Optimal Classification-based Anomaly Detection with Neural Networks: Theory and Practice

0

Sign in to get full access
Overview
- The paper proposes an optimal classification-based anomaly detection method using neural networks.
- It presents a theoretical framework for analyzing the performance of this approach and provides practical guidelines for its implementation.
- The method aims to overcome the limitations of existing unsupervised and semi-supervised anomaly detection techniques.
Plain English Explanation
The paper introduces a new approach for detecting anomalies, or unusual data points, using machine learning techniques. The core idea is to train a neural network [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/towards-unified-framework-clustering-based-anomaly-detection">neural network</a>] to classify data as either "normal" or "anomalous."
This is different from traditional unsupervised anomaly detection methods, which try to identify outliers without any labeled examples. Instead, the authors propose a "classification-based" approach where the neural network learns to distinguish normal data from anomalies.
The key advantage of this method is that it can better capture the complex patterns in the data, leading to more accurate anomaly detection. The paper also provides a theoretical framework to analyze the performance of this approach and practical guidelines for implementing it effectively.
Technical Explanation
The paper formulates the anomaly detection problem as a binary classification task, where the neural network [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/deep-positive-unlabeled-anomaly-detection-contaminated-unlabeled">neural network</a>] is trained to predict whether a given data point is "normal" or "anomalous."
The authors derive an optimal classification rule that minimizes the probability of misclassifying normal data as anomalies and vice versa. They show that this optimal rule can be implemented using a neural network with a specific architecture and loss function.
The paper also provides practical guidelines for training the neural network, including techniques for handling imbalanced datasets and dealing with the inherent uncertainty in defining anomalies. The authors demonstrate the effectiveness of their approach through experiments on real-world datasets, showing that it outperforms existing unsupervised and semi-supervised anomaly detection methods.
Critical Analysis
The paper presents a rigorous theoretical framework for understanding the performance of classification-based anomaly detection using neural networks. However, the authors acknowledge that their approach relies on the assumption that the underlying data distribution is known or can be accurately estimated from the available data.
In practice, this may be a strong assumption, as the true data distribution is often unknown or difficult to model, especially in complex, high-dimensional datasets. The paper also does not address the challenge of obtaining representative "normal" data for training the neural network, which can be a significant practical hurdle in many real-world applications.
Furthermore, the paper focuses solely on binary classification, where data points are categorized as either "normal" or "anomalous." In some scenarios, it may be more useful to have a more nuanced understanding of the degree of anomaly, which the proposed method does not provide.
Conclusion
The paper presents a novel and theoretically grounded approach for anomaly detection using neural networks. By framing the problem as a classification task, the method aims to leverage the powerful pattern recognition capabilities of neural networks to accurately identify anomalies in complex data.
The theoretical analysis and practical guidelines provided in the paper offer valuable insights for researchers and practitioners working on anomaly detection problems. However, the approach's reliance on known data distributions and the binary nature of the classification task suggest that further research may be needed to address the practical challenges of real-world anomaly detection scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Optimal Classification-based Anomaly Detection with Neural Networks: Theory and Practice
Tian-Yi Zhou, Matthew Lau, Jizhou Chen, Wenke Lee, Xiaoming Huo
Anomaly detection is an important problem in many application areas, such as network security. Many deep learning methods for unsupervised anomaly detection produce good empirical performance but lack theoretical guarantees. By casting anomaly detection into a binary classification problem, we establish non-asymptotic upper bounds and a convergence rate on the excess risk on rectified linear unit (ReLU) neural networks trained on synthetic anomalies. Our convergence rate on the excess risk matches the minimax optimal rate in the literature. Furthermore, we provide lower and upper bounds on the number of synthetic anomalies that can attain this optimality. For practical implementation, we relax some conditions to improve the search for the empirical risk minimizer, which leads to competitive performance to other classification-based methods for anomaly detection. Overall, our work provides the first theoretical guarantees of unsupervised neural network-based anomaly detectors and empirical insights on how to design them well.
