Collaborative Visual Place Recognition through Federated Learning

0
Sign in to get full access
Overview
- This paper proposes a collaborative visual place recognition (VPR) system using federated learning, which allows multiple devices to learn a shared VPR model without exchanging raw data.
- The system leverages the complementary visual information from different devices to improve the overall VPR performance, while preserving the privacy of the user data.
- Experiments show that the federated learning-based VPR outperforms centralized training and achieves comparable performance to a model trained on pooled data.
Plain English Explanation
The paper describes a new way to train a visual place recognition (VPR) model, which is a technology that allows devices like smartphones or robots to recognize places they have been to before. Typically, this would require sharing all the visual data from many devices with a central server to train the model. However, this can raise privacy concerns, as the raw data may contain sensitive information about the users.
The researchers have developed a federated learning approach, where the devices collaborate to train the VPR model without sharing the raw data. Instead, the devices exchange only the updates to the model, allowing them to learn from each other's experiences while keeping the actual data private.
This approach leverages the complementary visual information from different devices to improve the overall VPR performance. For example, if one device encounters a place that another device has not seen before, the model can learn from this new information without needing to access the raw data from the first device.
The experiments show that this federated learning-based VPR system outperforms a centralized model trained on pooled data from all devices, and achieves comparable performance to a model trained on the pooled data directly. This demonstrates the potential of this approach to improve VPR while preserving user privacy.
Technical Explanation
The paper proposes a collaborative visual place recognition (VPR) system using federated learning, which allows multiple devices to learn a shared VPR model without exchanging raw data.
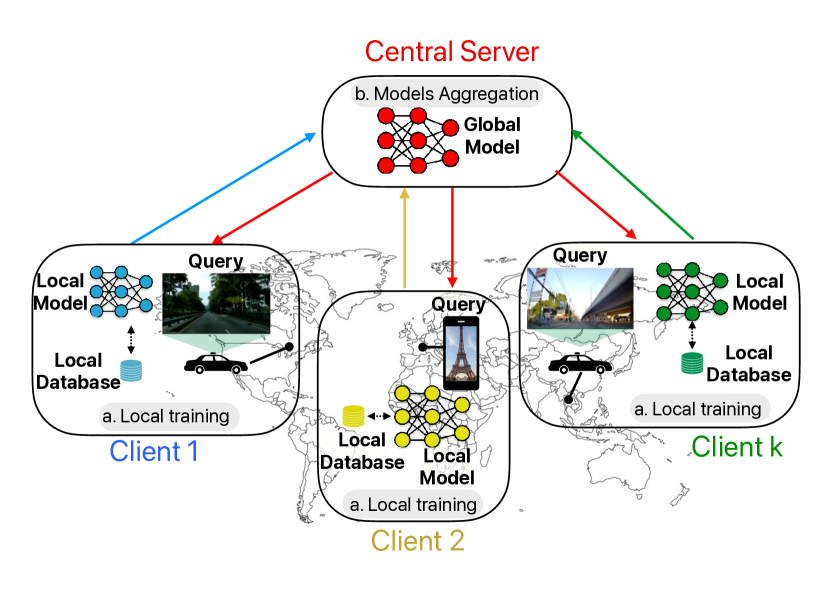
The system consists of a central server and multiple client devices. Each client device has a local VPR model, which is trained on the device's own visual data. The clients periodically send model updates to the server, which aggregates the updates and sends the global model back to the clients. This process continues iteratively, allowing the clients to collaboratively learn a shared VPR model.
The key innovation is the use of federated learning, which enables the clients to learn from each other's visual data without directly sharing the raw data. This preserves the privacy of the user data while still allowing the model to benefit from the complementary visual information across devices.
The authors evaluate the federated learning-based VPR system on a large-scale dataset of street-view images. They compare its performance to a centralized VPR model trained on pooled data from all devices, as well as a model trained on the pooled data directly. The results show that the federated learning approach outperforms the centralized model and achieves comparable performance to the model trained on pooled data, demonstrating the effectiveness of the proposed system.
Critical Analysis
The paper presents a promising approach to collaborative VPR that preserves user privacy through the use of federated learning. The key strengths of the research are:
- The ability to leverage complementary visual information from multiple devices without sharing raw data, which addresses an important privacy concern in centralized VPR systems.
- The experimental results showing that the federated learning-based VPR outperforms a centralized model and achieves comparable performance to a model trained on pooled data.
- The potential for this approach to be applied to other computer vision tasks beyond VPR, where privacy-preserving collaborative learning could be beneficial.
However, the paper also has some limitations:
- The experiments were conducted on a single, large-scale dataset of street-view images, which may not fully capture the diversity of real-world VPR scenarios. Further evaluation on more varied datasets would be valuable.
- The paper does not address potential issues with federated learning, such as the challenge of handling non-independent and identically distributed (non-IID) data across devices or the communication overhead of exchanging model updates.
- The paper does not provide a detailed analysis of the privacy guarantees of the proposed system, which would be important for understanding its practical applicability.
Overall, the paper presents an interesting and promising approach to collaborative VPR, but further research is needed to address the limitations and explore the broader implications of this work.
Conclusion
This paper introduces a collaborative visual place recognition (VPR) system that uses federated learning to preserve user privacy while still allowing multiple devices to learn from each other's visual data. The key innovation is the use of federated learning, which enables the devices to collaboratively train a shared VPR model without exchanging raw data.
The experimental results show that this federated learning-based VPR system outperforms a centralized VPR model and achieves comparable performance to a model trained on pooled data from all devices. This demonstrates the potential of this approach to improve VPR while preserving user privacy, which is an important consideration for real-world applications.
The paper also highlights the broader applicability of this federated learning approach to other computer vision tasks where privacy-preserving collaborative learning could be beneficial. Further research is needed to address the limitations of the current work and explore the practical implications of this technology for various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Collaborative Visual Place Recognition through Federated Learning
Mattia Dutto, Gabriele Berton, Debora Caldarola, Eros Fan`i, Gabriele Trivigno, Carlo Masone
Visual Place Recognition (VPR) aims to estimate the location of an image by treating it as a retrieval problem. VPR uses a database of geo-tagged images and leverages deep neural networks to extract a global representation, called descriptor, from each image. While the training data for VPR models often originates from diverse, geographically scattered sources (geo-tagged images), the training process itself is typically assumed to be centralized. This research revisits the task of VPR through the lens of Federated Learning (FL), addressing several key challenges associated with this adaptation. VPR data inherently lacks well-defined classes, and models are typically trained using contrastive learning, which necessitates a data mining step on a centralized database. Additionally, client devices in federated systems can be highly heterogeneous in terms of their processing capabilities. The proposed FedVPR framework not only presents a novel approach for VPR but also introduces a new, challenging, and realistic task for FL research, paving the way to other image retrieval tasks in FL.
Read more4/23/2024

