Optimized thread-block arrangement in a GPU implementation of a linear solver for atmospheric chemistry mechanisms

0

Sign in to get full access
Overview
- This paper presents an optimized thread-block arrangement for a GPU implementation of a linear solver used in atmospheric chemistry mechanisms.
- The goal is to improve the performance and efficiency of the linear solver, which is a critical component in atmospheric chemistry simulations.
- The researchers explore different thread-block configurations and their impact on the solver's performance, aiming to find the most efficient arrangement.
Plain English Explanation
The paper focuses on improving the performance of a computer program that helps scientists understand the chemical processes in the Earth's atmosphere. This program uses a mathematical technique called a "linear solver" to model the complex interactions between different chemical compounds.
When running this program on a powerful graphics processing unit (GPU), the researchers found that the way the program divides up the work into smaller tasks (called "thread-blocks") had a big impact on how fast the program could run. They tested out different arrangements of these thread-blocks and measured how well the program performed with each one.
By carefully optimizing the thread-block configuration, the researchers were able to make the program run much faster, allowing scientists to simulate atmospheric chemistry more accurately and efficiently. This is important for improving our understanding of the Earth's atmosphere and how it responds to changes, which can help us address environmental challenges like air pollution and climate change.
Technical Explanation
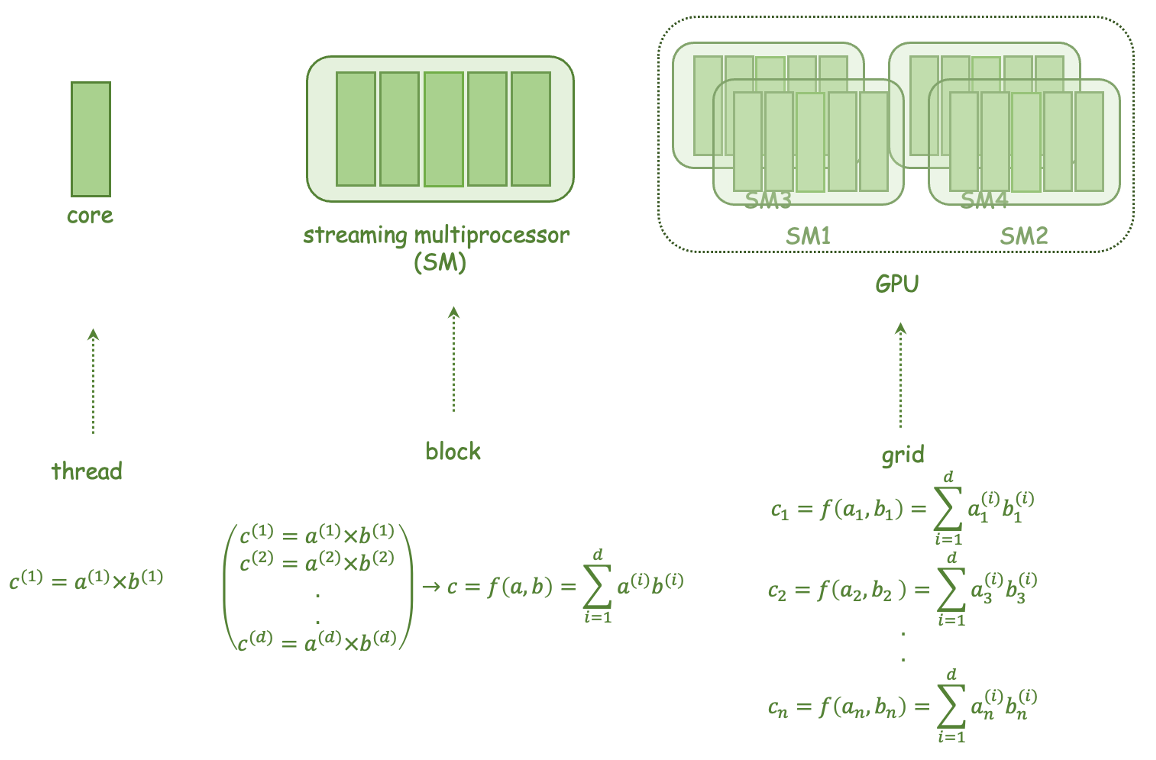
The paper describes an optimized thread-block arrangement for a GPU implementation of a linear solver used in atmospheric chemistry mechanisms. The linear solver is a critical component in these simulations, as it allows the modeling of complex chemical interactions and processes.
The researchers explore different thread-block configurations and their impact on the performance of the linear solver. They analyze factors such as the number of threads per block, the number of blocks, and the way the work is distributed across the GPU's computational resources.
Through extensive experimentation and analysis, the researchers identify an optimal thread-block arrangement that significantly improves the efficiency and speed of the linear solver. This optimized configuration takes advantage of the GPU's parallel processing capabilities to accelerate the calculations required for the atmospheric chemistry simulations.
The findings from this research can be applied to other GPU-accelerated scientific computing applications that rely on linear solvers, helping to improve the overall performance and efficiency of these computationally intensive simulations. This builds on previous work on GPU acceleration for scientific simulations, such as the fluid-implicit particle simulation and the experience analysis of scalable high-fidelity computational fluid dynamics](https://aimodels.fyi/papers/arxiv/experience-analysis-scalable-high-fidelity-computational-fluid).
Critical Analysis
The paper provides a thorough and well-designed study of the thread-block arrangement for the linear solver in the atmospheric chemistry application. The researchers have carefully explored various configurations and reported on their findings in a clear and detailed manner.
One potential limitation of the study is that it focuses solely on the linear solver component, without considering the overall performance and integration of the solver within the larger atmospheric chemistry simulation framework. It would be valuable to understand how the optimized thread-block arrangement impacts the overall simulation performance and scalability.
Additionally, the paper does not provide much insight into the specific challenges or trade-offs encountered in the optimization process. It would be interesting to understand the key factors that guided the researchers' decisions and the strategies they employed to overcome any technical obstacles.
Further research could explore the applicability of the optimized thread-block arrangement to other GPU-accelerated scientific computing domains, such as particle-cell Monte Carlo simulations or distributed-memory parallel matrix computations. This could help establish the generalizability of the findings and provide a more comprehensive understanding of GPU optimization techniques for scientific applications.
Conclusion
This paper presents a detailed study on optimizing the thread-block arrangement for a GPU implementation of a linear solver used in atmospheric chemistry simulations. By carefully exploring different configurations and their impact on performance, the researchers were able to identify an optimal setup that significantly improves the efficiency and speed of the linear solver.
The findings from this research can have important implications for the field of atmospheric science, as it enables more accurate and efficient modeling of the complex chemical processes in the Earth's atmosphere. This, in turn, can contribute to a better understanding of environmental challenges and support the development of effective solutions to address issues like air pollution and climate change.
The techniques and insights presented in this paper can also be leveraged in other GPU-accelerated scientific computing applications that rely on linear solvers, helping to advance the state of the art in high-performance scientific computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimized thread-block arrangement in a GPU implementation of a linear solver for atmospheric chemistry mechanisms
Christian Guzman Ruiz, Mario Acosta, Oriol Jorba, Eduardo Cesar Galobardes, Matthew Dawson, Guillermo Oyarzun, Carlos P'erez Garc'ia-Pando, Kim Serradell
Earth system models (ESM) demand significant hardware resources and energy consumption to solve atmospheric chemistry processes. Recent studies have shown improved performance from running these models on GPU accelerators. Nonetheless, there is room for improvement in exploiting even more GPU resources. This study proposes an optimized distribution of the chemical solver's computational load on the GPU, named Block-cells. Additionally, we evaluate different configurations for distributing the computational load in an NVIDIA GPU. We use the linear solver from the Chemistry Across Multiple Phases (CAMP) framework as our test bed. An intermediate-complexity chemical mechanism under typical atmospheric conditions is used. Results demonstrate a 35x speedup compared to the single-CPU thread reference case. Even using the full resources of the node (40 physical cores) on the reference case, the Block-cells version outperforms them by 50%. The Block-cells approach shows promise in alleviating the computational burden of chemical solvers on GPU architectures.
Read more5/28/2024
0
A Preliminary Study on Accelerating Simulation Optimization with GPU Implementation
Jinghai He, Haoyu Liu, Yuhang Wu, Zeyu Zheng, Tingyu Zhu
We provide a preliminary study on utilizing GPU (Graphics Processing Unit) to accelerate computation for three simulation optimization tasks with either first-order or second-order algorithms. Compared to the implementation using only CPU (Central Processing Unit), the GPU implementation benefits from computational advantages of parallel processing for large-scale matrices and vectors operations. Numerical experiments demonstrate computational advantages of utilizing GPU implementation in simulation optimization problems, and show that such advantage comparatively further increase as the problem scale increases.
Read more4/19/2024

