Optimizing Sharpe Ratio: Risk-Adjusted Decision-Making in Multi-Armed Bandits

0

Sign in to get full access
Overview
- This paper introduces a novel approach to optimizing the Sharpe ratio, a widely used metric for risk-adjusted decision-making, in the context of multi-armed bandit problems.
- The authors propose a new algorithm, called Sharpe-UCB, that aims to maximize the Sharpe ratio by balancing the exploration of different arms with the exploitation of the most promising ones.
- The paper presents theoretical guarantees for the Sharpe-UCB algorithm and demonstrates its empirical performance on various benchmark datasets.
Plain English Explanation
The paper discusses a way to improve decision-making in situations where you have multiple options to choose from, each with uncertain outcomes. This type of problem is often referred to as a "multi-armed bandit" problem, as it is analogous to a gambler facing multiple slot machines (or "arms") with unknown payouts.
The key idea is to use a measure called the "Sharpe ratio" to guide the decision-making process. The Sharpe ratio is a way to evaluate the risk-adjusted performance of an investment or strategy - it looks at the expected return relative to the amount of risk taken. By optimizing the Sharpe ratio, the authors aim to make decisions that balance the potential for high rewards with the level of risk involved.
The authors propose a new algorithm, called Sharpe-UCB, that uses this Sharpe ratio concept to guide the exploration of different options in the multi-armed bandit problem. The algorithm tries to find the option that offers the best balance of high returns and low risk, rather than simply going for the option with the highest expected return.
The paper provides theoretical guarantees about the performance of the Sharpe-UCB algorithm, and also shows through experiments that it outperforms other standard approaches in various benchmark scenarios. This suggests that the Sharpe ratio optimization can be a useful tool for making decisions in situations with uncertain outcomes, where managing risk is just as important as pursuing high rewards.
Technical Explanation
The paper introduces the Sharpe-UCB algorithm, which is designed to optimize the Sharpe ratio in the context of stochastic multi-armed bandit problems. The Sharpe ratio is a widely used metric in finance and investment management that measures the risk-adjusted performance of an investment or strategy. By optimizing the Sharpe ratio, the algorithm aims to make decisions that balance the potential for high rewards with the level of risk involved.
The key technical challenge addressed in the paper is the exploration-exploitation trade-off inherent in multi-armed bandit problems. The Sharpe-UCB algorithm uses a novel Upper Confidence Bound (UCB) approach that incorporates the Sharpe ratio, allowing it to balance the exploration of different arms with the exploitation of the most promising ones.
The authors provide theoretical guarantees for the Sharpe-UCB algorithm, proving that it achieves sub-linear regret bounds and is therefore asymptotically optimal. They also demonstrate the empirical performance of the algorithm on various benchmark datasets, showing that it outperforms other standard approaches, such as Thompson Sampling and UCBV, in terms of Sharpe ratio maximization.
The paper also discusses potential extensions and applications of the Sharpe-UCB algorithm, such as its use in fair bandit problems (BanditQ) and adversarial multi-armed bandit problems (AMAB).
Critical Analysis
The paper presents a compelling approach to optimizing the Sharpe ratio in multi-armed bandit problems, which is a significant contribution to the field. The theoretical guarantees and empirical results suggest that the Sharpe-UCB algorithm can be a valuable tool for decision-making in a wide range of applications.
However, the paper does not address some potential limitations or areas for further research. For example, the algorithm assumes that the rewards and their variances are stationary over time, which may not always be the case in real-world scenarios. It would be interesting to see how the Sharpe-UCB algorithm could be extended to handle non-stationary environments, such as combinatorial multi-armed bandits with covariate shifts.
Additionally, the paper focuses on maximizing the Sharpe ratio, but there may be other risk-adjusted performance metrics that could be more appropriate in certain domains. It would be valuable to explore the performance of the Sharpe-UCB algorithm in comparison to other risk-aware bandit algorithms, such as those that optimize for conditional Value-at-Risk or conditional Drawdown.
Overall, the paper presents a well-designed and promising approach to risk-aware decision-making in multi-armed bandit problems. However, further research and real-world applications would be needed to fully understand the strengths, limitations, and potential impact of the Sharpe-UCB algorithm.
Conclusion
This paper introduces a novel algorithm, called Sharpe-UCB, that aims to optimize the Sharpe ratio in the context of stochastic multi-armed bandit problems. By incorporating the Sharpe ratio into the decision-making process, the algorithm is able to balance the exploration of different options with the exploitation of the most promising ones, effectively managing the trade-off between risk and reward.
The theoretical and empirical results presented in the paper suggest that the Sharpe-UCB algorithm can outperform other standard approaches in terms of Sharpe ratio maximization. This indicates that the optimization of risk-adjusted performance metrics, such as the Sharpe ratio, can be a valuable tool for decision-making in a wide range of applications where uncertain outcomes and risk management are key considerations.