0
Register assisted aggregation for Visual Place Recognition
Xuan Yu, Zhenyong Fu
Visual Place Recognition (VPR) refers to the process of using computer vision to recognize the position of the current query image. Due to the significant changes in appearance caused by season, lighting, and time spans between query images and database images for retrieval, these differences increase the difficulty of place recognition. Previous methods often discarded useless features (such as sky, road, vehicles) while uncontrolled discarding features that help improve recognition accuracy (such as buildings, trees). To preserve these useful features, we propose a new feature aggregation method to address this issue. Specifically, in order to obtain global and local features that contain discriminative place information, we added some registers on top of the original image tokens to assist in model training. After reallocating attention weights, these registers were discarded. The experimental results show that these registers surprisingly separate unstable features from the original image representation and outperform state-of-the-art methods.
Read more5/21/2024

0
Towards Seamless Adaptation of Pre-trained Models for Visual Place Recognition
Feng Lu, Lijun Zhang, Xiangyuan Lan, Shuting Dong, Yaowei Wang, Chun Yuan
Recent studies show that vision models pre-trained in generic visual learning tasks with large-scale data can provide useful feature representations for a wide range of visual perception problems. However, few attempts have been made to exploit pre-trained foundation models in visual place recognition (VPR). Due to the inherent difference in training objectives and data between the tasks of model pre-training and VPR, how to bridge the gap and fully unleash the capability of pre-trained models for VPR is still a key issue to address. To this end, we propose a novel method to realize seamless adaptation of pre-trained models for VPR. Specifically, to obtain both global and local features that focus on salient landmarks for discriminating places, we design a hybrid adaptation method to achieve both global and local adaptation efficiently, in which only lightweight adapters are tuned without adjusting the pre-trained model. Besides, to guide effective adaptation, we propose a mutual nearest neighbor local feature loss, which ensures proper dense local features are produced for local matching and avoids time-consuming spatial verification in re-ranking. Experimental results show that our method outperforms the state-of-the-art methods with less training data and training time, and uses about only 3% retrieval runtime of the two-stage VPR methods with RANSAC-based spatial verification. It ranks 1st on the MSLS challenge leaderboard (at the time of submission). The code is released at https://github.com/Lu-Feng/SelaVPR.
Read more4/4/2024

0
Visual place recognition for aerial imagery: A survey
Ivan Moskalenko, Anastasiia Kornilova, Gonzalo Ferrer
Aerial imagery and its direct application to visual localization is an essential problem for many Robotics and Computer Vision tasks. While Global Navigation Satellite Systems (GNSS) are the standard default solution for solving the aerial localization problem, it is subject to a number of limitations, such as, signal instability or solution unreliability that make this option not so desirable. Consequently, visual geolocalization is emerging as a viable alternative. However, adapting Visual Place Recognition (VPR) task to aerial imagery presents significant challenges, including weather variations and repetitive patterns. Current VPR reviews largely neglect the specific context of aerial data. This paper introduces a methodology tailored for evaluating VPR techniques specifically in the domain of aerial imagery, providing a comprehensive assessment of various methods and their performance. However, we not only compare various VPR methods, but also demonstrate the importance of selecting appropriate zoom and overlap levels when constructing map tiles to achieve maximum efficiency of VPR algorithms in the case of aerial imagery. The code is available on our GitHub repository -- https://github.com/prime-slam/aero-vloc.
Read more6/4/2024