Palantir: Towards Efficient Super Resolution for Ultra-high-definition Live Streaming

0

Sign in to get full access
Overview
- Proposes a novel super-resolution model called Palantír for efficient ultra-high-definition live streaming
- Aims to address the challenges of high computational cost and image quality degradation in existing super-resolution methods
- Introduces a hierarchical transformer-based architecture with a lightweight design for real-time performance
Plain English Explanation
Palantír is a new super-resolution model designed to improve the quality of video streams in ultra-high-definition (UHD) live broadcasting. Existing super-resolution methods can be computationally expensive and lead to a loss of image quality, which is a problem for real-time applications like live streaming.
The Palantír model uses a hierarchical transformer-based architecture with a lightweight design to overcome these challenges. This allows the model to efficiently reconstruct high-resolution images from low-resolution inputs, providing a way to super-resolve live video streams without significant performance or quality degradation.
The key idea is to use a hierarchical approach that progressively upscales the image, rather than trying to perform a single large transformation. This makes the model more computationally efficient and better able to preserve important details and nuances in the final high-resolution output.
Technical Explanation
Palantír's hierarchical transformer-based architecture consists of multiple stages, each of which performs a small, incremental super-resolution step. This approach is more efficient than traditional single-stage super-resolution models, which have to handle the full upscaling in a single, computationally intensive operation.
The model is designed with a lightweight backbone and attention-based modules to enable real-time performance. It leverages the ability of transformers to efficiently capture long-range dependencies in the image, which is crucial for high-quality super-resolution.
The authors evaluate Palantír on several standard benchmarks for super-resolution, demonstrating its ability to achieve state-of-the-art performance in terms of both image quality and inference speed. This makes Palantír a promising solution for efficient ultra-high-definition live streaming applications.
Critical Analysis
The paper provides a thorough evaluation of Palantír's performance and compares it to other super-resolution models. However, the authors do not address potential limitations or caveats of the approach, such as how it might perform on more challenging or diverse datasets, or how it would scale to even higher resolutions.
Additionally, while the model's lightweight design is a key strength, the authors could further explore the trade-offs between computational efficiency and image quality. It would be valuable to understand the extent to which the hierarchical architecture and attention-based modules contribute to the model's performance and efficiency.
Overall, the Palantír model presents a compelling approach to efficient super-resolution for live streaming applications. However, further research and analysis could provide a more well-rounded understanding of the method's capabilities and limitations.
Conclusion
The Palantír super-resolution model represents a promising step towards enabling efficient ultra-high-definition live streaming. By employing a hierarchical transformer-based architecture with a lightweight design, the model can deliver high-quality results while maintaining real-time performance.
This research highlights the potential of advanced deep learning techniques, such as transformers and hierarchical processing, to address the challenges of high-resolution video compression and transmission. As live streaming and other multimedia applications continue to demand ever-higher resolutions, solutions like Palantír could play a crucial role in ensuring a seamless and high-quality viewing experience for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Palantir: Towards Efficient Super Resolution for Ultra-high-definition Live Streaming
Xinqi Jin, Zhui Zhu, Xikai Sun, Fan Dang, Jiangchuan Liu, Jingao Xu, Kebin Liu, Xinlei Chen, Yunhao Liu
Neural enhancement through super-resolution (SR) deep neural networks (DNNs) opens up new possibilities for ultra-high-definition (UHD) live streaming over existing encoding and networking infrastructure. Yet, the heavy SR DNN inference overhead leads to severe deployment challenges. To reduce the overhead, existing systems propose to apply DNN-based SR only on carefully selected anchor frames while upscaling non-anchor frames via the lightweight reusing-based SR approach. However, frame-level scheduling is coarse-grained and fails to deliver optimal efficiency. In this work, we propose Palantir, the first neural-enhanced UHD live streaming system with fine-grained patch-level scheduling. Two novel techniques are incorporated into Palantir to select the most beneficial anchor patches and support latency-sensitive UHD live streaming applications. Firstly, under the guidance of our pioneering and theoretical analysis, Palantir constructs a directed acyclic graph (DAG) for lightweight yet accurate SR quality estimation under any possible anchor patch set. Secondly, to further optimize the scheduling latency, Palantir improves parallelizability by refactoring the computation subprocedure of the estimation process into a sparse matrix-matrix multiplication operation. The evaluation results suggest that Palantir incurs a negligible scheduling latency accounting for less than 5.7% of the end-to-end latency requirement. When compared to the naive method of applying DNN-based SR on all the frames, Palantir can reduce the SR DNN inference overhead by 20 times (or 60 times) while preserving 54.0-82.6% (or 32.8-64.0%) of the quality gain. When compared to the state-of-the-art real-time frame-level scheduling strategy, Palantir can reduce the SR DNN inference overhead by 80.1% at most (and 38.4% on average) without sacrificing the video quality.
Read more9/4/2024

