Output Perturbation for Differentially Private Convex Optimization: Faster and More General

0
🤔
Sign in to get full access
Overview
- Developing efficient and implementable differentially private (DP) algorithms with strong excess risk bounds is an important problem in modern machine learning.
- Most prior work has focused on private empirical risk minimization (ERM) or private stochastic convex optimization (SCO), which optimize for average performance.
- However, there are often other objectives like fairness, adversarial robustness, or sensitivity to outliers that are not captured by ERM/SCO.
- Proving tight excess risk and runtime bounds for the stronger $(varepsilon, 0)$-DP guarantee remains a challenge.
Plain English Explanation
The key goal of this research is to find efficient and easy-to-implement differentially private (DP) algorithms that can provide strong guarantees on the excess risk, or the difference between the optimal and achieved performance. This is an important problem in modern machine learning.
Most previous work has focused on optimizing for average performance, using techniques like private empirical risk minimization (ERM) or private stochastic convex optimization (SCO). However, there are often other important objectives beyond just average performance, such as fairness, adversarial robustness, or sensitivity to outliers, that are not captured by the standard ERM/SCO setups.
Additionally, most recent work in private SCO has focused on the $(varepsilon, delta)$-DP guarantee, where $delta > 0$. Proving tight excess risk and runtime bounds for the stronger $(varepsilon, 0)$-DP guarantee, where $delta = 0$, remains a challenging open problem.
Technical Explanation
The key contributions of this research are:
-
$(varepsilon, 0)$-DP Guarantees for Smooth and Strongly Convex SCO: The authors provide the tightest known $(varepsilon, 0)$-DP excess risk bounds and fastest runtimes for smooth and strongly convex loss functions in the SCO setting. Their linear-time algorithm achieves optimal excess risk under these assumptions.
-
DP Optimization for Tilted Loss Functions: The authors study DP optimization for a broad class of tilted loss functions, which can be used to promote fairness or robustness and are not necessarily of the standard ERM form. They establish the first known DP excess risk and runtime bounds for optimizing this class, and show these bounds are near-optimal under smoothness and strong convexity assumptions.
-
DP Adversarial Training: The authors specialize their theory to the setting of DP adversarial training. Their results are achieved using a simple yet practical differentially private algorithm: output perturbation. The authors show that the power of this method to achieve strong privacy, utility, and runtime guarantees has not been fully appreciated in prior works.
Critical Analysis
The authors have made important contributions in addressing the challenge of developing efficient and practical DP algorithms with strong excess risk guarantees. By considering objectives beyond just average performance, and by targeting the stronger $(varepsilon, 0)$-DP guarantee, this work expands the frontiers of what is possible in differentially private machine learning.
However, the paper does not address several potential limitations and areas for further research:
- The strong assumptions of smoothness and strong convexity may limit the applicability of the proposed algorithms in more general settings.
- The paper does not provide a thorough empirical evaluation of the proposed algorithms, which would be helpful to understand their practical performance.
- The authors do not discuss the potential trade-offs between the different objectives (e.g., fairness vs. adversarial robustness) and how to navigate these trade-offs in a DP setting.
Addressing these limitations and further exploring the connections between DP, fairness, robustness, and other machine learning objectives would be valuable directions for future research in this area.
Conclusion
This research makes significant progress in developing efficient and easily implementable differentially private algorithms that can provide strong excess risk guarantees. By considering a broader class of objectives beyond just average performance, and by targeting the stronger $(varepsilon, 0)$-DP guarantee, the authors have expanded the frontiers of what is possible in differentially private machine learning.
