Optimal Hessian/Jacobian-Free Nonconvex-PL Bilevel Optimization

0
Sign in to get full access
Overview
- Bilevel optimization is a powerful technique for solving complex problems
- This paper presents an efficient algorithm for solving nonconvex-PL bilevel optimization problems without requiring Hessian or Jacobian calculations
- The algorithm achieves optimal gradient complexity while maintaining strong convergence guarantees
Plain English Explanation
Bilevel optimization is a technique used to solve complex problems where there are two interconnected optimization problems - an "upper-level" problem and a "lower-level" problem. The upper-level problem tries to find the best solution, while the lower-level problem determines how the solution affects certain constraints or objectives.
This paper focuses on a specific type of bilevel optimization problem called "nonconvex-PL" problems. These problems have a nonlinear, non-convex upper-level objective, but a lower-level objective that satisfies a property called "Polyak-Łojasiewicz (PL) condition". This means the lower-level problem is not as complex as a general nonconvex problem.
The key contribution of this paper is an efficient algorithm for solving these nonconvex-PL bilevel optimization problems. Importantly, the algorithm does not require explicitly calculating the Hessian or Jacobian matrices, which can be computationally expensive. Instead, it uses a technique called "Hessian/Jacobian-free optimization" to avoid these calculations.
The paper shows that this algorithm achieves the optimal gradient complexity for solving nonconvex-PL bilevel problems, while still maintaining strong convergence guarantees. This means the algorithm is able to find a good solution using the fewest possible gradient computations, making it a highly efficient approach.
Technical Explanation
The paper presents an algorithm called "Optimal Hessian/Jacobian-Free Nonconvex-PL Bilevel Optimization" for solving bilevel optimization problems where the upper-level objective is nonconvex but the lower-level objective satisfies the Polyak-Łojasiewicz (PL) condition.
The key features of the algorithm are:
-
Hessian/Jacobian-free: The algorithm avoids explicitly computing the Hessian or Jacobian matrices, which can be computationally expensive. Instead, it uses a Hessian/Jacobian-free optimization technique.
-
Optimal gradient complexity: The paper shows that the algorithm achieves the optimal gradient complexity for solving nonconvex-PL bilevel problems. This means it finds a good solution using the fewest possible gradient computations.
-
Strong convergence guarantees: Despite the nonconvex upper-level objective, the algorithm is able to provably converge to a stationary point of the bilevel problem under mild assumptions.
The algorithm works by alternating between updating the upper-level and lower-level variables. For the upper-level update, it uses a stochastic gradient descent method. For the lower-level update, it leverages the PL condition to efficiently solve the lower-level problem using a different optimization technique.
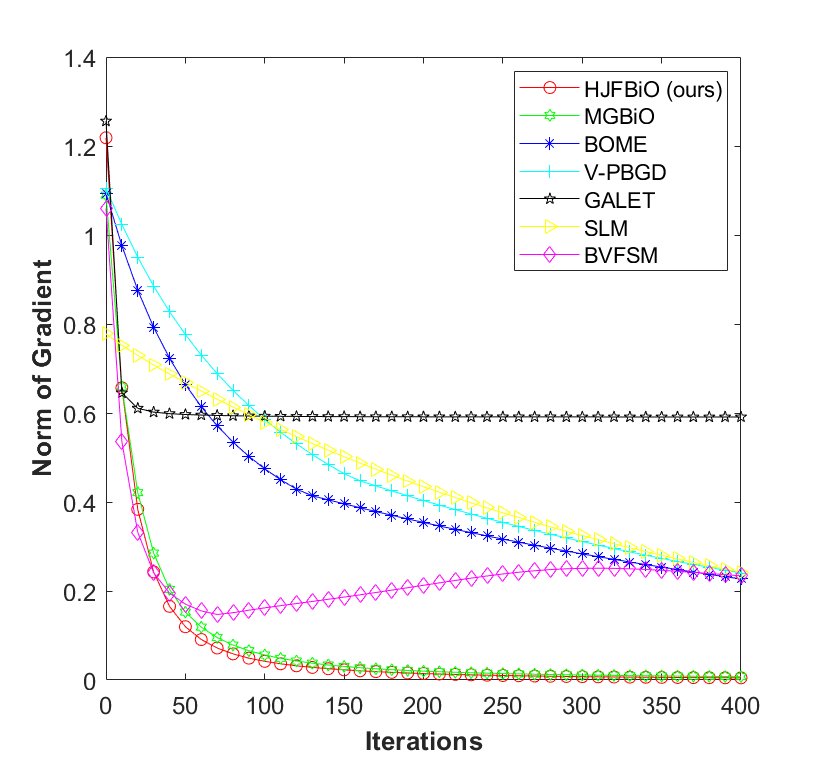
The paper provides a detailed theoretical analysis, showing that the algorithm achieves the optimal gradient complexity for nonconvex-PL bilevel optimization problems. It also includes experimental results demonstrating the practical performance of the algorithm on various benchmark problems.