While the paper does not address all potential limitations and areas for further research, it represents a significant contribution to the field of multi-armed bandit algorithms and opens up new avenues for exploring risk-aware decision-making in various domains, from finance and investment to resource allocation and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Sharpe Ratio: Risk-Adjusted Decision-Making in Multi-Armed Bandits
Sabrina Khurshid, Mohammed Shahid Abdulla, Gourab Ghatak
Sharpe Ratio (SR) is a critical parameter in characterizing financial time series as it jointly considers the reward and the volatility of any stock/portfolio through its variance. Deriving online algorithms for optimizing the SR is particularly challenging since even offline policies experience constant regret with respect to the best expert Even-Dar et al (2006). Thus, instead of optimizing the usual definition of SR, we optimize regularized square SR (RSSR). We consider two settings for the RSSR, Regret Minimization (RM) and Best Arm Identification (BAI). In this regard, we propose a novel multi-armed bandit (MAB) algorithm for RM called UCB-RSSR for RSSR maximization. We derive a path-dependent concentration bound for the estimate of the RSSR. Based on that, we derive the regret guarantees of UCB-RSSR and show that it evolves as O(log n) for the two-armed bandit case played for a horizon n. We also consider a fixed budget setting for well-known BAI algorithms, i.e., sequential halving and successive rejects, and propose SHVV, SHSR, and SuRSR algorithms. We derive the upper bound for the error probability of all proposed BAI algorithms. We demonstrate that UCB-RSSR outperforms the only other known SR optimizing bandit algorithm, U-UCB Cassel et al (2023). We also establish its efficacy with respect to other benchmarks derived from the GRA-UCB and MVTS algorithms. We further demonstrate the performance of proposed BAI algorithms for multiple different setups. Our research highlights that our proposed algorithms will find extensive applications in risk-aware portfolio management problems. Consequently, our research highlights that our proposed algorithms will find extensive applications in risk-aware portfolio management problems.
Read more6/12/2024
🛸
0
Best Arm Identification for Stochastic Rising Bandits
Marco Mussi, Alessandro Montenegro, Francesco Trov'o, Marcello Restelli, Alberto Maria Metelli
Stochastic Rising Bandits (SRBs) model sequential decision-making problems in which the expected reward of the available options increases every time they are selected. This setting captures a wide range of scenarios in which the available options are learning entities whose performance improves (in expectation) over time (e.g., online best model selection). While previous works addressed the regret minimization problem, this paper focuses on the fixed-budget Best Arm Identification (BAI) problem for SRBs. In this scenario, given a fixed budget of rounds, we are asked to provide a recommendation about the best option at the end of the identification process. We propose two algorithms to tackle the above-mentioned setting, namely R-UCBE, which resorts to a UCB-like approach, and R-SR, which employs a successive reject procedure. Then, we prove that, with a sufficiently large budget, they provide guarantees on the probability of properly identifying the optimal option at the end of the learning process and on the simple regret. Furthermore, we derive a lower bound on the error probability, matched by our R-SR (up to constants), and illustrate how the need for a sufficiently large budget is unavoidable in the SRB setting. Finally, we numerically validate the proposed algorithms in both synthetic and realistic environments.
Read more5/29/2024
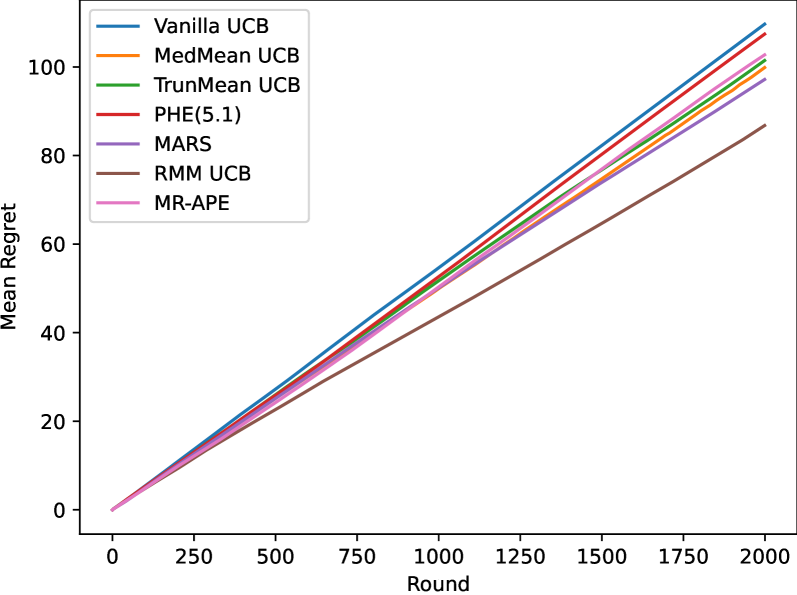
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024
📊
0
New!The Extended UCB Policies for Frequentist Multi-armed Bandit Problems
Keqin Liu, Tianshuo Zheng, Haoran Chen
The multi-armed bandit (MAB) problem is a widely studied model in the field of operations research for sequential decision making and reinforcement learning. This paper mainly considers the classical MAB model with the heavy-tailed reward distributions. We introduce the extended robust UCB policy, which is an extension of the pioneering UCB policies proposed by Bubeck et al. [5] and Lattimore [21]. The previous UCB policies require the knowledge of an upper bound on specific moments of reward distributions or a particular moment to exist, which can be hard to acquire or guarantee in practical scenarios. Our extended robust UCB generalizes Lattimore's seminary work (for moments of orders $p=4$ and $q=2$) to arbitrarily chosen $p$ and $q$ as long as the two moments have a known controlled relationship, while still achieving the optimal regret growth order O(log T), thus providing a broadened application area of the UCB policies for the heavy-tailed reward distributions.
Read more10/2/2024