Benchmarking LLMs via Uncertainty Quantification
2401.12794
0
0

Abstract
The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves eight LLMs (LLM series) spanning five representative natural language processing tasks. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs.
Create account to get full access
Overview
- Introduces a new approach to benchmarking large language models (LLMs) using uncertainty quantification
- Proposes several metrics and evaluation methods to assess the uncertainty of LLM predictions
- Demonstrates the importance of accounting for uncertainty in LLM benchmarking and deployment
Plain English Explanation
This research paper presents a novel way to evaluate the performance of large language models (LLMs) like GPT-3 and BERT. Rather than just looking at how accurate the models are at predicting certain tasks, the researchers suggest we should also consider how
Uncertainty quantification is the process of measuring how confident or uncertain a model is in its output. The researchers argue that this is an important aspect of LLM performance that is often overlooked. A model that is highly accurate but very uncertain about its predictions may not be as useful as a slightly less accurate model that is more confident in its outputs.
The paper introduces several new metrics and evaluation techniques to quantify the uncertainty of LLM predictions. For example, they propose measuring the calibration of a model - how well its confidence scores match the true likelihood of its predictions being correct. They also look at the sharpness of a model's uncertainty, i.e., how concentrated or diffuse its uncertainty is.
By incorporating these uncertainty-focused measures, the researchers aim to provide a more holistic and meaningful way to benchmark and compare different LLMs. This could lead to the development of models that are not only highly capable, but also well-calibrated and able to clearly communicate their level of confidence in different situations.
Technical Explanation
The key technical contributions of this paper are:
-
Uncertainty Quantification Metrics: The researchers propose several new metrics to quantify different aspects of LLM uncertainty, including:
- Calibration: How well a model's confidence scores match the true likelihood of its predictions being correct.
- Sharpness: How concentrated or diffuse a model's uncertainty is.
- Miscoverage: The proportion of instances where the true label falls outside the model's predicted uncertainty interval.
-
Uncertainty-Aware Evaluation: The paper introduces new evaluation protocols that incorporate uncertainty quantification, such as:
- Uncertainty-Aware Accuracy: Accuracy where only high-confidence predictions are counted.
- Uncertainty-Aware F1: F1 score that penalizes overconfident and underconfident predictions.
-
Empirical Evaluation: The researchers apply their uncertainty-focused metrics and evaluation methods to several popular LLMs, including GPT-3, BERT, and RoBERTa. They find that these models exhibit significant miscalibration and other uncertainty-related issues, highlighting the importance of this perspective in LLM benchmarking.
The key insight is that uncertainty quantification provides a richer and more informative view of LLM performance than just accuracy-based metrics. By understanding a model's confidence and uncertainty levels, we can better assess its suitability for real-world applications where the ability to express uncertainty is crucial.
Critical Analysis
The paper makes a strong case for the importance of uncertainty quantification in LLM benchmarking. The proposed metrics and evaluation methods are well-grounded in statistical theory and provide a more nuanced way to assess model performance.
However, one limitation is that the empirical evaluation is conducted on a relatively narrow set of tasks and datasets. While the researchers demonstrate the value of their approach, further testing on a broader range of applications would be needed to fully validate its generalizability.
Additionally, the paper does not delve into the potential reasons for the observed miscalibration and uncertainty issues in the tested LLMs. Understanding the underlying causes could inform the design of more reliable and transparent models in the future.
Another area for further research is the development of techniques to
Conclusion
This research paper makes a compelling case for the need to incorporate uncertainty quantification into the benchmarking and evaluation of large language models. By moving beyond accuracy-only metrics, the proposed approach provides a more holistic and informative way to assess LLM performance and suitability for real-world applications.
