GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
2403.03507
6
0

Abstract
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Create account to get full access
Overview
- This paper proposes a memory-efficient training method called GaLore (Gradient Low-Rank Projection) for large language models (LLMs).
- GaLore aims to reduce the memory footprint of LLM training by projecting the gradients onto a low-rank subspace, rather than updating the full model parameters.
- The method leverages the inherent low-rank structure of LLM gradients to achieve significant memory savings without sacrificing model performance.
Plain English Explanation
The training of large language models (LLMs) can be a memory-intensive process, as these models typically have billions of parameters. GaLore is a new technique that aims to reduce the amount of memory required for LLM training, making it more efficient and accessible.
The key idea behind GaLore is to focus on the gradients, the values that guide the model's learning, rather than updating the full set of parameters. The researchers observed that the gradients of LLMs often have a low-rank structure, meaning that they can be well-approximated by a smaller set of values. By projecting the gradients onto a low-rank subspace, GaLore can update the model with a fraction of the memory required for a full parameter update.
This memory-efficient approach is similar to other low-rank adaptation techniques, such as VELORA and LISA, which also leverage the low-rank nature of model updates. However, GaLore introduces a novel gradient projection method that is more effective and flexible than these previous approaches.
Technical Explanation
The core of the GaLore method is a gradient low-rank projection (GLP) technique, which decomposes the gradient into a low-rank component and a residual component. The low-rank component is then used to update the model parameters, while the residual component is discarded.
Specifically, the GLP technique first computes the full gradient of the loss function with respect to the model parameters. It then performs a low-rank decomposition of this gradient, using techniques such as singular value decomposition (SVD) or randomized low-rank approximation. The resulting low-rank component is used to update the model parameters, while the residual component is discarded.
By only updating the model with the low-rank component of the gradient, GaLore achieves significant memory savings compared to standard gradient-based optimization methods. The researchers demonstrate that this approach can reduce the memory footprint of LLM training by up to 90% without compromising model performance on a range of benchmarks.
The GaLore method is further extended to handle outliers in the gradient, which can degrade the low-rank approximation. The researchers propose an Outlier-Weighed Layerwise Sampled Low-Rank (OWLORE) variant that dynamically adjusts the low-rank projection based on the gradient outliers, leading to even greater memory savings.
Critical Analysis
The GaLore and OWLORE techniques presented in this paper offer a promising approach to reducing the memory requirements of LLM training. The researchers provide a strong theoretical and empirical justification for the low-rank structure of LLM gradients, and demonstrate the effectiveness of their methods across a range of tasks and model sizes.
However, some potential limitations and areas for further research are worth considering:
-
Generalization to Larger Models: While the experiments in the paper cover a wide range of model sizes, it would be important to evaluate the scalability of GaLore and OWLORE to the largest state-of-the-art LLMs, which continue to grow in size and complexity.
-
Finetuning and Transfer Learning: The paper primarily focuses on training LLMs from scratch. It would be valuable to explore the performance of GaLore and OWLORE in the context of finetuning and transfer learning, which are critical for many practical applications.
-
Interaction with Other Memory-Efficient Techniques: The GaLore and OWLORE methods could potentially be combined with other memory-efficient techniques, such as LORA or MORA, to further reduce the memory footprint of LLM training. Exploring these synergies could lead to even more efficient solutions.
Overall, the GaLore and OWLORE methods presented in this paper represent a significant contribution to the field of memory-efficient LLM training, and their impact could extend to a wide range of applications that require large, high-performance language models.
Conclusion
The GaLore and OWLORE techniques introduced in this paper offer a novel approach to reducing the memory footprint of training large language models (LLMs). By leveraging the inherent low-rank structure of LLM gradients, these methods can update the model parameters with a fraction of the memory required by standard gradient-based optimization.
