Training Large-Scale Optical Neural Networks with Two-Pass Forward Propagation

0
Sign in to get full access
Overview
- Researchers propose a two-pass forward propagation training approach for large-scale optical neural networks.
- This method aims to address challenges in training optics-based neural networks at scale.
- The key ideas are to split the forward pass into two stages and use specialized hardware for each stage.
Plain English Explanation
The paper discusses a new way to train large optical neural networks. Optical neural networks use light instead of electricity to process information, which can make them faster and more energy-efficient than traditional electronic neural networks.
The main challenge with training large optical neural networks is that the optical hardware has limitations that make it difficult to do the full neural network forward pass all at once. The researchers propose splitting the forward pass into two stages and using specialized hardware for each stage.
In the first stage, the input data is processed using an optical hardware component. This optical processing is fast but has some limitations. In the second stage, the output from the optical processing is refined using traditional electronic hardware. By dividing the work between optics and electronics, the researchers believe they can train larger and more capable optical neural networks.
Technical Explanation
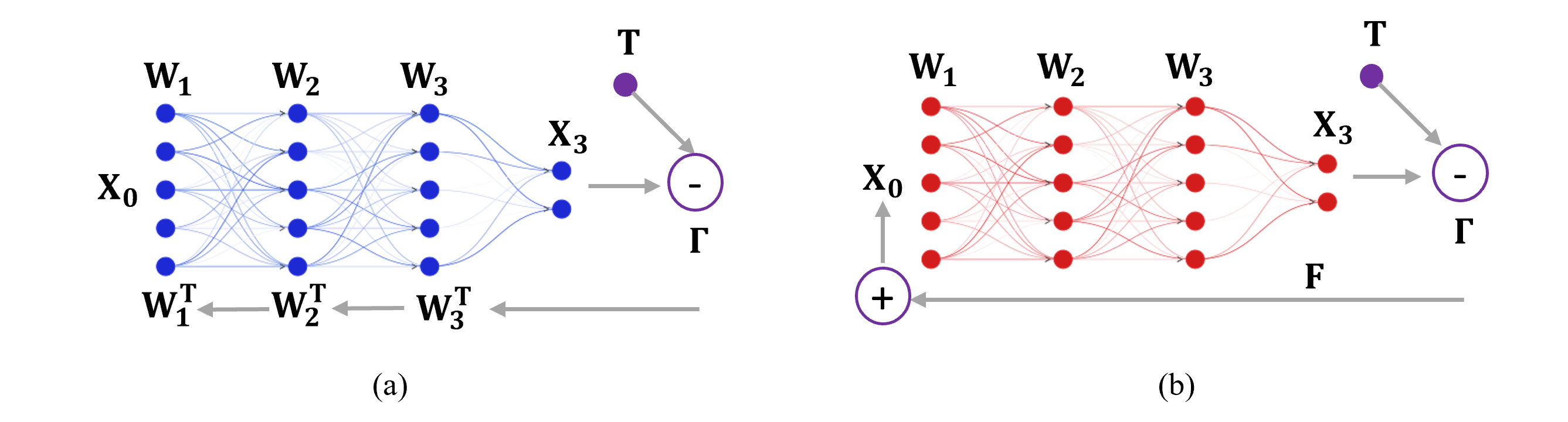
The paper introduces a two-pass forward propagation training approach for optical neural networks. In the first pass, the input data is processed using an all-optical feedforward neural network implementation. This leverages the speed and energy efficiency of optics, but is limited in the complexity of the operations it can perform.
In the second pass, the outputs from the optical processing are refined using a traditional electronic neural network implementation. This electronic network can apply more complex mathematical operations to further transform the data.
By splitting the forward propagation into these two stages, the researchers argue they can train larger and more capable optical neural networks than would be possible using a single all-optical approach. The key innovations are:
- Designing the optical and electronic network architectures to work seamlessly together.
- Developing training algorithms that can effectively optimize the two-stage network as a whole.
- Implementing the system using state-of-the-art optical and electronic hardware components.
The paper presents experimental results demonstrating the effectiveness of this two-pass approach on large-scale image classification tasks. They show it can achieve accuracy on par with all-electronic neural networks while leveraging the speed and efficiency advantages of optics.
Critical Analysis
The researchers acknowledge several limitations and areas for future work:
- The current approach requires both optical and electronic hardware, which adds complexity and cost compared to an all-optical solution.
- The performance gains, while significant, may not be enough to justify the added hardware and system complexity for all applications.
- The training algorithm relies on precise calibration and control of the optical and electronic components, which could be challenging to achieve in practice.
- Scaling the approach to even larger neural network sizes or more complex tasks may require further architectural and algorithmic innovations.
