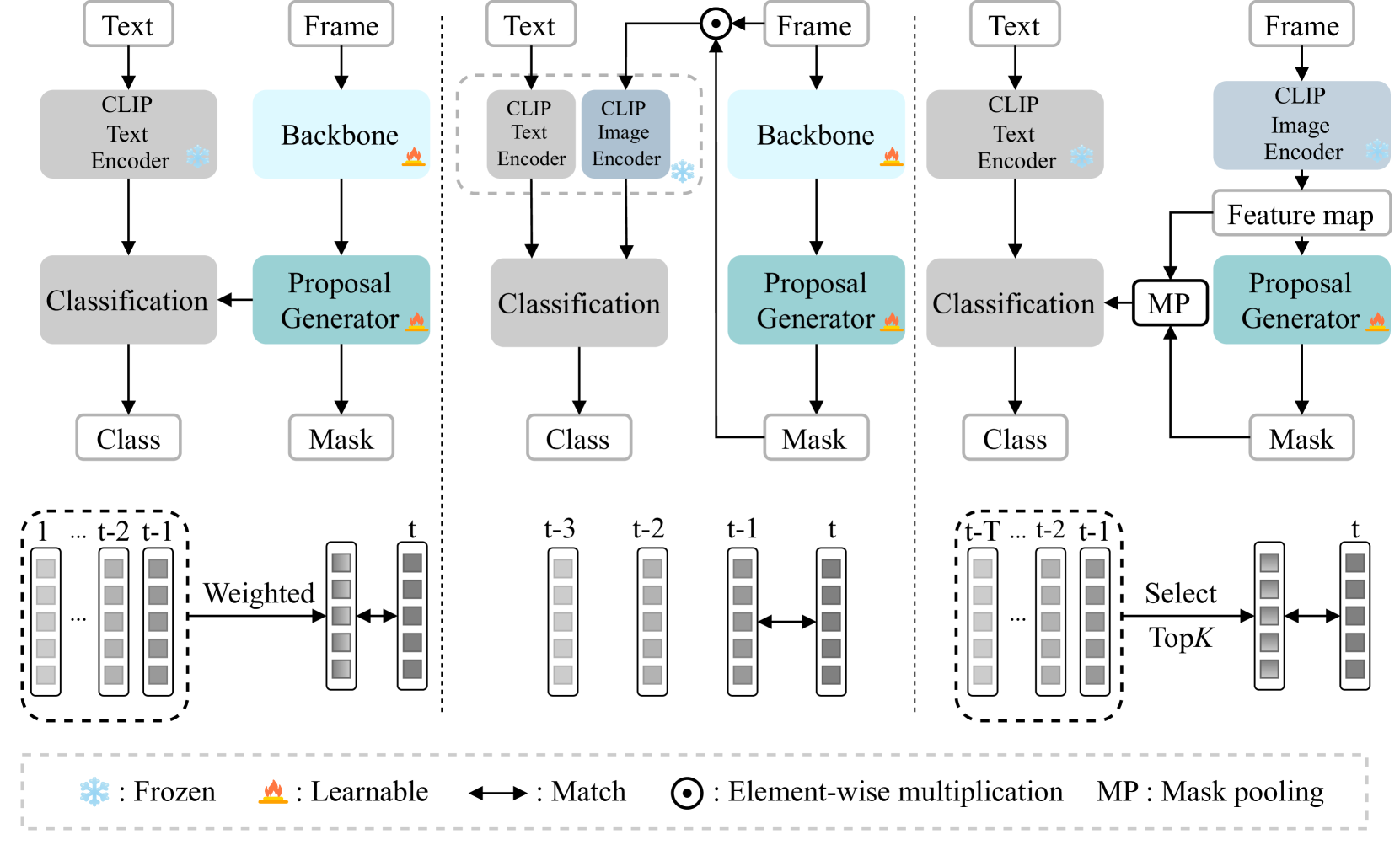
0
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
Read more6/11/2024

0
UVIS: Unsupervised Video Instance Segmentation
Shuaiyi Huang, Saksham Suri, Kamal Gupta, Sai Saketh Rambhatla, Ser-nam Lim, Abhinav Shrivastava
Video instance segmentation requires classifying, segmenting, and tracking every object across video frames. Unlike existing approaches that rely on masks, boxes, or category labels, we propose UVIS, a novel Unsupervised Video Instance Segmentation (UVIS) framework that can perform video instance segmentation without any video annotations or dense label-based pretraining. Our key insight comes from leveraging the dense shape prior from the self-supervised vision foundation model DINO and the openset recognition ability from the image-caption supervised vision-language model CLIP. Our UVIS framework consists of three essential steps: frame-level pseudo-label generation, transformer-based VIS model training, and query-based tracking. To improve the quality of VIS predictions in the unsupervised setup, we introduce a dual-memory design. This design includes a semantic memory bank for generating accurate pseudo-labels and a tracking memory bank for maintaining temporal consistency in object tracks. We evaluate our approach on three standard VIS benchmarks, namely YoutubeVIS-2019, YoutubeVIS-2021, and Occluded VIS. Our UVIS achieves 21.1 AP on YoutubeVIS-2019 without any video annotations or dense pretraining, demonstrating the potential of our unsupervised VIS framework.
Read more6/12/2024