0
Energy efficiency: a Lattice Boltzmann study
Matteo Turisini, Giorgio Amati, Andrea Acquaviva
The energy consumption and the compute performance of a fluid dynamic code have been investigated varying parallelization approach, arithmetic precision and clock speed. The code is based on a Lattice Boltzmann approximation, is written in Fortran and was executed on high-end GPUs of Leonardo Booster supercomputer. Tests were conducted on single server nodes (up to 4 GPUs in parallel). Performance metrics like the number of operations per second and energy consumption are reported, to quantify how smart coding approach and system adjustment can contribute to reduction of energy footprint while keeping the scientific throughput almost unaltered or with acceptable level of degradation. Results indicate that this application can be executed with 20% of energy saving and reduced thermal stress, at the cost of 5% more computing time. The paper presents preliminary conclusions, as it is a first step of a larger study dedicated to energy efficiency at scale.
Read more6/18/2024

0
A simple GPU implementation of spectral-element methods for solving 3D Poisson type equations on rectangular domains and its applications
Xinyu Liu, Jie Shen, Xiangxiong Zhang
It is well known since 1960s that by exploring the tensor product structure of the discrete Laplacian on Cartesian meshes, one can develop a simple direct Poisson solver with an $mathcal O(N^{frac{d+1}d})$ complexity in d-dimension, where N is the number of the total unknowns. The GPU acceleration of numerically solving PDEs has been explored successfully around fifteen years ago and become more and more popular in the past decade, driven by significant advancement in both hardware and software technologies, especially in the recent few years. We present in this paper a simple but extremely fast MATLAB implementation on a modern GPU, which can be easily reproduced, for solving 3D Poisson type equations using a spectral-element method. In particular, it costs less than one second on a Nvidia A100 for solving a Poisson equation with one billion degree of freedoms. We also present applications of this fast solver to solve a linear (time-independent) Schrodinger equation and a nonlinear (time-dependent) Cahn-Hilliard equation.
Read more6/13/2024