Overall, the two-pass forward propagation approach represents an interesting step forward in the development of large-scale optical neural networks. However, there are still significant engineering and algorithmic challenges to overcome before this technology can be widely deployed.
Conclusion
This paper proposes a novel two-pass forward propagation training approach for large-scale optical neural networks. By splitting the forward pass into an initial optical processing stage and a subsequent electronic refinement stage, the researchers aim to leverage the strengths of both optical and electronic hardware.
The key innovation is the ability to train larger and more capable optical neural networks than would be possible using an all-optical approach alone. While the current implementation has some limitations, this research represents an important step forward in the development of high-performance, energy-efficient optical computing systems for AI and other data-intensive applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training Large-Scale Optical Neural Networks with Two-Pass Forward Propagation
Amirreza Ahmadnejad, Somayyeh Koohi
This paper addresses the limitations in Optical Neural Networks (ONNs) related to training efficiency, nonlinear function implementation, and large input data processing. We introduce Two-Pass Forward Propagation, a novel training method that avoids specific nonlinear activation functions by modulating and re-entering error with random noise. Additionally, we propose a new way to implement convolutional neural networks using simple neural networks in integrated optical systems. Theoretical foundations and numerical results demonstrate significant improvements in training speed, energy efficiency, and scalability, advancing the potential of optical computing for complex data tasks.
Read more8/19/2024
0
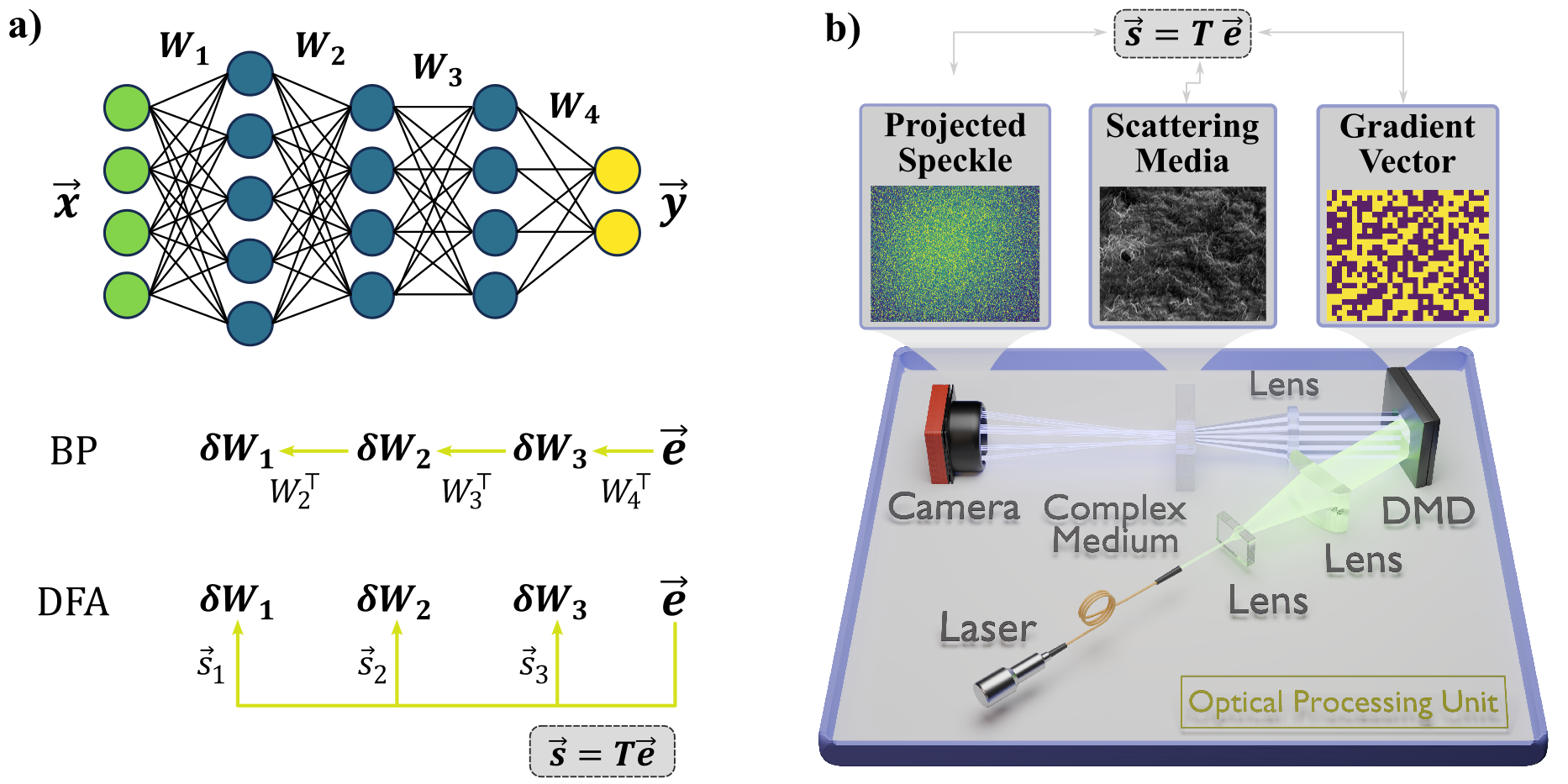
Optical training of large-scale Transformers and deep neural networks with direct feedback alignment
Ziao Wang, Kilian Muller, Matthew Filipovich, Julien Launay, Ruben Ohana, Gustave Pariente, Safa Mokaadi, Charles Brossollet, Fabien Moreau, Alessandro Cappelli, Iacopo Poli, Igor Carron, Laurent Daudet, Florent Krzakala, Sylvain Gigan
Modern machine learning relies nearly exclusively on dedicated electronic hardware accelerators. Photonic approaches, with low consumption and high operation speed, are increasingly considered for inference but, to date, remain mostly limited to relatively basic tasks. Simultaneously, the problem of training deep and complex neural networks, overwhelmingly performed through backpropagation, remains a significant limitation to the size and, consequently, the performance of current architectures and a major compute and energy bottleneck. Here, we experimentally implement a versatile and scalable training algorithm, called direct feedback alignment, on a hybrid electronic-photonic platform. An optical processing unit performs large-scale random matrix multiplications, which is the central operation of this algorithm, at speeds up to 1500 TeraOps. We perform optical training of one of the most recent deep learning architectures, including Transformers, with more than 1B parameters, and obtain good performances on both language and vision tasks. We study the compute scaling of our hybrid optical approach, and demonstrate a potential advantage for ultra-deep and wide neural networks, thus opening a promising route to sustain the exponential growth of modern artificial intelligence beyond traditional von Neumann approaches.
