Optimization and Generalization Guarantees for Weight Normalization

0
Sign in to get full access
Overview
- The paper explores optimization and generalization guarantees for weight normalization, a technique used to improve the training and performance of neural networks.
- It analyzes the theoretical properties of weight normalization and provides new insights into its benefits.
- The findings could lead to improved training methods and better-performing neural network models.
Plain English Explanation
Weight normalization is a technique used in deep learning to help neural networks train more effectively. It involves adjusting the weights (the numerical parameters) of the network in a specific way during the training process.
The key idea behind weight normalization is to separate the magnitude of the weights from their direction. This separation can make the training process smoother and more stable, leading to better performance on both the training data and new, unseen data (generalization).
The paper in question provides a detailed mathematical analysis of weight normalization. It demonstrates that weight normalization can improve the optimization process by making the objective function (the thing the network is trying to minimize) more well-behaved. This can lead to faster convergence and better final performance.
Additionally, the paper shows that weight normalization can provide generalization guarantees. This means that networks trained with weight normalization are more likely to perform well on new data, not just the data they were trained on.
Overall, the findings in this paper could help researchers and practitioners design better neural network architectures and training algorithms, leading to more robust and effective machine learning models.
Technical Explanation
The paper begins by introducing weight normalization, a technique that has been shown to improve the optimization and generalization of neural networks. The key idea is to separate the magnitude of the weights from their direction by normalizing the weights during the training process.
The authors then provide a theoretical analysis of weight normalization. They show that weight normalization can improve the optimization process by making the objective function more well-behaved. Specifically, they prove that weight normalization can reduce the condition number of the Hessian (a measure of the curvature of the objective function), leading to faster convergence and better final performance.
Furthermore, the paper demonstrates that weight normalization can provide generalization guarantees. The authors show that weight normalization can improve the Gaussian width of the weight vectors, which is a measure of the complexity of the function class represented by the neural network. This, in turn, can lead to better generalization performance on new, unseen data.
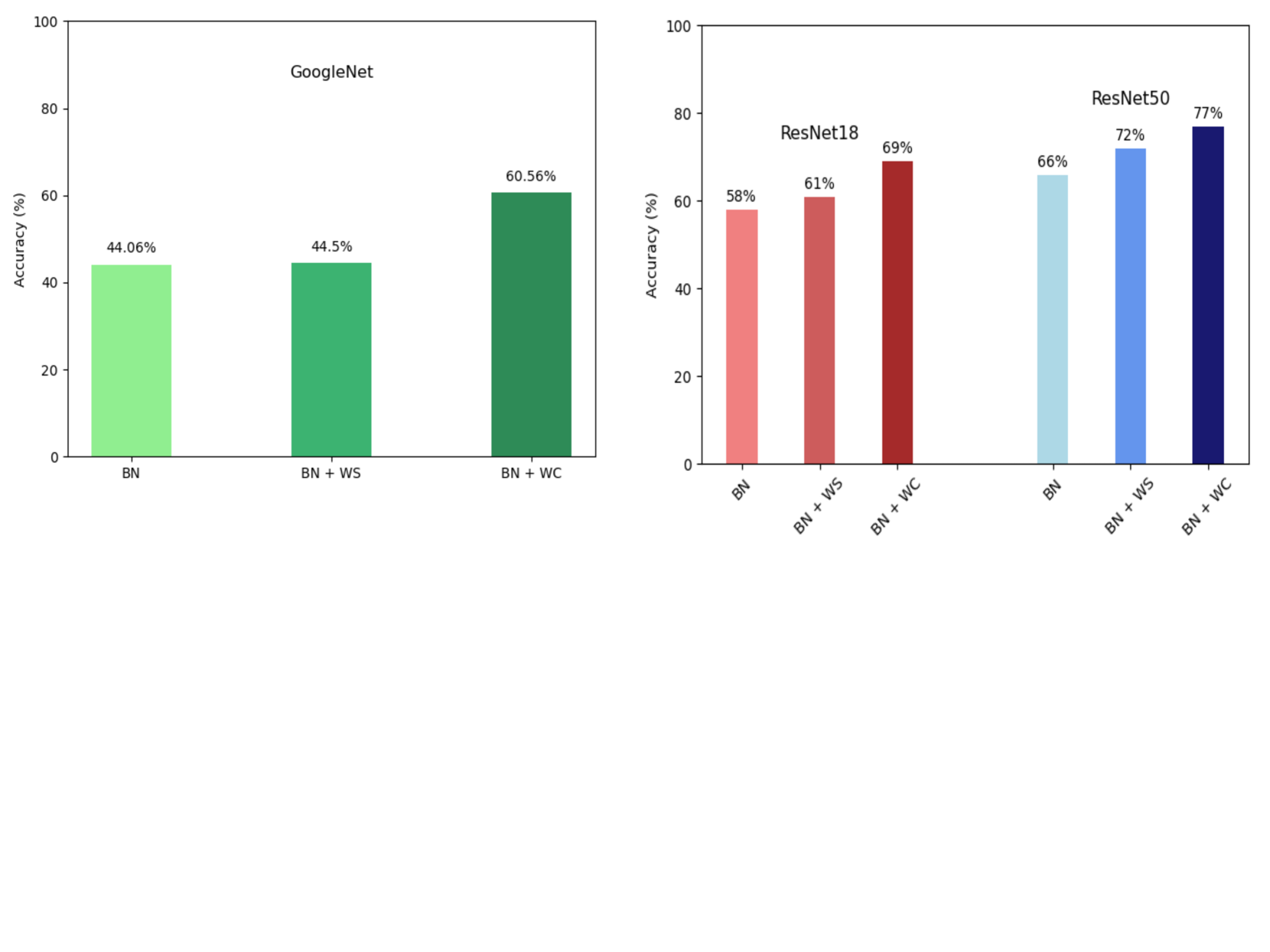
The paper also includes experiments on various neural network architectures and datasets, which validate the theoretical findings and demonstrate the practical benefits of weight normalization.