The memory savings achieved by GaLore and OWLORE could have important implications for the accessibility and scalability of LLM training, enabling researchers and developers to explore larger and more complex models with limited computational resources. As the field of natural language processing continues to advance, memory-efficient techniques like those presented in this paper will likely play an increasingly important role in pushing the boundaries of what is possible with LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
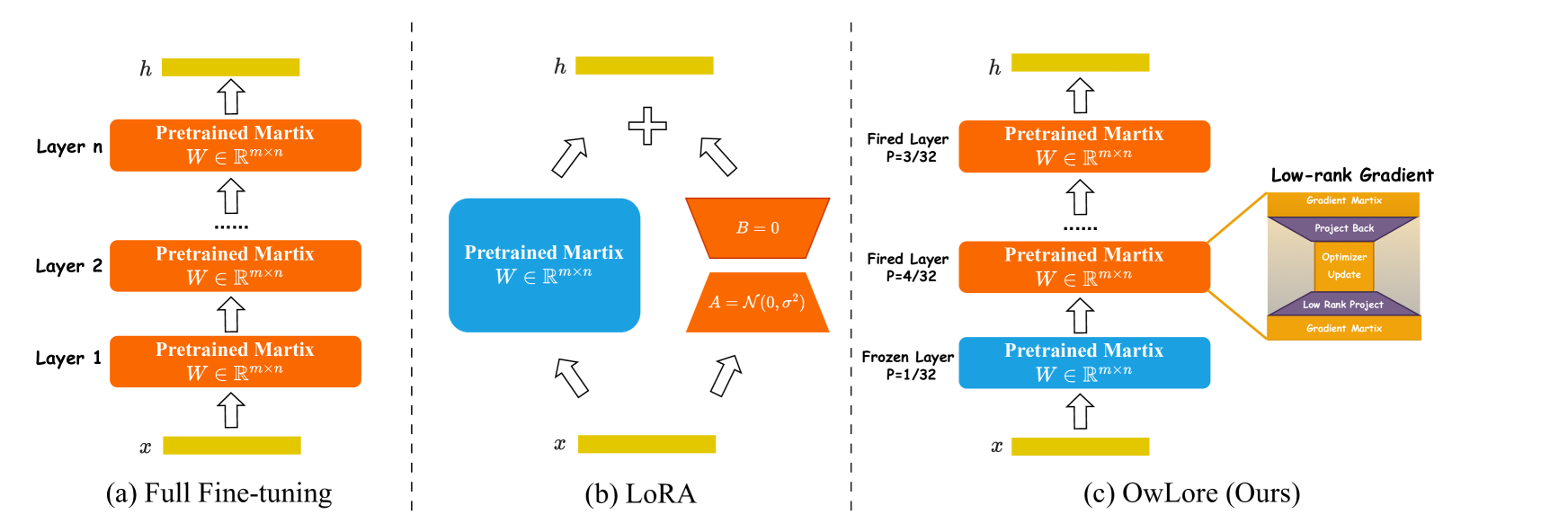
OwLore: Outlier-weighed Layerwise Sampled Low-Rank Projection for Memory-Efficient LLM Fine-tuning
Pengxiang Li, Lu Yin, Xiaowei Gao, Shiwei Liu
0
0
The rapid advancements in Large Language Models (LLMs) have revolutionized various natural language processing tasks. However, the substantial size of LLMs presents significant challenges in training or fine-tuning. While parameter-efficient approaches such as low-rank adaptation (LoRA) have gained popularity, they often compromise performance compared to full-rank fine-tuning. In this paper, we propose Outlier-weighed Layerwise Sampled Low-Rank Projection (OwLore), a new memory-efficient fine-tuning approach, inspired by the layerwise outlier distribution of LLMs, which dynamically samples pre-trained layers to fine-tune instead of adding additional adaptors. We first interpret the outlier phenomenon through the lens of Heavy-Tailed Self-Regularization theory (HT-SR), discovering that layers with more outliers tend to be more heavy-tailed and consequently better trained. Inspired by this finding, OwLore strategically assigns higher sampling probabilities to layers with more outliers to better leverage the knowledge stored in pre-trained LLMs. To further mitigate the memory demands of fine-tuning, we integrate gradient low-rank projection into our approach, which facilitates each layer to be efficiently trained in a low-rank manner. By incorporating the efficient characteristics of low-rank and optimal layerwise sampling, OwLore significantly improves the memory-performance trade-off in LLM pruning. Our extensive experiments across various architectures, including LLaMa2, LLaMa3, and Mistral, demonstrate that OwLore consistently outperforms baseline approaches, including full fine-tuning. Specifically, it achieves up to a 1.1% average accuracy gain on the Commonsense Reasoning benchmark, a 3.0% improvement on MMLU, and a notable 10% boost on MT-Bench, while being more memory efficient. OwLore allows us to fine-tune LLaMa2-7B with only 21GB of memory.
5/29/2024
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
Roy Miles, Pradyumna Reddy, Ismail Elezi, Jiankang Deng
0
0
Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
5/29/2024

LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, Tong Zhang
0
0
The machine learning community has witnessed impressive advancements since large language models (LLMs) first appeared. Yet, their massive memory consumption has become a significant roadblock to large-scale training. For instance, a 7B model typically requires at least 60 GB of GPU memory with full parameter training, which presents challenges for researchers without access to high-resource environments. Parameter Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA) have been proposed to alleviate this problem. However, in most large-scale fine-tuning settings, their performance does not reach the level of full parameter training because they confine the parameter search to a low-rank subspace. Attempting to complement this deficiency, we investigate the layerwise properties of LoRA on fine-tuning tasks and observe an unexpected but consistent skewness of weight norms across different layers. Utilizing this key observation, a surprisingly simple training strategy is discovered, which outperforms both LoRA and full parameter training in a wide range of settings with memory costs as low as LoRA. We name it Layerwise Importance Sampled AdamW (LISA), a promising alternative for LoRA, which applies the idea of importance sampling to different layers in LLMs and randomly freezes most middle layers during optimization. Experimental results show that with similar or less GPU memory consumption, LISA surpasses LoRA or even full parameter tuning in downstream fine-tuning tasks, where LISA consistently outperforms LoRA by over 10%-35% in terms of MT-Bench score while achieving on-par or better performance in MMLU, AGIEval and WinoGrande. On large models, specifically LLaMA-2-70B, LISA surpasses LoRA on MT-Bench, GSM8K, and PubMedQA, demonstrating its effectiveness across different domains.
