Uncertainty Quantification for In-Context Learning of Large Language Models
2402.10189
0
0
💬
Abstract
In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: https://github.com/lingchen0331/UQ_ICL.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- In-context learning is a new ability of large language models (LLMs) that has transformed various fields
- LLMs can now learn a new task by seeing just a few relevant examples, rather than requiring extensive training
- However, there are concerns about the trustworthiness of LLM responses, such as the issue of "hallucination" where the model generates incorrect information
- Existing work has tried to quantify the uncertainty in LLM responses, but has often overlooked the unique challenges of in-context learning
Plain English Explanation
Large language models are artificial intelligence systems that are trained on massive amounts of text data. This allows them to understand and generate human-like language. A new breakthrough with these models is the ability to "learn in context." This means the model can adapt to a new task by looking at just a few relevant examples, rather than needing to be retrained from scratch.
This is a game-changing capability, as it allows language models to be much more flexible and applicable to a wide range of real-world scenarios. However, there are valid concerns about how reliable and trustworthy the model's responses are in these in-context learning situations. Sometimes the model can generate information that is incorrect or nonsensical, a phenomenon known as "hallucination."
Previous efforts have tried to quantify the uncertainty or unreliability in the model's outputs. But these approaches have often missed the unique challenges posed by in-context learning. The current research aims to provide a more comprehensive way to understand the different sources of uncertainty that can arise when a language model is adapting to a new task based on limited examples.
Technical Explanation
This paper proposes a novel framework for decomposing the predictive uncertainty of large language models when performing in-context learning. The key insight is that there are two main sources of uncertainty:
-
Aleatoric uncertainty - This stems from the inherent ambiguity or randomness in the provided demonstration examples used for in-context learning.
-
Epistemic uncertainty - This arises from fundamental limitations or unknowns in the language model's own parameters and configuration.
The paper develops a method to quantify both of these uncertainty components in an unsupervised way, without requiring any additional labeled data. This allows the model's in-context learning behavior to be better understood and diagnosed.
Extensive experiments are conducted to validate the proposed uncertainty decomposition approach. The results demonstrate its effectiveness at providing meaningful insights into the reliability and trustworthiness of LLM responses during in-context learning tasks.
Critical Analysis
The research provides an important step forward in addressing the trustworthiness issues surrounding in-context learning with large language models. By explicitly modelling the different sources of uncertainty, it offers a more nuanced view of when and why these models may produce unreliable outputs.
That said, the paper does not delve into some of the deeper philosophical questions around the nature of these uncertainties. For example, to what extent are the "aleatoric" uncertainties truly irreducible, versus a reflection of limitations in the training data or model architecture? And how generalizable are the findings to different types of language models and in-context learning setups?
Additionally, while the proposed estimation method is unsupervised, it still requires access to the internal workings of the language model, which may not always be available in real-world deployments. Further research is needed to understand how these uncertainties can be effectively communicated to end-users in a transparent and actionable way.
Overall, this work represents an important stride forward, but there remains much work to be done to build truly trustworthy and reliable in-context learning systems.
Conclusion
This research tackles a crucial challenge facing the widespread adoption of large language models - how to understand and quantify the uncertainties inherent in their responses, especially when performing in-context learning.
By proposing a framework to decompose aleatoric and epistemic uncertainties, the paper provides valuable insights into the complex factors influencing LLM reliability. This lays important groundwork for developing more robust and trustworthy in-context learning capabilities, with significant implications across many real-world applications.
