Optimal Transport Aggregation for Visual Place Recognition

0

Sign in to get full access
Overview
- This paper proposes a method for visual place recognition (VPR) called "Optimal Transport Aggregation" that uses optimal transport theory to combine local features from images.
- The method aims to improve the accuracy and robustness of VPR, which is the task of determining the location of a camera based on the visual information it captures.
- The authors evaluate their approach on several standard VPR benchmarks and show that it outperforms existing state-of-the-art methods.
Plain English Explanation
Visual place recognition (VPR) is the task of determining the location of a camera based on the images it captures. This is an important capability for applications like autonomous navigation, augmented reality, and image retrieval.
The key idea behind the "Optimal Transport Aggregation" method proposed in this paper is to use optimal transport theory to combine the local visual features extracted from an image. Optimal transport is a mathematical framework that can efficiently compare and combine different distributions of data, such as the visual features in an image.
By using optimal transport to aggregate the local features, the method is able to capture the overall structure and spatial relationships of the visual information in a more robust way. This allows the VPR system to better match the current image to previously stored reference images, even in the presence of changes in viewpoint, illumination, or other challenging conditions.
The authors evaluate their approach on several standard VPR benchmarks and show that it outperforms existing state-of-the-art methods. This suggests that the use of optimal transport for feature aggregation is a promising direction for improving the performance and robustness of visual place recognition systems.
Technical Explanation
The paper presents a method for visual place recognition (VPR) called "Optimal Transport Aggregation" that uses optimal transport theory to combine local features extracted from images.
Local Feature Extraction
The first step is to extract local visual features from the input image. The authors use a pre-trained convolutional neural network (CNN) to extract local descriptors at various scales and locations in the image. This provides a set of local features that capture the detailed visual information in the scene.
Optimal Transport Aggregation
To combine these local features into a global image representation, the authors apply optimal transport theory. Optimal transport is a mathematical framework for comparing and aligning different distributions of data. In this case, the local feature descriptors are treated as probability distributions, and optimal transport is used to find the most efficient way to "transport" the features from one image to match those of another.
By using optimal transport, the method is able to capture the overall structure and spatial relationships of the visual information in a more robust way compared to simpler feature aggregation techniques like average pooling. This allows the VPR system to better match the current image to previously stored reference images, even in the presence of changes in viewpoint, illumination, or other challenging conditions.
Evaluation
The authors evaluate their Optimal Transport Aggregation method on several standard VPR benchmarks, including the Pittsburgh Outdoor Vision Benchmark and the Nordland dataset. They compare their approach to existing state-of-the-art VPR methods and demonstrate that it achieves superior performance in terms of accuracy and robustness.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Optimal Transport Aggregation method for visual place recognition. The use of optimal transport theory for feature aggregation is a novel and promising approach that addresses some of the key challenges in VPR, such as handling variations in viewpoint and environmental conditions.
One potential limitation of the method is its computational complexity, as optimal transport calculations can be resource-intensive. The authors mention that they use a approximation technique to make the computations more efficient, but it would be useful to have a more detailed analysis of the trade-offs between accuracy and efficiency.
Additionally, while the method demonstrates strong performance on the evaluated benchmarks, it would be valuable to see how it generalizes to a wider range of scenarios, such as indoor environments or more diverse urban settings. Exploring the adaptability of the approach to different types of VPR tasks and datasets could further strengthen the claims about its effectiveness and robustness.
Overall, the Optimal Transport Aggregation method presented in this paper represents a significant contribution to the field of visual place recognition, and the authors' thorough evaluation and thoughtful discussion of the approach make it a valuable resource for researchers and practitioners in this area.
Conclusion
This paper introduces a novel method for visual place recognition called "Optimal Transport Aggregation" that uses optimal transport theory to combine local visual features in a robust and effective way. The authors demonstrate that their approach outperforms existing state-of-the-art VPR methods on several standard benchmarks, suggesting that the use of optimal transport is a promising direction for improving the accuracy and robustness of place recognition systems.
The core ideas behind the Optimal Transport Aggregation method, such as the use of optimal transport for feature aggregation and the focus on capturing the spatial relationships of visual information, could have broader implications for other computer vision tasks that rely on robust image representations. As such, this work represents an important advancement in the field of visual place recognition and may inspire further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimal Transport Aggregation for Visual Place Recognition
Sergio Izquierdo, Javier Civera
The task of Visual Place Recognition (VPR) aims to match a query image against references from an extensive database of images from different places, relying solely on visual cues. State-of-the-art pipelines focus on the aggregation of features extracted from a deep backbone, in order to form a global descriptor for each image. In this context, we introduce SALAD (Sinkhorn Algorithm for Locally Aggregated Descriptors), which reformulates NetVLAD's soft-assignment of local features to clusters as an optimal transport problem. In SALAD, we consider both feature-to-cluster and cluster-to-feature relations and we also introduce a 'dustbin' cluster, designed to selectively discard features deemed non-informative, enhancing the overall descriptor quality. Additionally, we leverage and fine-tune DINOv2 as a backbone, which provides enhanced description power for the local features, and dramatically reduces the required training time. As a result, our single-stage method not only surpasses single-stage baselines in public VPR datasets, but also surpasses two-stage methods that add a re-ranking with significantly higher cost. Code and models are available at https://github.com/serizba/salad.
Read more6/28/2024

