Optimizing Long-tailed Link Prediction in Graph Neural Networks through Structure Representation Enhancement

0

Sign in to get full access
Overview
- Optimizes long-tailed link prediction in graph neural networks
- Enhances the structure representation to improve model performance
- Focuses on tackling the challenges posed by long-tailed link distributions in real-world graphs
Plain English Explanation
Link prediction is the task of identifying potential connections between nodes in a graph-structured dataset. [object Object] are a powerful tool for this, but they can struggle with long-tailed link distributions - where most links occur between a small number of popular nodes, and the majority of nodes have very few links.
This paper proposes a new approach to enhance the structure representation in graph neural networks, making them better able to handle long-tailed link prediction problems. The key idea is to capture more nuanced information about the local graph structure around each node, beyond just the node's degree or neighborhood size.
By improving the model's understanding of the graph structure, the researchers were able to significantly boost the accuracy of link prediction, especially for those less common, long-tailed links. This could have important applications in areas like social network analysis, recommender systems, and knowledge graph completion.
Technical Explanation
The authors introduce a structure representation enhancement (SRE) module that can be integrated into existing graph neural network architectures. This module learns an additional set of embeddings to capture more detailed structural features of each node's local neighborhood.
Specifically, the SRE module learns:
- Degree embeddings: Representing the node's degree (number of neighbors)
- Neighborhood size embeddings: Representing the size of the node's local neighborhood
- Structural similarity embeddings: Representing the structural similarity between the node and its neighbors
These enhanced structural representations are then combined with the node's initial features and passed through the graph neural network layers to improve link prediction performance.
The authors evaluate their approach on several real-world graph datasets with long-tailed link distributions. They show that integrating the SRE module leads to significant improvements in link prediction accuracy, especially for the less common, long-tailed links that are often challenging for standard graph neural networks to capture.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed SRE module, including comparisons to various baseline methods. However, a few potential limitations or areas for further research are worth noting:
-
Scalability: The authors demonstrate the effectiveness of their approach on relatively small graph datasets. It would be valuable to explore the scalability of the SRE module to larger, more complex real-world graphs.
-
Interpretability: While the enhanced structural representations improve model performance, it could be useful to provide more insight into how these representations are capturing the relevant graph properties and why they are beneficial for long-tailed link prediction.
-
Generalization: The paper focuses on link prediction, but the SRE module could potentially be applied to other graph-based tasks, such as node classification or graph classification. Exploring the broader applicability of the approach would be an interesting direction for future research.
Conclusion
This paper presents a novel approach to improving graph neural networks for long-tailed link prediction tasks. By enhancing the structure representation of each node, the proposed SRE module helps the model better capture the nuanced graph properties that are crucial for accurately predicting less common links. The significant performance gains demonstrated on real-world datasets suggest that this technique could have valuable applications in a wide range of graph-based machine learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Long-tailed Link Prediction in Graph Neural Networks through Structure Representation Enhancement
Yakun Wang, Daixin Wang, Hongrui Liu, Binbin Hu, Yingcui Yan, Qiyang Zhang, Zhiqiang Zhang
Link prediction, as a fundamental task for graph neural networks (GNNs), has boasted significant progress in varied domains. Its success is typically influenced by the expressive power of node representation, but recent developments reveal the inferior performance of low-degree nodes owing to their sparse neighbor connections, known as the degree-based long-tailed problem. Will the degree-based long-tailed distribution similarly constrain the efficacy of GNNs on link prediction? Unexpectedly, our study reveals that only a mild correlation exists between node degree and predictive accuracy, and more importantly, the number of common neighbors between node pairs exhibits a strong correlation with accuracy. Considering node pairs with less common neighbors, i.e., tail node pairs, make up a substantial fraction of the dataset but achieve worse performance, we propose that link prediction also faces the long-tailed problem. Therefore, link prediction of GNNs is greatly hindered by the tail node pairs. After knowing the weakness of link prediction, a natural question is how can we eliminate the negative effects of the skewed long-tailed distribution on common neighbors so as to improve the performance of link prediction? Towards this end, we introduce our long-tailed framework (LTLP), which is designed to enhance the performance of tail node pairs on link prediction by increasing common neighbors. Two key modules in LTLP respectively supplement high-quality edges for tail node pairs and enforce representational alignment between head and tail node pairs within the same category, thereby improving the performance of tail node pairs.
