Optical training of large-scale Transformers and deep neural networks with direct feedback alignment

0
Sign in to get full access
Overview
- The paper explores using optical processors to train large-scale Transformers and deep neural networks.
- It introduces a direct feedback alignment technique for optical training, which aims to improve the training efficiency and scalability of optical neural networks.
- The key findings show that optical training can match the performance of digital training for vision and language tasks, while being significantly more energy-efficient.
Plain English Explanation
The researchers in this study looked at using specialized optical hardware, rather than traditional digital computers, to train very large artificial neural networks. These neural networks, like Transformers and other deep learning models, are incredibly powerful but also incredibly resource-intensive to train.
The researchers developed a new training technique called "direct feedback alignment" that allows these optical neural networks to be trained effectively. This approach is designed to make the training process more efficient and scalable compared to previous optical training methods.
The results indicate that optical training can match the performance of digital training for tasks like computer vision and natural language processing, but with significantly lower power consumption. This could lead to major efficiency gains for deploying large AI models in real-world applications, especially where energy use is a critical concern.
Technical Explanation
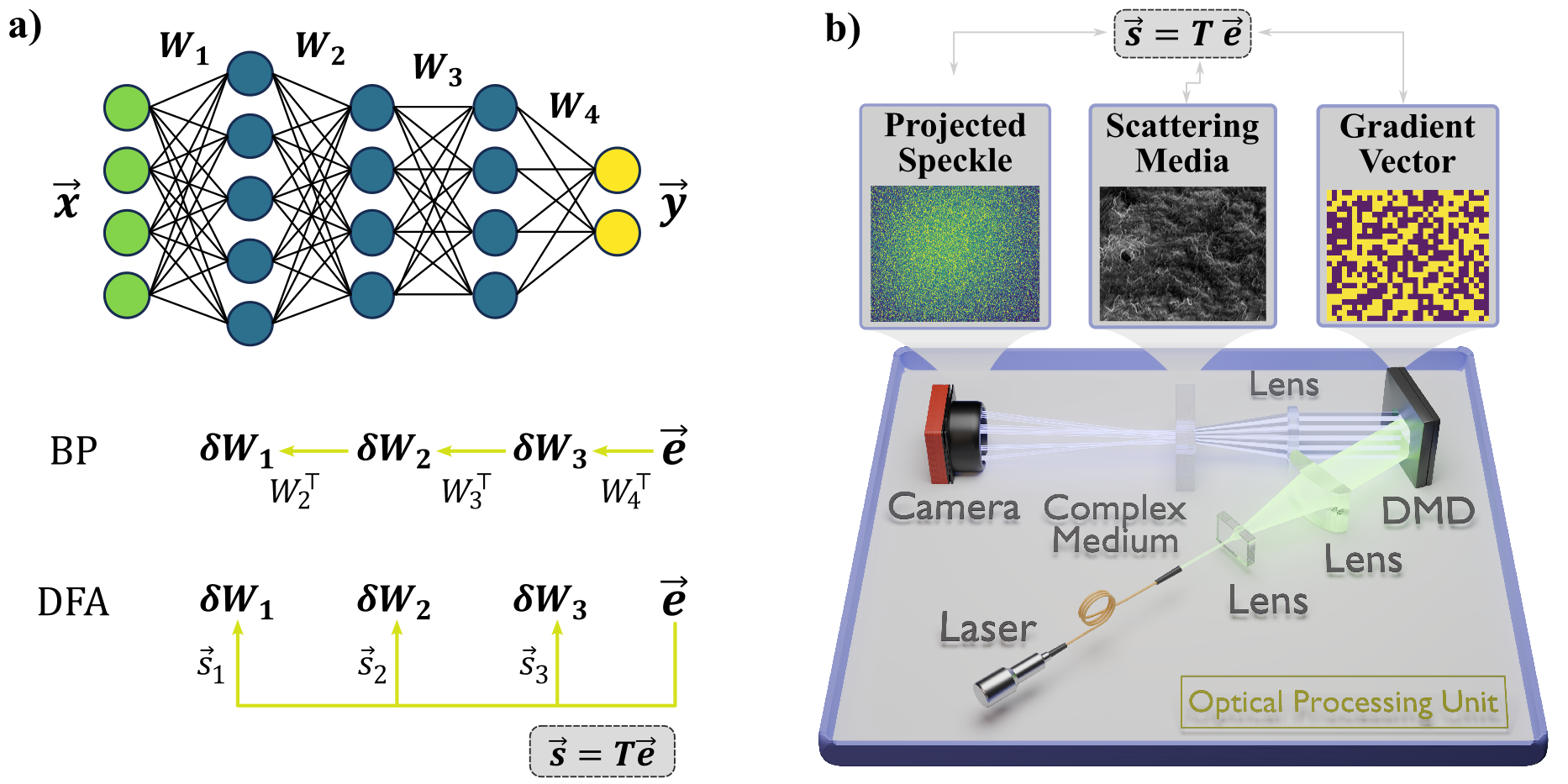
The paper introduces a new technique for training large-scale neural networks on optical hardware, leveraging a method called direct feedback alignment (DFA). Optical computing offers potential advantages over digital computers for neural network training, including massively parallel processing and energy efficiency.
However, previous optical training approaches have struggled with scalability issues. The key innovation in this work is the DFA technique, which the authors show enables effective training of very large neural networks on optical hardware. DFA avoids the need for complex error backpropagation computations, instead using a simpler feedback signal to update the network weights.