While the paper has some limitations, such as its strong assumptions and lack of empirical evaluation, it represents an important step forward in this important and rapidly evolving field. The insights and techniques developed in this work could have far-reaching implications for building privacy-preserving machine learning systems that are both effective and fair.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Output Perturbation for Differentially Private Convex Optimization: Faster and More General
Andrew Lowy, Meisam Razaviyayn
Finding efficient, easily implementable differentially private (DP) algorithms that offer strong excess risk bounds is an important problem in modern machine learning. To date, most work has focused on private empirical risk minimization (ERM) or private stochastic convex optimization (SCO), which corresponds to population loss minimization. However, there are often other objectives-such as fairness, adversarial robustness, or sensitivity to outliers-besides average performance that are not captured in the classical ERM/SCO setups. Further, most recent work in private SCO has focused on $(varepsilon, delta)$-DP ($delta > 0$), whereas proving tight excess risk and runtime bounds for $(varepsilon, 0)$-differential privacy remains a challenging open problem. Our first contribution is to provide the tightest known $(varepsilon, 0)$-differentially private expected population loss bounds and fastest runtimes for smooth and strongly convex loss functions. In particular, for SCO with well-conditioned smooth and strongly convex loss functions, we provide a linear-time algorithm with optimal excess risk. For our second contribution, we study DP optimization for a broad class of tilted loss functions-which can be used to promote fairness or robustness, and are not necessarily of ERM form. We establish the first known DP excess risk and runtime bounds for optimizing this class; under smoothness and strong convexity assumptions, our bounds are near optimal. For our third contribution, we specialize our theory to DP adversarial training. Our results are achieved using perhaps the simplest yet practical differentially private algorithm: output perturbation. Although this method is not novel conceptually, our novel implementation scheme and analysis show that the power of this method to achieve strong privacy, utility, and runtime guarantees has not been fully appreciated in prior works.
Read more9/23/2024
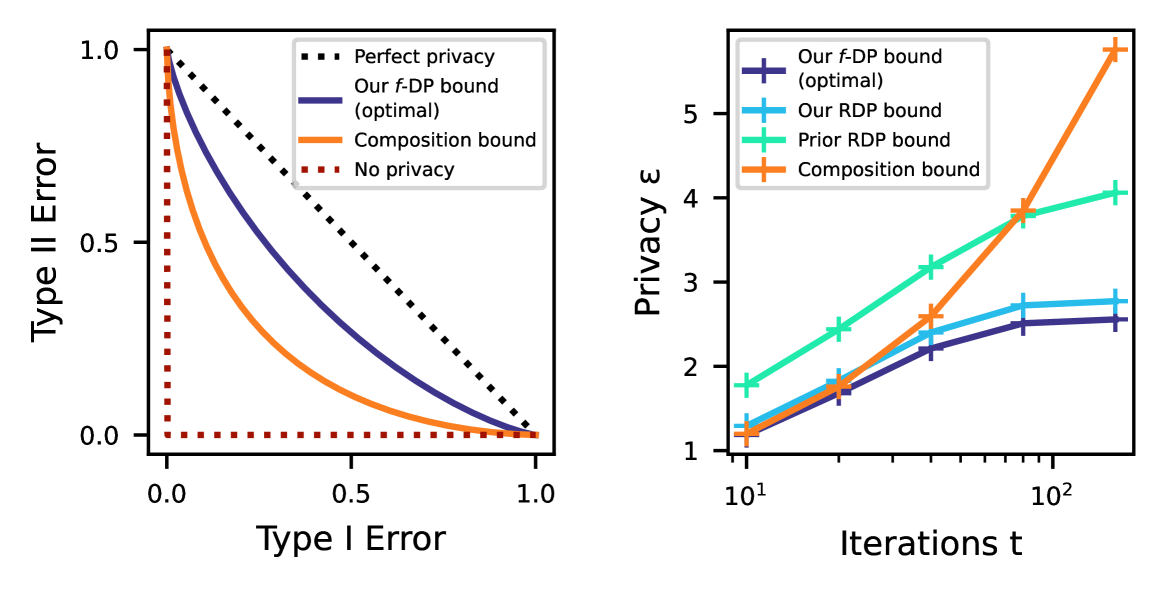
0
Shifted Interpolation for Differential Privacy
Jinho Bok, Weijie Su, Jason M. Altschuler
Noisy gradient descent and its variants are the predominant algorithms for differentially private machine learning. It is a fundamental question to quantify their privacy leakage, yet tight characterizations remain open even in the foundational setting of convex losses. This paper improves over previous analyses by establishing (and refining) the privacy amplification by iteration phenomenon in the unifying framework of $f$-differential privacy--which tightly captures all aspects of the privacy loss and immediately implies tighter privacy accounting in other notions of differential privacy, e.g., $(varepsilon,delta)$-DP and R'enyi DP. Our key technical insight is the construction of shifted interpolated processes that unravel the popular shifted-divergences argument, enabling generalizations beyond divergence-based relaxations of DP. Notably, this leads to the first exact privacy analysis in the foundational setting of strongly convex optimization. Our techniques extend to many settings: convex/strongly convex, constrained/unconstrained, full/cyclic/stochastic batches, and all combinations thereof. As an immediate corollary, we recover the $f$-DP characterization of the exponential mechanism for strongly convex optimization in Gopi et al. (2022), and moreover extend this result to more general settings.