Read more9/16/2024
🤿
0
Deep Learning for Time Series Anomaly Detection: A Survey
Zahra Zamanzadeh Darban, Geoffrey I. Webb, Shirui Pan, Charu C. Aggarwal, Mahsa Salehi
Time series anomaly detection has applications in a wide range of research fields and applications, including manufacturing and healthcare. The presence of anomalies can indicate novel or unexpected events, such as production faults, system defects, or heart fluttering, and is therefore of particular interest. The large size and complex patterns of time series have led researchers to develop specialised deep learning models for detecting anomalous patterns. This survey focuses on providing structured and comprehensive state-of-the-art time series anomaly detection models through the use of deep learning. It providing a taxonomy based on the factors that divide anomaly detection models into different categories. Aside from describing the basic anomaly detection technique for each category, the advantages and limitations are also discussed. Furthermore, this study includes examples of deep anomaly detection in time series across various application domains in recent years. It finally summarises open issues in research and challenges faced while adopting deep anomaly detection models.
Read more5/29/2024
0
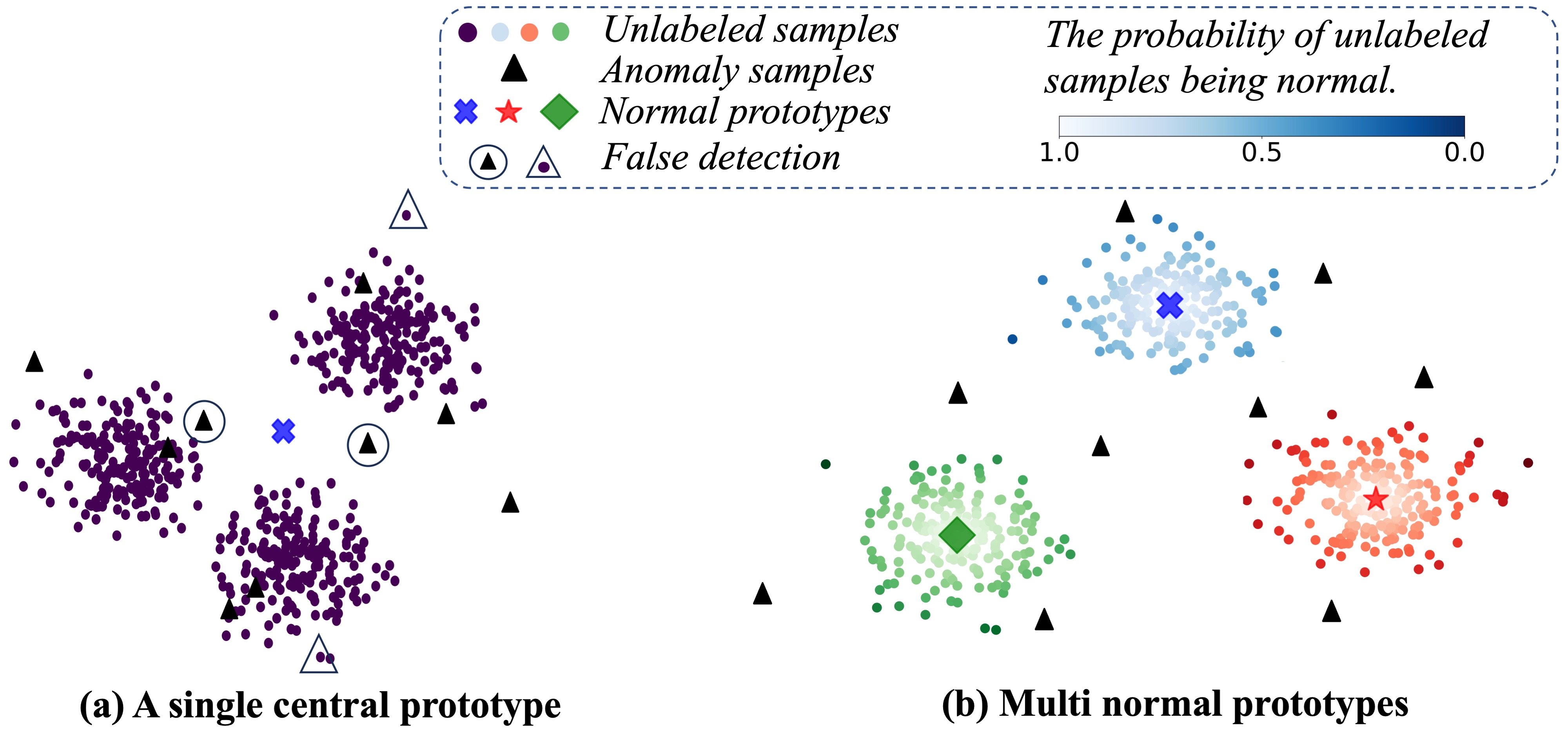
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Zhijin Dong, Hongzhi Liu, Boyuan Ren, Weimin Xiong, Zhonghai Wu
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
Read more8/28/2024
0
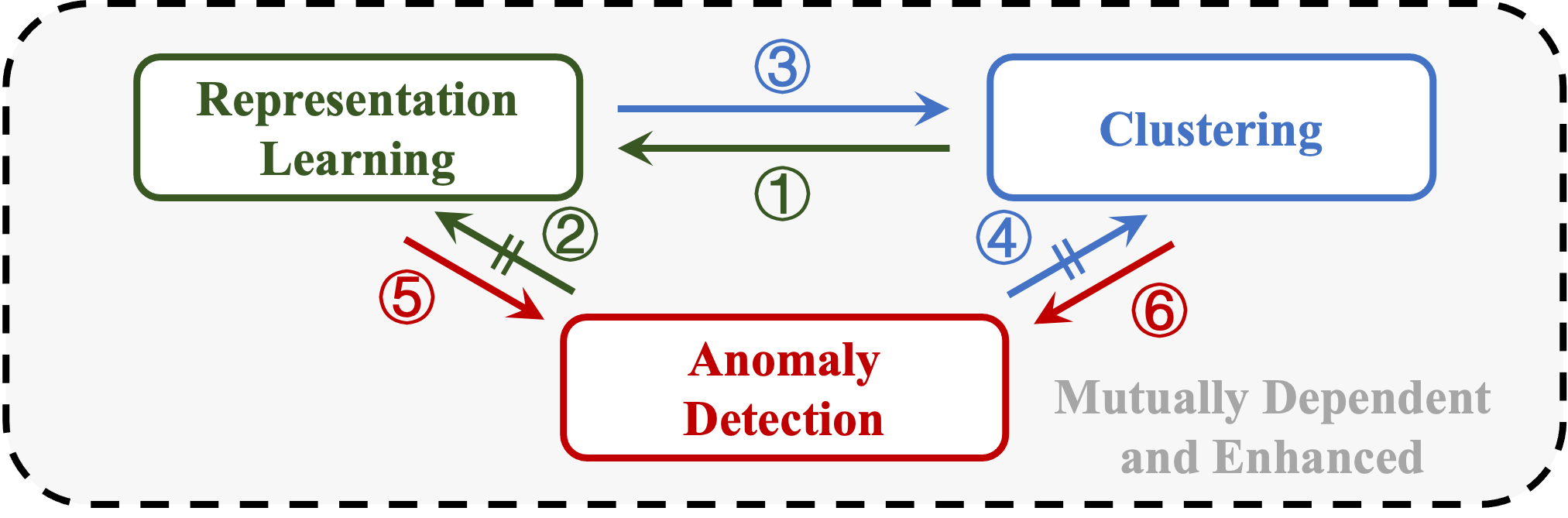
