HiT-SR: Hierarchical Transformer for Efficient Image Super-Resolution

0

Sign in to get full access
Overview
- Introduces a new Hierarchical Transformer model called HiT-SR for efficient image super-resolution
- Leverages a hierarchical structure and multi-scale feature fusion to improve performance and reduce computational cost
- Explores frequency-inspired optimization techniques to further enhance the transformer's efficiency
Plain English Explanation
The paper presents a new deep learning model called HiT-SR (Hierarchical Transformer for Efficient Image Super-Resolution) that is designed to efficiently upscale low-resolution images to higher resolutions. Unlike traditional convolutional neural networks, HiT-SR uses a hierarchical neural operator transformer to capture both local and global image features.
The key idea is to break down the super-resolution task into a hierarchical process, where the model first extracts multi-scale features from the input image and then progressively refines them at higher resolutions. This hierarchical structure allows HiT-SR to efficiently process images of different sizes without significant increases in computational cost.
Additionally, the paper explores frequency-inspired optimization techniques to further enhance the transformer's efficiency, such as partial large kernel CNNs and frequency-aware optimization. These innovations help HiT-SR achieve state-of-the-art performance on various image super-resolution benchmarks while requiring fewer computational resources.
Technical Explanation
The HiT-SR model consists of a hierarchical transformer architecture that progressively refines the input image through multiple stages. At each stage, the transformer extracts and fuses features at different scales, allowing it to capture both local and global information.
The key components of the HiT-SR architecture include:
-
Hierarchical Structure: The model is divided into multiple stages, each of which processes the image at a different resolution. This hierarchical design enables efficient processing of images of varying sizes.
-
Multi-Scale Feature Fusion: At each stage, the transformer module aggregates features from different scales, combining low-level details with high-level semantic information to generate the final super-resolved output.
-
Frequency-Inspired Optimization: The authors explore techniques like partial large kernel CNNs and frequency-aware optimization to improve the transformer's efficiency and performance.
The extensive experiments conducted in the paper demonstrate that HiT-SR outperforms state-of-the-art image super-resolution models on various benchmark datasets, while also requiring fewer computational resources.
Critical Analysis
The paper provides a comprehensive evaluation of the HiT-SR model, addressing its strengths and potential limitations. However, some areas for further research and improvement are worth considering:
-
Generalization to Diverse Datasets: The authors primarily evaluate HiT-SR on standard image super-resolution datasets, such as DIV2K and Flickr2K. It would be interesting to see how the model performs on more diverse and challenging datasets, including real-world images with various noise and degradation levels.
-
Computational Complexity Analysis: While the paper highlights the efficiency of HiT-SR, a more in-depth analysis of the model's computational complexity and memory footprint would provide a better understanding of its practical implications, especially for deployment on resource-constrained devices.
-
Interpretability and Explainability: Given the complexity of the hierarchical transformer architecture, it would be valuable to explore techniques that can provide insights into the model's decision-making process and the role of different components in achieving the observed performance.
-
Potential Limitations and Biases: As with any machine learning model, it is essential to consider potential biases or limitations, such as the model's sensitivity to specific image characteristics or its performance on underrepresented image domains.
Conclusion
The HiT-SR model presented in this paper represents a significant advancement in the field of efficient image super-resolution. By leveraging a hierarchical transformer architecture and frequency-inspired optimization techniques, the authors have demonstrated the ability to achieve state-of-the-art performance while reducing computational cost.
The innovative design of HiT-SR, which combines the strengths of hierarchical feature extraction and multi-scale fusion, offers a promising approach for various applications that require high-quality image upscaling, such as medical imaging, surveillance, and multimedia processing. As the field of super-resolution continues to evolve, the insights and techniques explored in this paper can serve as a valuable reference for future research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HiT-SR: Hierarchical Transformer for Efficient Image Super-Resolution
Xiang Zhang, Yulun Zhang, Fisher Yu
Transformers have exhibited promising performance in computer vision tasks including image super-resolution (SR). However, popular transformer-based SR methods often employ window self-attention with quadratic computational complexity to window sizes, resulting in fixed small windows with limited receptive fields. In this paper, we present a general strategy to convert transformer-based SR networks to hierarchical transformers (HiT-SR), boosting SR performance with multi-scale features while maintaining an efficient design. Specifically, we first replace the commonly used fixed small windows with expanding hierarchical windows to aggregate features at different scales and establish long-range dependencies. Considering the intensive computation required for large windows, we further design a spatial-channel correlation method with linear complexity to window sizes, efficiently gathering spatial and channel information from hierarchical windows. Extensive experiments verify the effectiveness and efficiency of our HiT-SR, and our improved versions of SwinIR-Light, SwinIR-NG, and SRFormer-Light yield state-of-the-art SR results with fewer parameters, FLOPs, and faster speeds ($sim7times$).
Read more7/9/2024