Critical Analysis
The paper provides a rigorous theoretical analysis of weight normalization and its impact on optimization and generalization. The proofs and mathematical insights are well-explained and contribute to a deeper understanding of this important technique.
However, the paper does not explore potential limitations or caveats of weight normalization. For example, it does not discuss how weight normalization might interact with other regularization techniques or the impact of hyperparameter choices on the performance gains.
Additionally, the experimental evaluation, while comprehensive, could be expanded to include more diverse datasets and architectures. This would help to further validate the generality of the findings and identify any potential edge cases or limitations.
Overall, the paper makes a valuable contribution to the literature on weight normalization and its theoretical properties. The insights presented could inform the development of more effective neural network training methods and architectures.
Conclusion
This paper offers a detailed analysis of the optimization and generalization properties of weight normalization, a widely used technique in deep learning. The authors provide mathematical proofs demonstrating that weight normalization can improve the optimization process and lead to better generalization performance.
These findings have important implications for the design of neural network architectures and training algorithms. By understanding the theoretical underpinnings of weight normalization, researchers and practitioners can develop more effective machine learning models that are both efficient to train and robust to new data.
Overall, this paper represents a significant contribution to the field of deep learning and provides a solid foundation for future research on weight normalization and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimization and Generalization Guarantees for Weight Normalization
Pedro Cisneros-Velarde, Zhijie Chen, Sanmi Koyejo, Arindam Banerjee
Weight normalization (WeightNorm) is widely used in practice for the training of deep neural networks and modern deep learning libraries have built-in implementations of it. In this paper, we provide the first theoretical characterizations of both optimization and generalization of deep WeightNorm models with smooth activation functions. For optimization, from the form of the Hessian of the loss, we note that a small Hessian of the predictor leads to a tractable analysis. Thus, we bound the spectral norm of the Hessian of WeightNorm networks and show its dependence on the network width and weight normalization terms--the latter being unique to networks without WeightNorm. Then, we use this bound to establish training convergence guarantees under suitable assumptions for gradient decent. For generalization, we use WeightNorm to get a uniform convergence based generalization bound, which is independent from the width and depends sublinearly on the depth. Finally, we present experimental results which illustrate how the normalization terms and other quantities of theoretical interest relate to the training of WeightNorm networks.
Read more9/16/2024
0
Weight Conditioning for Smooth Optimization of Neural Networks
Hemanth Saratchandran, Thomas X. Wang, Simon Lucey
In this article, we introduce a novel normalization technique for neural network weight matrices, which we term weight conditioning. This approach aims to narrow the gap between the smallest and largest singular values of the weight matrices, resulting in better-conditioned matrices. The inspiration for this technique partially derives from numerical linear algebra, where well-conditioned matrices are known to facilitate stronger convergence results for iterative solvers. We provide a theoretical foundation demonstrating that our normalization technique smoothens the loss landscape, thereby enhancing convergence of stochastic gradient descent algorithms. Empirically, we validate our normalization across various neural network architectures, including Convolutional Neural Networks (CNNs), Vision Transformers (ViT), Neural Radiance Fields (NeRF), and 3D shape modeling. Our findings indicate that our normalization method is not only competitive but also outperforms existing weight normalization techniques from the literature.
Read more9/6/2024
🔗
0
Robust Implicit Regularization via Weight Normalization
Hung-Hsu Chou, Holger Rauhut, Rachel Ward
Overparameterized models may have many interpolating solutions; implicit regularization refers to the hidden preference of a particular optimization method towards a certain interpolating solution among the many. A by now established line of work has shown that (stochastic) gradient descent tends to have an implicit bias towards low rank and/or sparse solutions when used to train deep linear networks, explaining to some extent why overparameterized neural network models trained by gradient descent tend to have good generalization performance in practice. However, existing theory for square-loss objectives often requires very small initialization of the trainable weights, which is at odds with the larger scale at which weights are initialized in practice for faster convergence and better generalization performance. In this paper, we aim to close this gap by incorporating and analyzing gradient flow (continuous-time version of gradient descent) with weight normalization, where the weight vector is reparameterized in terms of polar coordinates, and gradient flow is applied to the polar coordinates. By analyzing key invariants of the gradient flow and using Lojasiewicz Theorem, we show that weight normalization also has an implicit bias towards sparse solutions in the diagonal linear model, but that in contrast to plain gradient flow, weight normalization enables a robust bias that persists even if the weights are initialized at practically large scale. Experiments suggest that the gains in both convergence speed and robustness of the implicit bias are improved dramatically by using weight normalization in overparameterized diagonal linear network models.
Read more8/26/2024
🛠️
0
Scalable Optimization in the Modular Norm
Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, Jeremy Bernstein
To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the natural norm particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from well-behaved atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. The package is available via pip install modula with source code at https://github.com/jxbz/modula.
Read more5/24/2024