Weight Conditioning for Smooth Optimization of Neural Networks

0
Sign in to get full access
Overview
- Weight conditioning helps neural networks train more smoothly
- Researchers propose a new weight conditioning method to improve optimization
- Experiments show the method leads to faster convergence and better generalization
Plain English Explanation
Weight conditioning is a technique used to improve the training of neural networks. Neural networks are made up of layers of interconnected nodes, and each node has a set of weights that determine how it responds to input data. The researchers in this paper propose a new weight conditioning method to help the network's weights train more smoothly and efficiently.
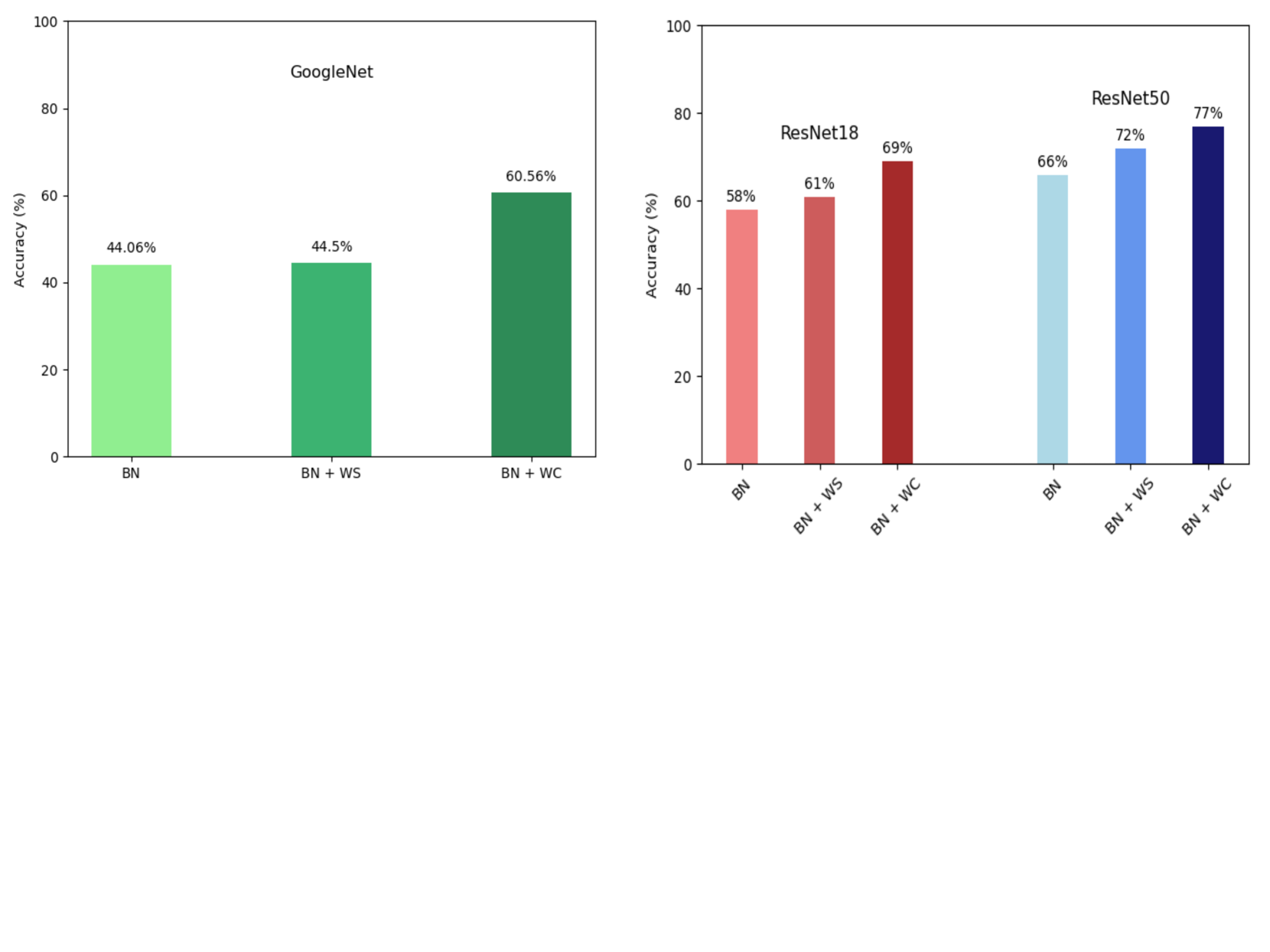
The key idea is to normalize the weights in a way that makes the optimization process more stable and less sensitive to the initial conditions. This helps the network converge faster during training and also leads to better performance on new, unseen data (generalization). The researchers show through experiments that their weight conditioning approach outperforms other normalization techniques in terms of convergence speed and generalization ability.
Technical Explanation
The paper introduces a new weight conditioning method called "Smooth Weight Normalization" (SWN). SWN normalizes the weights of a neural network in a way that aims to improve the conditioning of the optimization problem, making it more amenable to efficient gradient-based optimization.
Specifically, SWN enforces a constraint on the spectral norm of the weight matrices, which helps control the curvature of the optimization landscape. This in turn leads to smoother and more stable optimization, as evidenced by the authors' experiments comparing SWN to other normalization techniques like batch normalization.