0
HiTSR: A Hierarchical Transformer for Reference-based Super-Resolution
Masoomeh Aslahishahri, Jordan Ubbens, Ian Stavness
In this paper, we propose HiTSR, a hierarchical transformer model for reference-based image super-resolution, which enhances low-resolution input images by learning matching correspondences from high-resolution reference images. Diverging from existing multi-network, multi-stage approaches, we streamline the architecture and training pipeline by incorporating the double attention block from GAN literature. Processing two visual streams independently, we fuse self-attention and cross-attention blocks through a gating attention strategy. The model integrates a squeeze-and-excitation module to capture global context from the input images, facilitating long-range spatial interactions within window-based attention blocks. Long skip connections between shallow and deep layers further enhance information flow. Our model demonstrates superior performance across three datasets including SUN80, Urban100, and Manga109. Specifically, on the SUN80 dataset, our model achieves PSNR/SSIM values of 30.24/0.821. These results underscore the effectiveness of attention mechanisms in reference-based image super-resolution. The transformer-based model attains state-of-the-art results without the need for purpose-built subnetworks, knowledge distillation, or multi-stage training, emphasizing the potency of attention in meeting reference-based image super-resolution requirements.
Read more9/2/2024
🖼️
0
SRFormerV2: Taking a Closer Look at Permuted Self-Attention for Image Super-Resolution
Yupeng Zhou, Zhen Li, Chun-Le Guo, Li Liu, Ming-Ming Cheng, Qibin Hou
Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance. Still, the computation overhead is also considerable when the window size gradually increases. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. In addition, we also attempt to scale up the model by further enlarging the window size and channel numbers to explore the potential of Transformer-based models. Experiments show that our scaled model, named SRFormerV2, can further improve the results and achieves state-of-the-art. We hope our simple and effective approach could be useful for future research in super-resolution model design. The homepage is https://z-yupeng.github.io/SRFormer/.
Read more8/15/2024
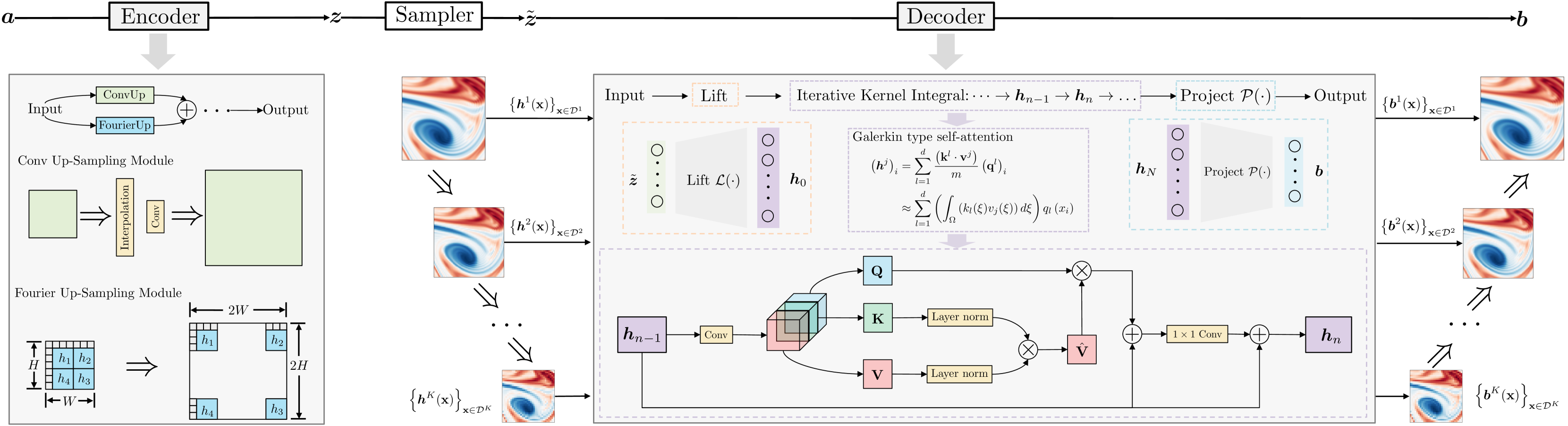
0
Hierarchical Neural Operator Transformer with Learnable Frequency-aware Loss Prior for Arbitrary-scale Super-resolution
Xihaier Luo, Xiaoning Qian, Byung-Jun Yoon
In this work, we present an arbitrary-scale super-resolution (SR) method to enhance the resolution of scientific data, which often involves complex challenges such as continuity, multi-scale physics, and the intricacies of high-frequency signals. Grounded in operator learning, the proposed method is resolution-invariant. The core of our model is a hierarchical neural operator that leverages a Galerkin-type self-attention mechanism, enabling efficient learning of mappings between function spaces. Sinc filters are used to facilitate the information transfer across different levels in the hierarchy, thereby ensuring representation equivalence in the proposed neural operator. Additionally, we introduce a learnable prior structure that is derived from the spectral resizing of the input data. This loss prior is model-agnostic and is designed to dynamically adjust the weighting of pixel contributions, thereby balancing gradients effectively across the model. We conduct extensive experiments on diverse datasets from different domains and demonstrate consistent improvements compared to strong baselines, which consist of various state-of-the-art SR methods.
Read more5/21/2024