While further research is needed, this work represents an important milestone in the journey towards AI systems that can flexibly adapt to new tasks while maintaining a clear understanding of their own limitations and uncertainties.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
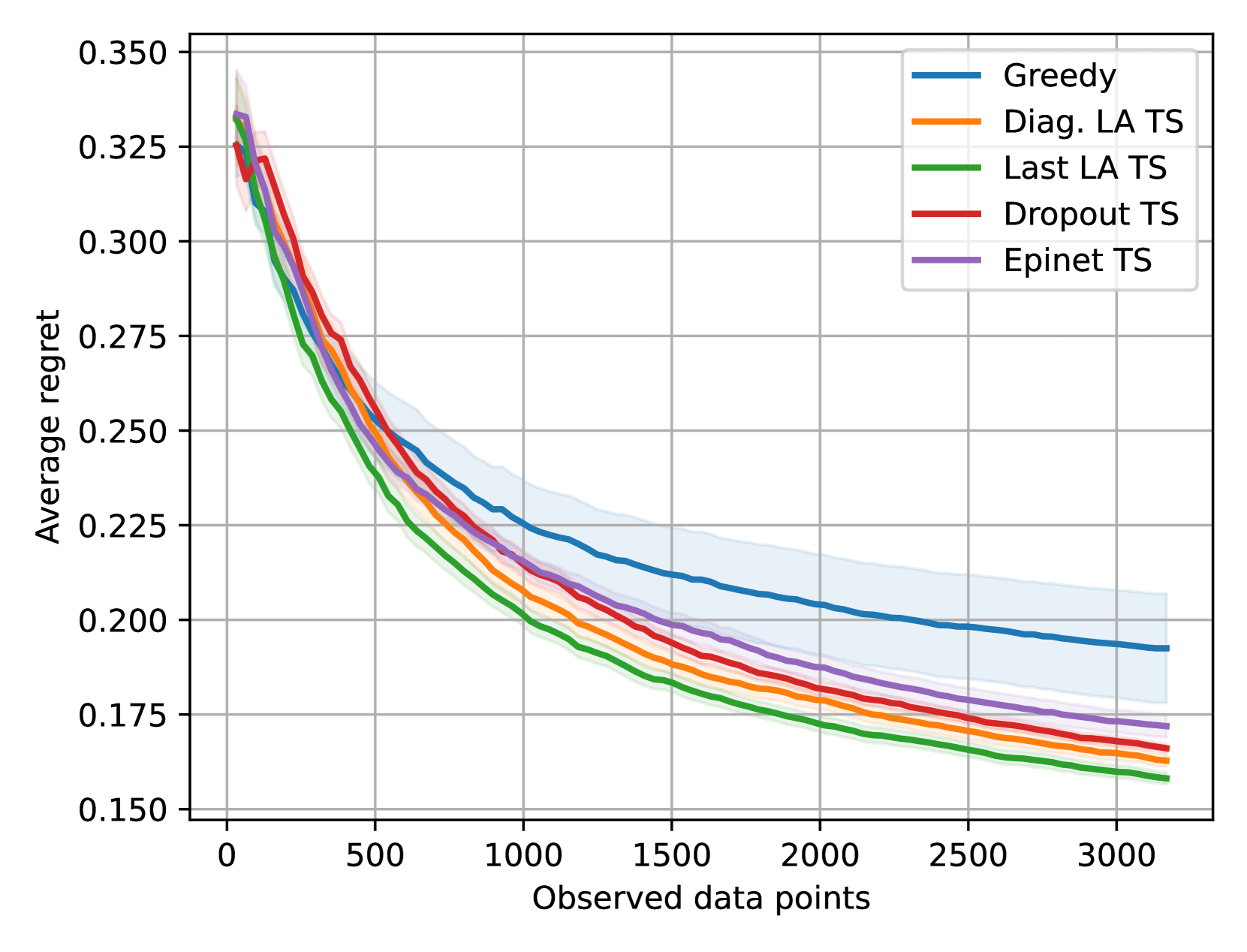
On the Importance of Uncertainty in Decision-Making with Large Language Models
Nicol`o Felicioni, Lucas Maystre, Sina Ghiassian, Kamil Ciosek
0
0
We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using Large Language Models as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
4/4/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
🔍
LUQ: Long-text Uncertainty Quantification for LLMs
Caiqi Zhang, Fangyu Liu, Marco Basaldella, Nigel Collier
0
0
Large Language Models (LLMs) have demonstrated remarkable capability in a variety of NLP tasks. Despite their effectiveness, these models are prone to generate nonfactual content. Uncertainty Quantification (UQ) is pivotal in enhancing our understanding of a model's confidence in its generated content, thereby aiding in the mitigation of nonfactual outputs. Existing research on UQ predominantly targets short text generation, typically yielding brief, word-limited responses. However, real-world applications frequently necessitate much longer responses. Our study first highlights the limitations of current UQ methods in handling long text generation. We then introduce textsc{Luq}, a novel sampling-based UQ approach specifically designed for long text. Our findings reveal that textsc{Luq} outperforms existing baseline methods in correlating with the model's factuality scores (negative coefficient of -0.85 observed for Gemini Pro). With textsc{Luq} as the tool for UQ, we investigate behavior patterns of several popular LLMs' response confidence spectrum and how that interplays with the response' factuality. We identify that LLMs lack confidence in generating long text for rare facts and a factually strong model (i.e. GPT-4) tends to reject questions it is not sure about. To further improve the factual accuracy of LLM responses, we propose a method called textsc{Luq-Ensemble} that ensembles responses from multiple models and selects the response with the least uncertainty. The ensembling method greatly improves the response factuality upon the best standalone LLM.