Critical Analysis
The paper makes a strong contribution by presenting an efficient algorithm for solving a class of challenging bilevel optimization problems. The key strengths of the work are:
-
Hessian/Jacobian-free approach: Avoiding expensive Hessian and Jacobian computations is a significant practical advantage, as it makes the algorithm more scalable and applicable to real-world problems.
-
Optimal gradient complexity: Achieving the optimal gradient complexity is an important theoretical result, as it means the algorithm is able to find good solutions using the fewest possible gradient computations.
-
Convergence guarantees: The ability to provably converge to a stationary point, even with a nonconvex upper-level objective, is a notable strength of the algorithm.
However, the paper also has a few limitations:
-
Restricted problem class: The algorithm is designed for the specific class of nonconvex-PL bilevel problems. While this is an important and relevant problem setting, there are many other bilevel optimization problems that are not covered by this work.
-
Assumption on lower-level: The requirement that the lower-level objective satisfies the PL condition may be restrictive in some applications, as this condition may not always hold.
-
Practical performance: While the theoretical results are strong, the paper only includes a limited set of experimental results. More extensive testing on larger-scale, real-world problems would help demonstrate the practical impact of the algorithm.
Overall, this paper presents a significant advance in bilevel optimization and offers a promising approach for solving a class of challenging problems. Future research could explore extending the algorithm to handle a broader range of bilevel optimization problems or address some of the limitations mentioned above.
Conclusion
This paper introduces an efficient algorithm for solving nonconvex-PL bilevel optimization problems without requiring explicit Hessian or Jacobian calculations. The key contributions are:
- Hessian/Jacobian-free optimization: The algorithm avoids the computational expense of computing Hessian and Jacobian matrices, making it more scalable and practical.
- Optimal gradient complexity: The algorithm achieves the optimal gradient complexity for solving this class of bilevel problems, meaning it finds good solutions using the fewest possible gradient computations.
- Strong convergence guarantees: Despite the nonconvex upper-level objective, the algorithm is able to provably converge to a stationary point of the bilevel problem under mild assumptions.
The paper makes a significant advancement in bilevel optimization and presents a powerful tool for solving complex, real-world problems that can be formulated in this framework. While the algorithm is limited to the specific class of nonconvex-PL bilevel problems, the insights and techniques developed in this work could inspire future research to tackle a broader range of bilevel optimization challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimal Hessian/Jacobian-Free Nonconvex-PL Bilevel Optimization
Feihu Huang
Bilevel optimization is widely applied in many machine learning tasks such as hyper-parameter learning, meta learning and reinforcement learning. Although many algorithms recently have been developed to solve the bilevel optimization problems, they generally rely on the (strongly) convex lower-level problems. More recently, some methods have been proposed to solve the nonconvex-PL bilevel optimization problems, where their upper-level problems are possibly nonconvex, and their lower-level problems are also possibly nonconvex while satisfying Polyak-{L}ojasiewicz (PL) condition. However, these methods still have a high convergence complexity or a high computation complexity such as requiring compute expensive Hessian/Jacobian matrices and its inverses. In the paper, thus, we propose an efficient Hessian/Jacobian-free method (i.e., HJFBiO) with the optimal convergence complexity to solve the nonconvex-PL bilevel problems. Theoretically, under some mild conditions, we prove that our HJFBiO method obtains an optimal convergence rate of $O(frac{1}{T})$, where $T$ denotes the number of iterations, and has an optimal gradient complexity of $O(epsilon^{-1})$ in finding an $epsilon$-stationary solution. We conduct some numerical experiments on the bilevel PL game and hyper-representation learning task to demonstrate efficiency of our proposed method.