0
Register assisted aggregation for Visual Place Recognition
Xuan Yu, Zhenyong Fu
Visual Place Recognition (VPR) refers to the process of using computer vision to recognize the position of the current query image. Due to the significant changes in appearance caused by season, lighting, and time spans between query images and database images for retrieval, these differences increase the difficulty of place recognition. Previous methods often discarded useless features (such as sky, road, vehicles) while uncontrolled discarding features that help improve recognition accuracy (such as buildings, trees). To preserve these useful features, we propose a new feature aggregation method to address this issue. Specifically, in order to obtain global and local features that contain discriminative place information, we added some registers on top of the original image tokens to assist in model training. After reallocating attention weights, these registers were discarded. The experimental results show that these registers surprisingly separate unstable features from the original image representation and outperform state-of-the-art methods.
Read more5/21/2024
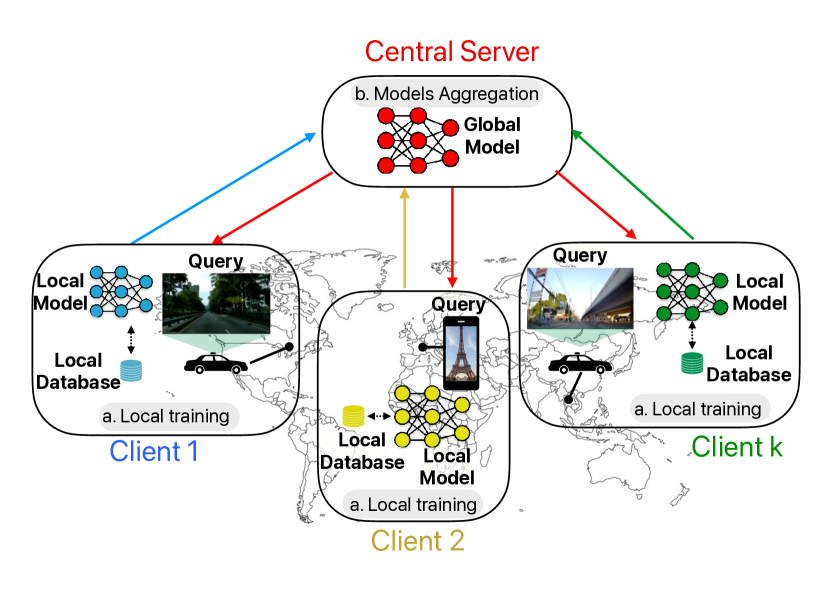
0
Collaborative Visual Place Recognition through Federated Learning
Mattia Dutto, Gabriele Berton, Debora Caldarola, Eros Fan`i, Gabriele Trivigno, Carlo Masone
Visual Place Recognition (VPR) aims to estimate the location of an image by treating it as a retrieval problem. VPR uses a database of geo-tagged images and leverages deep neural networks to extract a global representation, called descriptor, from each image. While the training data for VPR models often originates from diverse, geographically scattered sources (geo-tagged images), the training process itself is typically assumed to be centralized. This research revisits the task of VPR through the lens of Federated Learning (FL), addressing several key challenges associated with this adaptation. VPR data inherently lacks well-defined classes, and models are typically trained using contrastive learning, which necessitates a data mining step on a centralized database. Additionally, client devices in federated systems can be highly heterogeneous in terms of their processing capabilities. The proposed FedVPR framework not only presents a novel approach for VPR but also introduces a new, challenging, and realistic task for FL research, paving the way to other image retrieval tasks in FL.
Read more4/23/2024

0
Towards Seamless Adaptation of Pre-trained Models for Visual Place Recognition
Feng Lu, Lijun Zhang, Xiangyuan Lan, Shuting Dong, Yaowei Wang, Chun Yuan
Recent studies show that vision models pre-trained in generic visual learning tasks with large-scale data can provide useful feature representations for a wide range of visual perception problems. However, few attempts have been made to exploit pre-trained foundation models in visual place recognition (VPR). Due to the inherent difference in training objectives and data between the tasks of model pre-training and VPR, how to bridge the gap and fully unleash the capability of pre-trained models for VPR is still a key issue to address. To this end, we propose a novel method to realize seamless adaptation of pre-trained models for VPR. Specifically, to obtain both global and local features that focus on salient landmarks for discriminating places, we design a hybrid adaptation method to achieve both global and local adaptation efficiently, in which only lightweight adapters are tuned without adjusting the pre-trained model. Besides, to guide effective adaptation, we propose a mutual nearest neighbor local feature loss, which ensures proper dense local features are produced for local matching and avoids time-consuming spatial verification in re-ranking. Experimental results show that our method outperforms the state-of-the-art methods with less training data and training time, and uses about only 3% retrieval runtime of the two-stage VPR methods with RANSAC-based spatial verification. It ranks 1st on the MSLS challenge leaderboard (at the time of submission). The code is released at https://github.com/Lu-Feng/SelaVPR.
Read more4/4/2024