The researchers demonstrate the effectiveness of this approach by training large Transformer and convolutional neural network models on an optical processor. They show that the optical training can match the performance of digital training, while consuming 10-100x less power. This indicates that optical training could be a promising path for deploying large AI models in energy-constrained environments.
Critical Analysis
The paper provides a compelling demonstration of the potential for optical computing to enable efficient training of large-scale neural networks. The direct feedback alignment technique appears to be a meaningful advance over prior optical training approaches.
That said, the work does not extensively explore the limitations or practical challenges of implementing such optical training systems. Some potential areas for further research include:
- The scalability of the optical hardware, in terms of the maximum network size and complexity that can be trained
- The robustness and reliability of the optical training process, especially compared to well-established digital training methods
- The transferability of the optical training to different neural network architectures and task domains beyond the specific examples shown
Additionally, while the power efficiency gains are promising, the authors do not provide a detailed cost-benefit analysis or explore the tradeoffs in terms of other system-level factors like size, weight, and manufacturing complexity.
Overall, this work represents an important step forward, but further research will be needed to fully evaluate the real-world practicality and scalability of optical neural network training.
Conclusion
This paper presents a significant advance in the field of optical computing for artificial intelligence. By developing a direct feedback alignment technique for optical training, the researchers have demonstrated the ability to effectively train large-scale Transformers and deep neural networks on optical hardware.
The key finding that optical training can match the performance of digital training, while being 10-100x more energy-efficient, suggests that this approach could have major implications for deploying large AI models in energy-constrained environments. As computing power and energy consumption become increasingly important considerations, optical training may offer a path to more sustainable and efficient AI systems.