Read more7/26/2024
🤯
0
On Finding Small Hyper-Gradients in Bilevel Optimization: Hardness Results and Improved Analysis
Lesi Chen, Jing Xu, Jingzhao Zhang
Bilevel optimization reveals the inner structure of otherwise oblique optimization problems, such as hyperparameter tuning, neural architecture search, and meta-learning. A common goal in bilevel optimization is to minimize a hyper-objective that implicitly depends on the solution set of the lower-level function. Although this hyper-objective approach is widely used, its theoretical properties have not been thoroughly investigated in cases where the lower-level functions lack strong convexity. In this work, we first provide hardness results to show that the goal of finding stationary points of the hyper-objective for nonconvex-convex bilevel optimization can be intractable for zero-respecting algorithms. Then we study a class of tractable nonconvex-nonconvex bilevel problems when the lower-level function satisfies the Polyak-{L}ojasiewicz (PL) condition. We show a simple first-order algorithm can achieve better complexity bounds of $tilde{mathcal{O}}(epsilon^{-2})$, $tilde{mathcal{O}}(epsilon^{-4})$ and $tilde{mathcal{O}}(epsilon^{-6})$ in the deterministic, partially stochastic, and fully stochastic setting respectively.
Read more5/15/2024

0
Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity
Yan Yang, Bin Gao, Ya-xiang Yuan
Bilevel reinforcement learning (RL), which features intertwined two-level problems, has attracted growing interest recently. The inherent non-convexity of the lower-level RL problem is, however, to be an impediment to developing bilevel optimization methods. By employing the fixed point equation associated with the regularized RL, we characterize the hyper-gradient via fully first-order information, thus circumventing the assumption of lower-level convexity. This, remarkably, distinguishes our development of hyper-gradient from the general AID-based bilevel frameworks since we take advantage of the specific structure of RL problems. Moreover, we propose both model-based and model-free bilevel reinforcement learning algorithms, facilitated by access to the fully first-order hyper-gradient. Both algorithms are provable to enjoy the convergence rate $mathcal{O}(epsilon^{-1})$. To the best of our knowledge, this is the first time that AID-based bilevel RL gets rid of additional assumptions on the lower-level problem. In addition, numerical experiments demonstrate that the hyper-gradient indeed serves as an integration of exploitation and exploration.
Read more5/31/2024

0
An Accelerated Gradient Method for Convex Smooth Simple Bilevel Optimization
Jincheng Cao, Ruichen Jiang, Erfan Yazdandoost Hamedani, Aryan Mokhtari
In this paper, we focus on simple bilevel optimization problems, where we minimize a convex smooth objective function over the optimal solution set of another convex smooth constrained optimization problem. We present a novel bilevel optimization method that locally approximates the solution set of the lower-level problem using a cutting plane approach and employs an accelerated gradient-based update to reduce the upper-level objective function over the approximated solution set. We measure the performance of our method in terms of suboptimality and infeasibility errors and provide non-asymptotic convergence guarantees for both error criteria. Specifically, when the feasible set is compact, we show that our method requires at most $mathcal{O}(max{1/sqrt{epsilon_{f}}, 1/epsilon_g})$ iterations to find a solution that is $epsilon_f$-suboptimal and $epsilon_g$-infeasible. Moreover, under the additional assumption that the lower-level objective satisfies the $r$-th Holderian error bound, we show that our method achieves an iteration complexity of $mathcal{O}(max{epsilon_{f}^{-frac{2r-1}{2r}},epsilon_{g}^{-frac{2r-1}{2r}}})$, which matches the optimal complexity of single-level convex constrained optimization when $r=1$.
Read more6/3/2024