Read more7/31/2024

0
Probability Passing for Graph Neural Networks: Graph Structure and Representations Joint Learning
Ziyan Wang, YaXuan He, Bin Liu
Graph Neural Networks (GNNs) have achieved notable success in the analysis of non-Euclidean data across a wide range of domains. However, their applicability is constrained by the dependence on the observed graph structure. To solve this problem, Latent Graph Inference (LGI) is proposed to infer a task-specific latent structure by computing similarity or edge probability of node features and then apply a GNN to produce predictions. Even so, existing approaches neglect the noise from node features, which affects generated graph structure and performance. In this work, we introduce a novel method called Probability Passing to refine the generated graph structure by aggregating edge probabilities of neighboring nodes based on observed graph. Furthermore, we continue to utilize the LGI framework, inputting the refined graph structure and node features into GNNs to obtain predictions. We name the proposed scheme as Probability Passing-based Graph Neural Network (PPGNN). Moreover, the anchor-based technique is employed to reduce complexity and improve efficiency. Experimental results demonstrate the effectiveness of the proposed method.
Read more7/16/2024
0
LinkGPT: Teaching Large Language Models To Predict Missing Links
Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, Danai Koutra
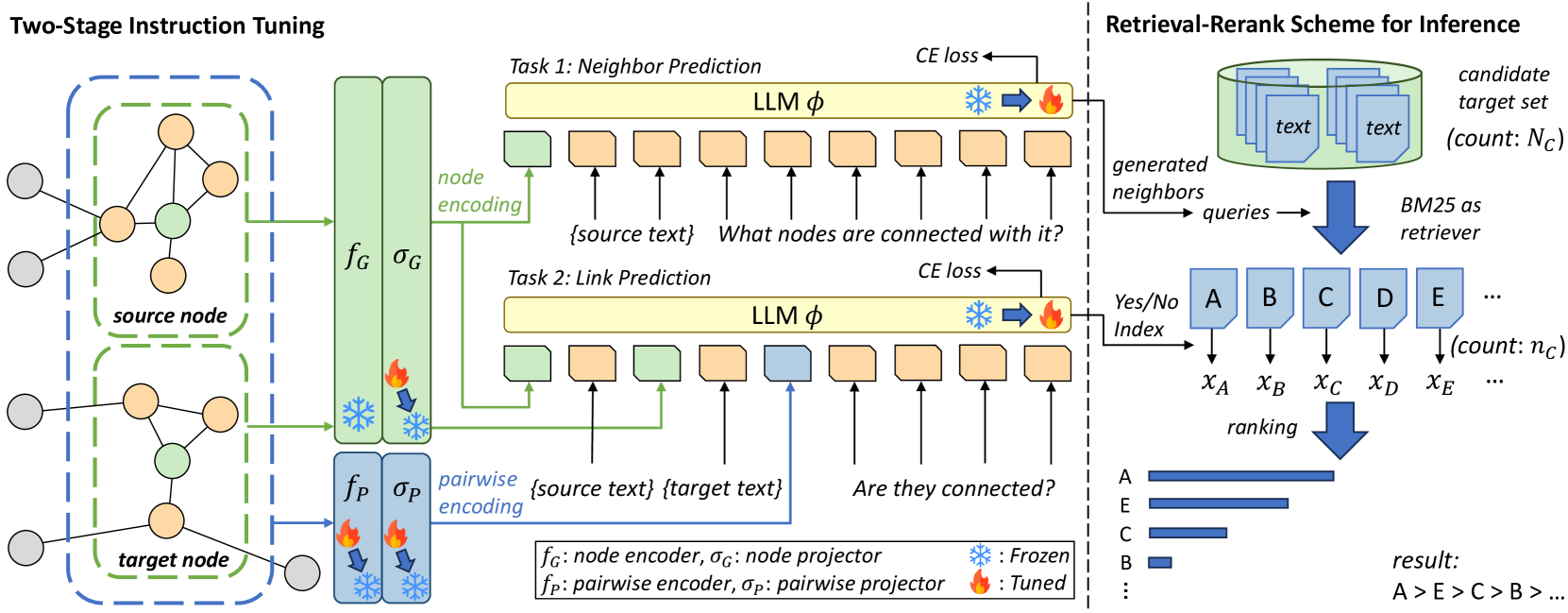
Large Language Models (LLMs) have shown promising results on various language and vision tasks. Recently, there has been growing interest in applying LLMs to graph-based tasks, particularly on Text-Attributed Graphs (TAGs). However, most studies have focused on node classification, while the use of LLMs for link prediction (LP) remains understudied. In this work, we propose a new task on LLMs, where the objective is to leverage LLMs to predict missing links between nodes in a graph. This task evaluates an LLM's ability to reason over structured data and infer new facts based on learned patterns. This new