Overconfidence is Key: Verbalized Uncertainty Evaluation in Large Language and Vision-Language Models
2405.02917
0
0

Abstract
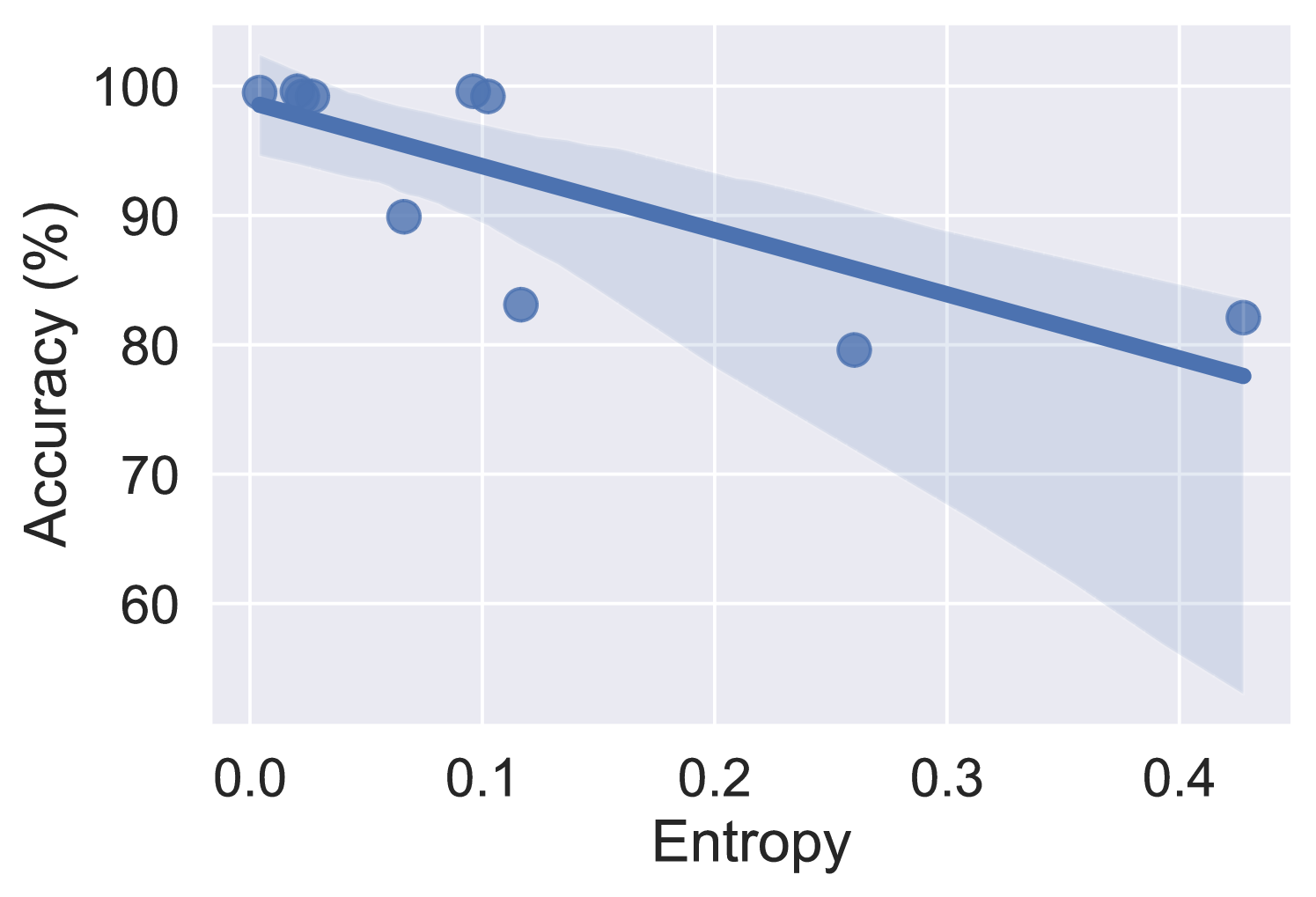
Language and Vision-Language Models (LLMs/VLMs) have revolutionized the field of AI by their ability to generate human-like text and understand images, but ensuring their reliability is crucial. This paper aims to evaluate the ability of LLMs (GPT4, GPT-3.5, LLaMA2, and PaLM 2) and VLMs (GPT4V and Gemini Pro Vision) to estimate their verbalized uncertainty via prompting. We propose the new Japanese Uncertain Scenes (JUS) dataset, aimed at testing VLM capabilities via difficult queries and object counting, and the Net Calibration Error (NCE) to measure direction of miscalibration. Results show that both LLMs and VLMs have a high calibration error and are overconfident most of the time, indicating a poor capability for uncertainty estimation. Additionally we develop prompts for regression tasks, and we show that VLMs have poor calibration when producing mean/standard deviation and 95% confidence intervals.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the role of overconfidence in large language models (LLMs) and vision-language models (VLMs) when evaluating their uncertainty.
- The researchers investigate how these models can be made more reliable and trustworthy by addressing issues related to uncertainty quantification.
- The paper presents several experiments and insights that provide a deeper understanding of model uncertainty and its implications for real-world applications.
Plain English Explanation
Large language models (LLMs) and vision-language models (VLMs) are powerful AI systems that can generate human-like text and understand images. However, these models can sometimes be overconfident in their predictions, even when they are uncertain or incorrect. This can be a problem when these models are used in high-stakes applications, such as medical diagnosis or financial decision-making.
The researchers in this paper wanted to understand why LLMs and VLMs can be overconfident, and how this issue can be addressed. They conducted several experiments to evaluate the models' ability to accurately quantify their own uncertainty. The results showed that while the models were generally good at recognizing when they were uncertain, they tended to express that uncertainty in a way that was not always reliable or trustworthy.
To address this, the researchers explored different ways to improve the models' uncertainty quantification, such as using specialized training techniques or modifying the model architecture. By making the models more aware of their own limitations and uncertainties, the researchers believe that they can be made more reliable and trustworthy for real-world applications.
Technical Explanation
The paper begins by reviewing the existing research on uncertainty quantification in large language models (LLMs) and vision-language models (VLMs). The authors note that while these models have become increasingly capable, they often struggle to accurately express their own uncertainty, leading to overconfident predictions that can be problematic in high-stakes applications.
To investigate this issue, the researchers conducted a series of experiments using several popular LLM and VLM architectures, including GPT-3, DALL-E, and CLIP. They evaluated the models' ability to verbalize their uncertainty through various tasks and benchmarks, such as generating uncertainty-aware responses and quantifying their confidence levels.
The results of these experiments revealed that the models tended to express excessive confidence, even when they were uncertain or incorrect. The authors attribute this to the models' training process, which often emphasizes accuracy over uncertainty quantification.