Read more6/13/2024
🛠️
0
Differential Private Stochastic Optimization with Heavy-tailed Data: Towards Optimal Rates
Puning Zhao, Jiafei Wu, Zhe Liu, Chong Wang, Rongfei Fan, Qingming Li
We study convex optimization problems under differential privacy (DP). With heavy-tailed gradients, existing works achieve suboptimal rates. The main obstacle is that existing gradient estimators have suboptimal tail properties, resulting in a superfluous factor of $d$ in the union bound. In this paper, we explore algorithms achieving optimal rates of DP optimization with heavy-tailed gradients. Our first method is a simple clipping approach. Under bounded $p$-th order moments of gradients, with $n$ samples, it achieves $tilde{O}(sqrt{d/n}+sqrt{d}(sqrt{d}/nepsilon)^{1-1/p})$ population risk with $epsilonleq 1/sqrt{d}$. We then propose an iterative updating method, which is more complex but achieves this rate for all $epsilonleq 1$. The results significantly improve over existing methods. Such improvement relies on a careful treatment of the tail behavior of gradient estimators. Our results match the minimax lower bound in cite{kamath2022improved}, indicating that the theoretical limit of stochastic convex optimization under DP is achievable.
Read more8/20/2024
🛠️
0
Differentially Private Non-Convex Optimization under the KL Condition with Optimal Rates
Michael Menart, Enayat Ullah, Raman Arora, Raef Bassily, Crist'obal Guzm'an
We study private empirical risk minimization (ERM) problem for losses satisfying the $(gamma,kappa)$-Kurdyka-{L}ojasiewicz (KL) condition. The Polyak-{L}ojasiewicz (PL) condition is a special case of this condition when $kappa=2$. Specifically, we study this problem under the constraint of $rho$ zero-concentrated differential privacy (zCDP). When $kappain[1,2]$ and the loss function is Lipschitz and smooth over a sufficiently large region, we provide a new algorithm based on variance reduced gradient descent that achieves the rate $tilde{O}big(big(frac{sqrt{d}}{nsqrt{rho}}big)^kappabig)$ on the excess empirical risk, where $n$ is the dataset size and $d$ is the dimension. We further show that this rate is nearly optimal. When $kappa geq 2$ and the loss is instead Lipschitz and weakly convex, we show it is possible to achieve the rate $tilde{O}big(big(frac{sqrt{d}}{nsqrt{rho}}big)^kappabig)$ with a private implementation of the proximal point method. When the KL parameters are unknown, we provide a novel modification and analysis of the noisy gradient descent algorithm and show that this algorithm achieves a rate of $tilde{O}big(big(frac{sqrt{d}}{nsqrt{rho}}big)^{frac{2kappa}{4-kappa}}big)$ adaptively, which is nearly optimal when $kappa = 2$. We further show that, without assuming the KL condition, the same gradient descent algorithm can achieve fast convergence to a stationary point when the gradient stays sufficiently large during the run of the algorithm. Specifically, we show that this algorithm can approximate stationary points of Lipschitz, smooth (and possibly nonconvex) objectives with rate as fast as $tilde{O}big(frac{sqrt{d}}{nsqrt{rho}}big)$ and never worse than $tilde{O}big(big(frac{sqrt{d}}{nsqrt{rho}}big)^{1/2}big)$. The latter rate matches the best known rate for methods that do not rely on variance reduction.
Read more4/4/2024