Towards a Unified Framework of Clustering-based Anomaly Detection
Zeyu Fang, Ming Gu, Sheng Zhou, Jiawei Chen, Qiaoyu Tan, Haishuai Wang, Jiajun Bu
Unsupervised Anomaly Detection (UAD) plays a crucial role in identifying abnormal patterns within data without labeled examples, holding significant practical implications across various domains. Although the individual contributions of representation learning and clustering to anomaly detection are well-established, their interdependencies remain under-explored due to the absence of a unified theoretical framework. Consequently, their collective potential to enhance anomaly detection performance remains largely untapped. To bridge this gap, in this paper, we propose a novel probabilistic mixture model for anomaly detection to establish a theoretical connection among representation learning, clustering, and anomaly detection. By maximizing a novel anomaly-aware data likelihood, representation learning and clustering can effectively reduce the adverse impact of anomalous data and collaboratively benefit anomaly detection. Meanwhile, a theoretically substantiated anomaly score is naturally derived from this framework. Lastly, drawing inspiration from gravitational analysis in physics, we have devised an improved anomaly score that more effectively harnesses the combined power of representation learning and clustering. Extensive experiments, involving 17 baseline methods across 30 diverse datasets, validate the effectiveness and generalization capability of the proposed method, surpassing state-of-the-art methods.
Read more6/4/2024