To address this problem, the researchers explored several techniques for improving the models' uncertainty awareness, including specialized training approaches and architectural modifications. They found that by explicitly training the models to recognize and communicate their uncertainties, they could create more reliable and trustworthy systems.
Critical Analysis
The researchers' work highlights an important and often overlooked issue in the development of large language and vision-language models. While these models have achieved impressive performance on a wide range of tasks, their overconfidence can pose significant risks when they are deployed in real-world applications.
One potential limitation of the study is that it focuses primarily on evaluating the models' verbalized uncertainty, which may not fully capture the nuances of their internal uncertainty representations. It would be valuable to explore other methods for assessing model uncertainty, such as using calibrated probability estimates or uncertainty-aware decision-making.
Additionally, the researchers acknowledge that their proposed solutions, while promising, may not be a complete fix for the problem of model overconfidence. Further research is needed to develop more robust and generalizable approaches to uncertainty quantification in LLMs and VLMs.
Despite these caveats, the work presented in this paper represents an important step towards creating more reliable and trustworthy AI systems. By addressing the issue of overconfidence, the researchers have highlighted the critical need for continued innovation and responsible development in the field of large-scale machine learning.
Conclusion
This paper offers valuable insights into the challenge of overconfidence in large language and vision-language models. The researchers have demonstrated that while these models can be highly capable, their tendency to express excessive confidence in their predictions can be a significant limitation, particularly in high-stakes applications.
By exploring techniques for improving the models' uncertainty quantification, the researchers have laid the groundwork for the development of more reliable and trustworthy AI systems. This work has important implications for a wide range of real-world applications, from medical diagnosis to financial decision-making, where the accurate communication of model uncertainty is crucial.
As the field of large-scale machine learning continues to evolve, the lessons learned from this research will be invaluable in guiding the responsible development and deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024
💬
I'm Not Sure, But...: Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, Jennifer Wortman Vaughan
0
0
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., I'm not sure, but...) decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., It's not clear, but...), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
5/16/2024

Benchmarking LLMs via Uncertainty Quantification
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F. Wong, Emine Yilmaz, Shuming Shi, Zhaopeng Tu
0
0
The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves eight LLMs (LLM series) spanning five representative natural language processing tasks. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs.
4/26/2024

Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
Atsuyuki Miyai, Jingkang Yang, Jingyang Zhang, Yifei Ming, Qing Yu, Go Irie, Yixuan Li, Hai Li, Ziwei Liu, Kiyoharu Aizawa
0
0
This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD). To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
4/1/2024