5/28/2024
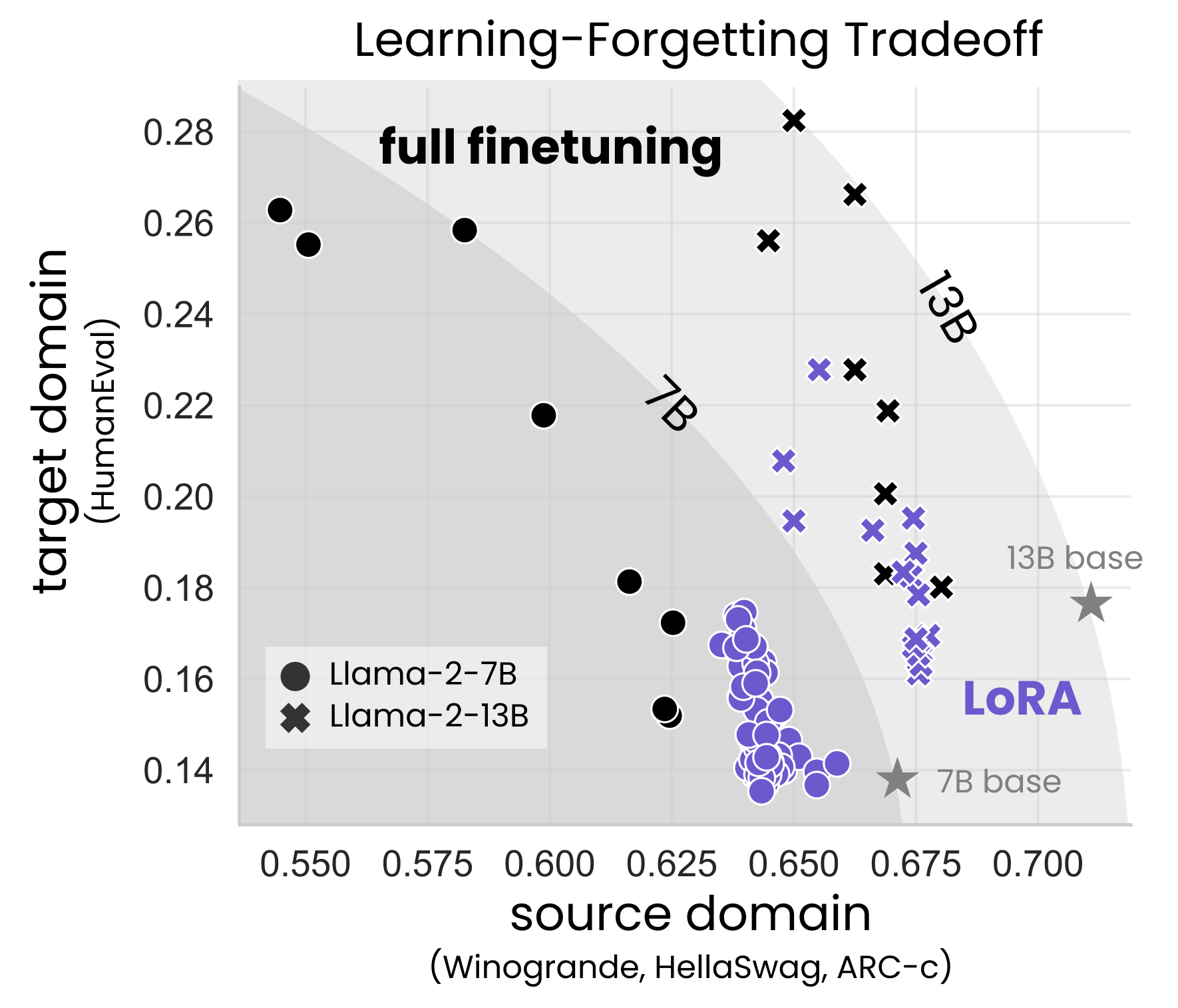
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
0
0
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024