The authors demonstrate the benefits of SWN on a range of neural network architectures and tasks, showing faster convergence and better generalization performance compared to baseline methods. They also provide theoretical analysis to explain the advantages of their approach in terms of modular norm regularization.
Critical Analysis
The paper presents a well-designed and thorough analysis of the proposed weight conditioning method. The experiments cover a range of network types and tasks, providing robust evidence for the benefits of SWN.
However, the authors acknowledge that SWN may not be optimal for all scenarios, as the spectral norm constraint could limit the expressivity of the network in some cases. There is also the potential for the method to be computationally more expensive than simpler normalization techniques, depending on the specific implementation.
Additionally, the paper does not extensively explore the interactions between SWN and other popular techniques like skip connections or residual blocks. Further research may be needed to understand how SWN integrates with these architectural elements.
Overall, the paper makes a compelling case for the advantages of weight conditioning and provides a promising new approach in SWN. The insights and findings could prove valuable for researchers and practitioners looking to improve the optimization and generalization of their neural networks.
Conclusion
This paper introduces a new weight conditioning method called Smooth Weight Normalization (SWN) that helps neural networks train more efficiently and generalize better. The key idea is to normalize the weights in a way that improves the conditioning of the optimization problem, leading to faster convergence and improved performance on new data.
The authors demonstrate the benefits of SWN through extensive experiments on a range of network architectures and tasks. While there are some potential limitations and areas for further investigation, the paper makes a strong contribution to the field of neural network optimization and provides a useful tool for improving the training and performance of deep learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Weight Conditioning for Smooth Optimization of Neural Networks
Hemanth Saratchandran, Thomas X. Wang, Simon Lucey
In this article, we introduce a novel normalization technique for neural network weight matrices, which we term weight conditioning. This approach aims to narrow the gap between the smallest and largest singular values of the weight matrices, resulting in better-conditioned matrices. The inspiration for this technique partially derives from numerical linear algebra, where well-conditioned matrices are known to facilitate stronger convergence results for iterative solvers. We provide a theoretical foundation demonstrating that our normalization technique smoothens the loss landscape, thereby enhancing convergence of stochastic gradient descent algorithms. Empirically, we validate our normalization across various neural network architectures, including Convolutional Neural Networks (CNNs), Vision Transformers (ViT), Neural Radiance Fields (NeRF), and 3D shape modeling. Our findings indicate that our normalization method is not only competitive but also outperforms existing weight normalization techniques from the literature.
Read more9/6/2024
0
Optimization and Generalization Guarantees for Weight Normalization
Pedro Cisneros-Velarde, Zhijie Chen, Sanmi Koyejo, Arindam Banerjee
Weight normalization (WeightNorm) is widely used in practice for the training of deep neural networks and modern deep learning libraries have built-in implementations of it. In this paper, we provide the first theoretical characterizations of both optimization and generalization of deep WeightNorm models with smooth activation functions. For optimization, from the form of the Hessian of the loss, we note that a small Hessian of the predictor leads to a tractable analysis. Thus, we bound the spectral norm of the Hessian of WeightNorm networks and show its dependence on the network width and weight normalization terms--the latter being unique to networks without WeightNorm. Then, we use this bound to establish training convergence guarantees under suitable assumptions for gradient decent. For generalization, we use WeightNorm to get a uniform convergence based generalization bound, which is independent from the width and depends sublinearly on the depth. Finally, we present experimental results which illustrate how the normalization terms and other quantities of theoretical interest relate to the training of WeightNorm networks.
Read more9/16/2024
🔗
0
Robust Implicit Regularization via Weight Normalization
Hung-Hsu Chou, Holger Rauhut, Rachel Ward
Overparameterized models may have many interpolating solutions; implicit regularization refers to the hidden preference of a particular optimization method towards a certain interpolating solution among the many. A by now established line of work has shown that (stochastic) gradient descent tends to have an implicit bias towards low rank and/or sparse solutions when used to train deep linear networks, explaining to some extent why overparameterized neural network models trained by gradient descent tend to have good generalization performance in practice. However, existing theory for square-loss objectives often requires very small initialization of the trainable weights, which is at odds with the larger scale at which weights are initialized in practice for faster convergence and better generalization performance. In this paper, we aim to close this gap by incorporating and analyzing gradient flow (continuous-time version of gradient descent) with weight normalization, where the weight vector is reparameterized in terms of polar coordinates, and gradient flow is applied to the polar coordinates. By analyzing key invariants of the gradient flow and using Lojasiewicz Theorem, we show that weight normalization also has an implicit bias towards sparse solutions in the diagonal linear model, but that in contrast to plain gradient flow, weight normalization enables a robust bias that persists even if the weights are initialized at practically large scale. Experiments suggest that the gains in both convergence speed and robustness of the implicit bias are improved dramatically by using weight normalization in overparameterized diagonal linear network models.
Read more8/26/2024
🛠️
0
Scalable Optimization in the Modular Norm
Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, Jeremy Bernstein
To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the natural norm particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from well-behaved atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. The package is available via pip install modula with source code at https://github.com/jxbz/modula.
Read more5/24/2024