0
HiT-SR: Hierarchical Transformer for Efficient Image Super-Resolution
Xiang Zhang, Yulun Zhang, Fisher Yu
Transformers have exhibited promising performance in computer vision tasks including image super-resolution (SR). However, popular transformer-based SR methods often employ window self-attention with quadratic computational complexity to window sizes, resulting in fixed small windows with limited receptive fields. In this paper, we present a general strategy to convert transformer-based SR networks to hierarchical transformers (HiT-SR), boosting SR performance with multi-scale features while maintaining an efficient design. Specifically, we first replace the commonly used fixed small windows with expanding hierarchical windows to aggregate features at different scales and establish long-range dependencies. Considering the intensive computation required for large windows, we further design a spatial-channel correlation method with linear complexity to window sizes, efficiently gathering spatial and channel information from hierarchical windows. Extensive experiments verify the effectiveness and efficiency of our HiT-SR, and our improved versions of SwinIR-Light, SwinIR-NG, and SRFormer-Light yield state-of-the-art SR results with fewer parameters, FLOPs, and faster speeds ($sim7times$).
Read more7/9/2024
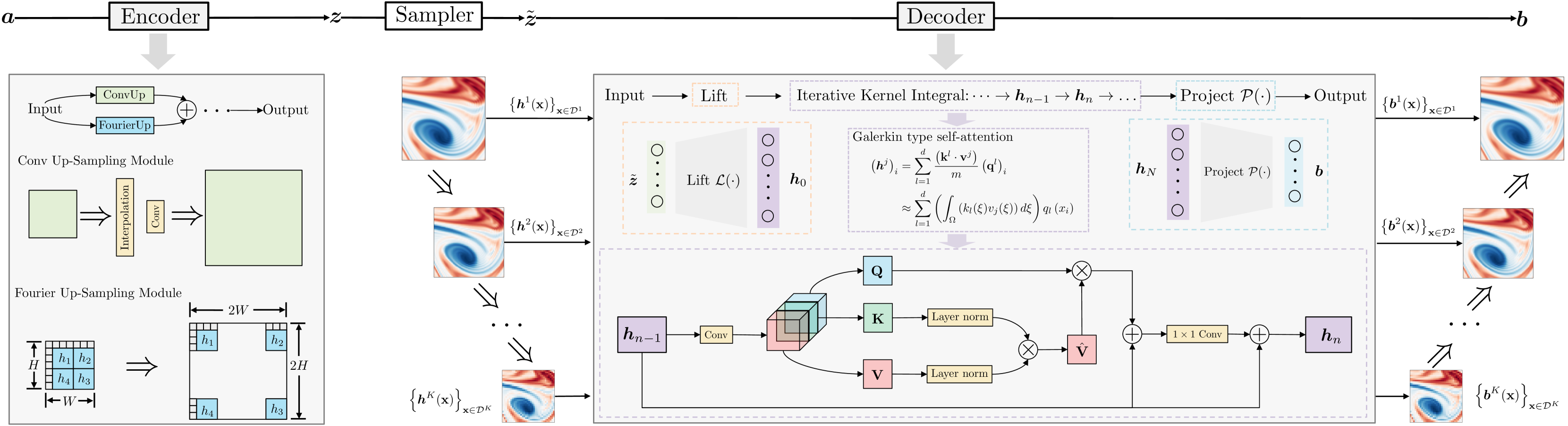
0
Hierarchical Neural Operator Transformer with Learnable Frequency-aware Loss Prior for Arbitrary-scale Super-resolution
Xihaier Luo, Xiaoning Qian, Byung-Jun Yoon
In this work, we present an arbitrary-scale super-resolution (SR) method to enhance the resolution of scientific data, which often involves complex challenges such as continuity, multi-scale physics, and the intricacies of high-frequency signals. Grounded in operator learning, the proposed method is resolution-invariant. The core of our model is a hierarchical neural operator that leverages a Galerkin-type self-attention mechanism, enabling efficient learning of mappings between function spaces. Sinc filters are used to facilitate the information transfer across different levels in the hierarchy, thereby ensuring representation equivalence in the proposed neural operator. Additionally, we introduce a learnable prior structure that is derived from the spectral resizing of the input data. This loss prior is model-agnostic and is designed to dynamically adjust the weighting of pixel contributions, thereby balancing gradients effectively across the model. We conduct extensive experiments on diverse datasets from different domains and demonstrate consistent improvements compared to strong baselines, which consist of various state-of-the-art SR methods.
Read more5/21/2024

0
Efficient HDR Reconstruction from Real-World Raw Images
Qirui Yang, Yihao Liu, Qihua Chen, Huanjing Yue, Kun Li, Jingyu Yang
The widespread usage of high-definition screens on edge devices stimulates a strong demand for efficient high dynamic range (HDR) algorithms. However, many existing HDR methods either deliver unsatisfactory results or consume too much computational and memory resources, hindering their application to high-resolution images (usually with more than 12 megapixels) in practice. In addition, existing HDR dataset collection methods often are labor-intensive. In this work, in a new aspect, we discover an excellent opportunity for HDR reconstructing directly from raw images and investigating novel neural network structures that benefit the deployment of mobile devices. Our key insights are threefold: (1) we develop a lightweight-efficient HDR model, RepUNet, using the structural re-parameterization technique to achieve fast and robust HDR; (2) we design a new computational raw HDR data formation pipeline and construct a real-world raw HDR dataset, RealRaw-HDR; (3) we propose a plug-and-play motion alignment loss to mitigate motion ghosting under limited bandwidth conditions. Our model contains less than 830K parameters and takes less than 3 ms to process an image of 4K resolution using one RTX 3090 GPU. While being highly efficient, our model also outperforms the state-of-the-art HDR methods in terms of PSNR, SSIM, and a color difference metric.
Read more6/6/2024