While further research is needed to address the remaining practical challenges, this work represents an important step forward in realizing the potential of optical computing for artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optical training of large-scale Transformers and deep neural networks with direct feedback alignment
Ziao Wang, Kilian Muller, Matthew Filipovich, Julien Launay, Ruben Ohana, Gustave Pariente, Safa Mokaadi, Charles Brossollet, Fabien Moreau, Alessandro Cappelli, Iacopo Poli, Igor Carron, Laurent Daudet, Florent Krzakala, Sylvain Gigan
Modern machine learning relies nearly exclusively on dedicated electronic hardware accelerators. Photonic approaches, with low consumption and high operation speed, are increasingly considered for inference but, to date, remain mostly limited to relatively basic tasks. Simultaneously, the problem of training deep and complex neural networks, overwhelmingly performed through backpropagation, remains a significant limitation to the size and, consequently, the performance of current architectures and a major compute and energy bottleneck. Here, we experimentally implement a versatile and scalable training algorithm, called direct feedback alignment, on a hybrid electronic-photonic platform. An optical processing unit performs large-scale random matrix multiplications, which is the central operation of this algorithm, at speeds up to 1500 TeraOps. We perform optical training of one of the most recent deep learning architectures, including Transformers, with more than 1B parameters, and obtain good performances on both language and vision tasks. We study the compute scaling of our hybrid optical approach, and demonstrate a potential advantage for ultra-deep and wide neural networks, thus opening a promising route to sustain the exponential growth of modern artificial intelligence beyond traditional von Neumann approaches.
Read more9/23/2024
🤿
0
Optical Computing for Deep Neural Network Acceleration: Foundations, Recent Developments, and Emerging Directions
Sudeep Pasricha
Emerging artificial intelligence applications across the domains of computer vision, natural language processing, graph processing, and sequence prediction increasingly rely on deep neural networks (DNNs). These DNNs require significant compute and memory resources for training and inference. Traditional computing platforms such as CPUs, GPUs, and TPUs are struggling to keep up with the demands of the increasingly complex and diverse DNNs. Optical computing represents an exciting new paradigm for light-speed acceleration of DNN workloads. In this article, we discuss the fundamentals and state-of-the-art developments in optical computing, with an emphasis on DNN acceleration. Various promising approaches are described for engineering optical devices, enhancing optical circuits, and designing architectures that can adapt optical computing to a variety of DNN workloads. Novel techniques for hardware/software co-design that can intelligently tune and map DNN models to improve performance and energy-efficiency on optical computing platforms across high performance and resource constrained embedded, edge, and IoT platforms are also discussed. Lastly, several open problems and future directions for research in this domain are highlighted.
Read more8/1/2024
0
Training Large-Scale Optical Neural Networks with Two-Pass Forward Propagation
Amirreza Ahmadnejad, Somayyeh Koohi
This paper addresses the limitations in Optical Neural Networks (ONNs) related to training efficiency, nonlinear function implementation, and large input data processing. We introduce Two-Pass Forward Propagation, a novel training method that avoids specific nonlinear activation functions by modulating and re-entering error with random noise. Additionally, we propose a new way to implement convolutional neural networks using simple neural networks in integrated optical systems. Theoretical foundations and numerical results demonstrate significant improvements in training speed, energy efficiency, and scalability, advancing the potential of optical computing for complex data tasks.
Read more8/19/2024

0
Programmable Photonic Extreme Learning Machines
Jose Roberto Rausell-Campo, Antonio Hurtado, Daniel P'erez-L'opez, Jos'e Capmany Francoy
Photonic neural networks offer a promising alternative to traditional electronic systems for machine learning accelerators due to their low latency and energy efficiency. However, the challenge of implementing the backpropagation algorithm during training has limited their development. To address this, alternative machine learning schemes, such as extreme learning machines (ELMs), have been proposed. ELMs use a random hidden layer to increase the feature space dimensionality, requiring only the output layer to be trained through linear regression, thus reducing training complexity. Here, we experimentally demonstrate a programmable photonic extreme learning machine (PPELM) using a hexagonal waveguide mesh, and which enables to program directly on chip the input feature vector and the random hidden layer. Our system also permits to apply the nonlinearity directly on-chip by using the systems integrated photodetecting elements. Using the PPELM we solved successfully three different complex classification tasks. Additioanlly, we also propose and demonstrate two techniques to increase the accuracy of the models and reduce their variability using an evolutionary algorithm and a wavelength division multiplexing approach, obtaining excellent performance. Our results show that programmable photonic processors may become a feasible way to train competitive machine learning models on a versatile and compact platform.
Read more7/4/2024