Read more9/23/2024
🧠
0
Photonic Neuromorphic Accelerator for Convolutional Neural Networks based on an Integrated Reconfigurable Mesh
Aris Tsirigotis, Gerge Sarantoglou, Stavros Deligiannidis, Erica Sanchez, Ana Gutierrez, Adonis Bogris, Jose Capmany, Charis Mesaritakis
In this work, we present and experimentally validate a passive photonic-integrated neuromorphic accelerator that uses a hardware-friendly optical spectrum slicing technique through a reconfigurable silicon photonic mesh. The proposed scheme acts as an analogue convolutional engine, enabling information preprocessing in the optical domain, dimensionality reduction and extraction of spatio-temporal features. Numerical results demonstrate that utilizing only 7 passive photonic nodes, critical modules of a digital convolutional neural network can be replaced. As a result, a 98.6% accuracy on the MNIST dataset was achieved, with a power consumption reduction of at least 26% compared to digital CNNs. Experimental results confirm these findings, achieving 97.7% accuracy with only 3 passive nodes.
Read more5/13/2024

0
Annealing-inspired training of an optical neural network with ternary weights
Anas Skalli, Mirko Goldmann, Nasibeh Haghighi, Stephan Reitzenstein, James A. Lott, Daniel Brunner
Artificial neural networks (ANNs) represent a fundamentally connectionnist and distributed approach to computing, and as such they differ from classical computers that utilize the von Neumann architecture. This has revived research interest in new unconventional hardware to enable more efficient implementations of ANNs rather than emulating them on traditional machines. In order to fully leverage the capabilities of this new generation of ANNs, optimization algorithms that take into account hardware limitations and imperfections are necessary. Photonics represents a particularly promising platform, offering scalability, high speed, energy efficiency, and the capability for parallel information processing. Yet, fully fledged implementations of autonomous optical neural networks (ONNs) with in-situ learning remain scarce. In this work, we propose a ternary weight architecture high-dimensional semiconductor laser-based ONN. We introduce a simple method for achieving ternary weights with Boolean hardware, significantly increasing the ONN's information processing capabilities. Furthermore, we design a novel in-situ optimization algorithm that is compatible with, both, Boolean and ternary weights, and provide a detailed hyperparameter study of said algorithm for two different tasks. Our novel algorithm results in benefits, both in terms of convergence speed and performance. Finally, we experimentally characterize the long-term inference stability of our ONN and find that it is extremely stable with a consistency above 99% over a period of more than 10 hours, addressing one of the main concerns in the field. Our work is of particular relevance in the context of in-situ learning under restricted hardware resources, especially since minimizing the power consumption of auxiliary hardware is crucial to preserving efficiency gains achieved by non-von Neumann ANN implementations.
Read more9/4/2024