The insights and methods presented in this work can help drive the development of more reliable and transparent language AI systems, where the model's confidence and uncertainty are clearly communicated to end-users. This is a crucial step towards building AI systems that can be safely and effectively deployed in high-stakes domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Akim Tsvigun, Daniil Vasilev, Rui Xing, Abdelrahman Boda Sadallah, Lyudmila Rvanova, Sergey Petrakov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, Artem Shelmanov
0
0
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
6/26/2024

UBENCH: Benchmarking Uncertainty in Large Language Models with Multiple Choice Questions
Xunzhi Wang, Zhuowei Zhang, Qiongyu Li, Gaonan Chen, Mengting Hu, Zhiyu li, Bitong Luo, Hang Gao, Zhixin Han, Haotian Wang
0
0
The rapid development of large language models (LLMs) has shown promising practical results. However, their low interpretability often leads to errors in unforeseen circumstances, limiting their utility. Many works have focused on creating comprehensive evaluation systems, but previous benchmarks have primarily assessed problem-solving abilities while neglecting the response's uncertainty, which may result in unreliability. Recent methods for measuring LLM reliability are resource-intensive and unable to test black-box models. To address this, we propose UBENCH, a comprehensive benchmark for evaluating LLM reliability. UBENCH includes 3,978 multiple-choice questions covering knowledge, language, understanding, and reasoning abilities. Experimental results show that UBENCH has achieved state-of-the-art performance, while its single-sampling method significantly saves computational resources compared to baseline methods that require multiple samplings. Additionally, based on UBENCH, we evaluate the reliability of 15 popular LLMs, finding GLM4 to be the most outstanding, closely followed by GPT-4. We also explore the impact of Chain-of-Thought prompts, role-playing prompts, option order, and temperature on LLM reliability, analyzing the varying effects on different LLMs.
6/19/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024
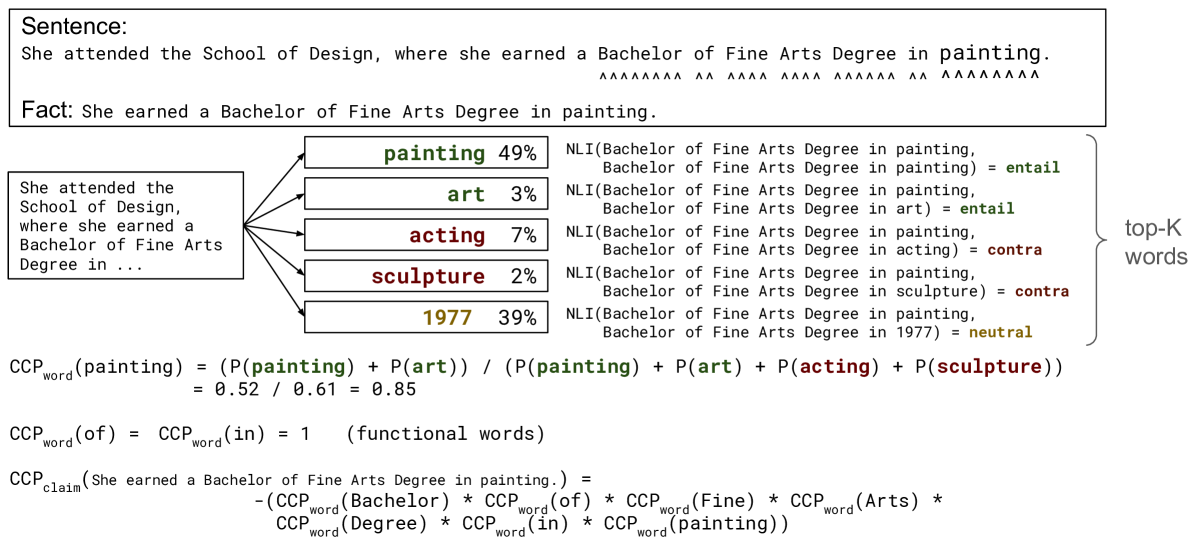
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov
0
0
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of a particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for seven LLMs and four languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
6/10/2024