4/1/2024
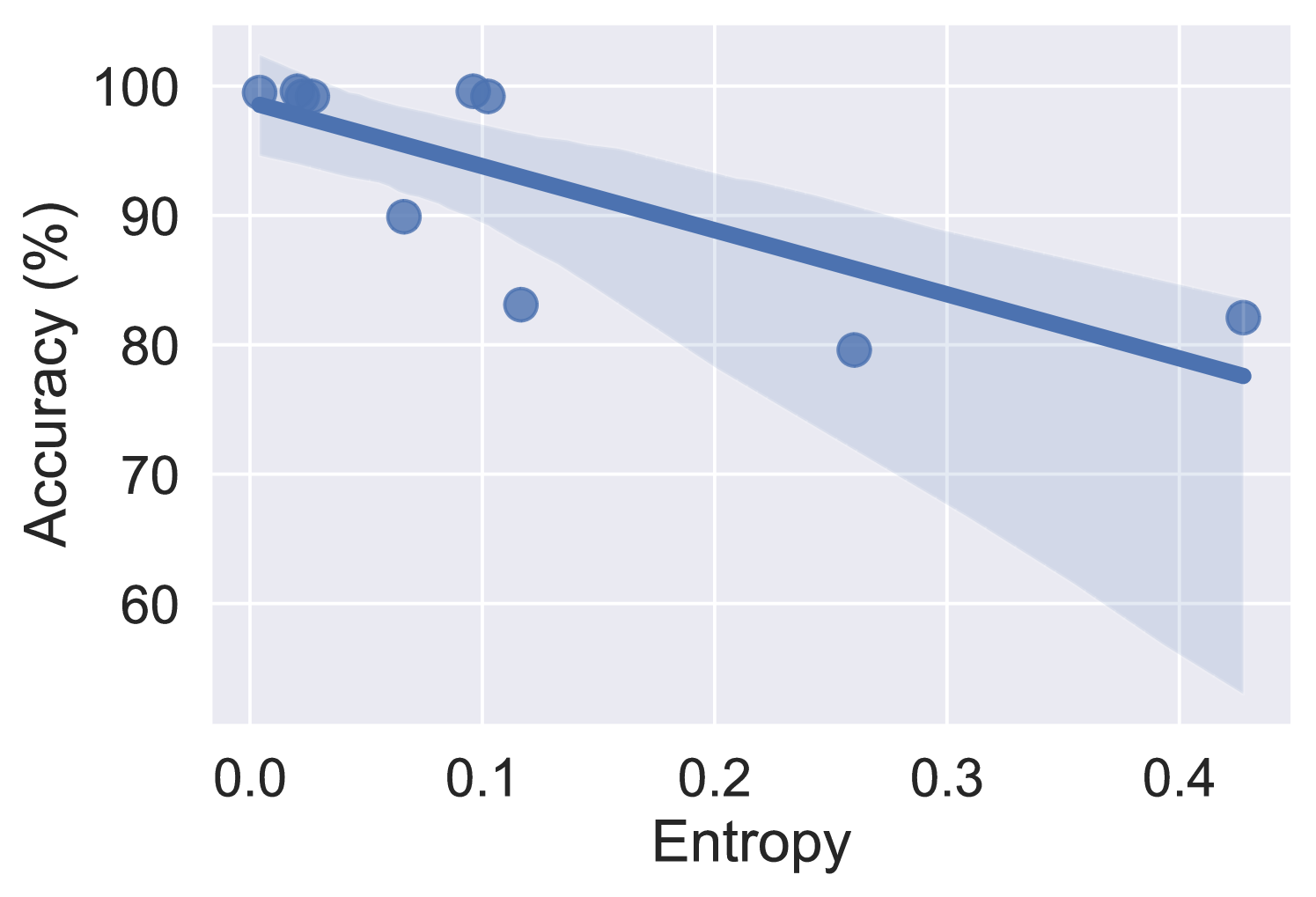
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024