task poses two key challenges: (1) How to effectively integrate pairwise structural information into the LLMs, which is known to be crucial for LP performance, and (2) how to solve the computational bottleneck when teaching LLMs to perform LP. To address these challenges, we propose LinkGPT, the first end-to-end trained LLM for LP tasks. To effectively enhance the LLM's ability to understand the underlying structure, we design a two-stage instruction tuning approach where the first stage fine-tunes the pairwise encoder, projector, and node projector, and the second stage further fine-tunes the LLMs to predict links. To address the efficiency challenges at inference time, we introduce a retrieval-reranking scheme. Experiments show that LinkGPT can achieve state-of-the-art performance on real-world graphs as well as superior generalization in zero-shot and few-shot learning, surpassing existing benchmarks. At inference time, it can achieve $10times$ speedup while maintaining high LP accuracy.
Read more6/10/2024
0
Learning Latent Graph Structures and their Uncertainty
Alessandro Manenti, Daniele Zambon, Cesare Alippi
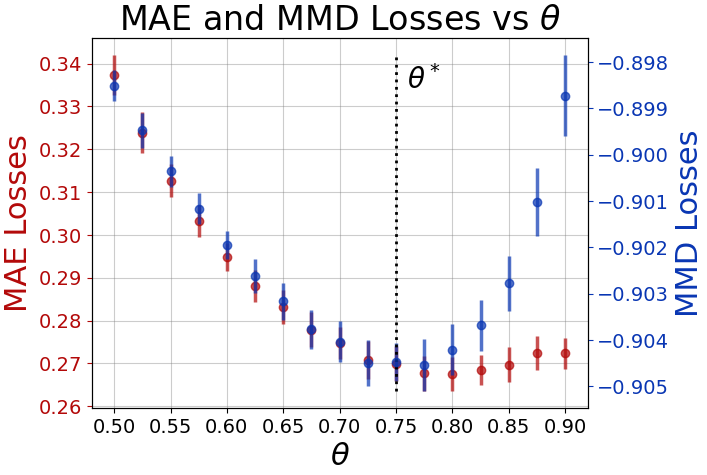
Within a prediction task, Graph Neural Networks (GNNs) use relational information as an inductive bias to enhance the model's accuracy. As task-relevant relations might be unknown, graph structure learning approaches have been proposed to learn them while solving the downstream prediction task. In this paper, we demonstrate that minimization of a point-prediction loss function, e.g., the mean absolute error, does not guarantee proper learning of the latent relational information and its associated uncertainty. Conversely, we prove that a suitable loss function on the stochastic model outputs simultaneously grants (i) the unknown adjacency matrix latent distribution and (ii) optimal performance on the prediction task. Finally, we propose a sampling-based method that solves this joint learning task. Empirical results validate our theoretical claims and demonstrate the effectiveness of the proposed approach.
Read more5/31/2024