PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter
2402.10896
0
0
💬
Abstract
This paper demonstrates that a progressively aligned language model can effectively bridge frozen vision encoders and large language models (LLMs). While the fundamental architecture and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters vary significantly across recent works. Our research undertakes a thorough exploration of the state-of-the-art perceiver resampler architecture and builds a strong baseline. However, we observe that the vision-language alignment with perceiver resampler exhibits slow convergence and limited scalability with a lack of direct supervision. To address this issue, we propose PaLM2-VAdapter, employing a progressively aligned language model as the vision-language adapter. Compared to the strong baseline with perceiver resampler, our method empirically shows faster convergence, higher performance, and stronger scalability. Extensive experiments across various Visual Question Answering (VQA) and captioning tasks on both images and videos demonstrate that our model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, our method achieves these advancements with 30~70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
Create account to get full access
Overview
- This paper explores a new approach to bridging the gap between frozen vision encoders and large language models (LLMs).
- The authors investigate the state-of-the-art perceiver resampler architecture and propose a novel method called PaLM2-VAdapter.
- PaLM2-VAdapter uses a progressively aligned language model as the vision-language adapter, which the authors show leads to faster convergence, higher performance, and stronger scalability compared to the perceiver resampler baseline.
- The proposed method achieves state-of-the-art results on various Visual Question Answering (VQA) and captioning tasks, with 30-70% fewer parameters than other large vision-language models.
Plain English Explanation
The paper focuses on finding an efficient way to combine powerful vision models (that can understand images) and powerful language models (that can understand text). These two types of AI models are often used separately, but the researchers wanted to find a way to bring them together to create AI systems that can understand both images and text.
The key insight is to use a "vision-language adapter" - a special component that can translate between the vision and language models. The researchers experimented with different architectures for this adapter, including the perceiver resampler and their own new method called PaLM2-VAdapter.
PaLM2-VAdapter uses a "progressively aligned language model" as the adapter, which means it gradually learns to translate between the vision and language models. This allows it to become more accurate and efficient over time. Compared to the perceiver resampler, the PaLM2-VAdapter method was found to converge faster, perform better, and scale more easily.
The researchers tested their method on tasks like Visual Question Answering (where you have to answer questions about an image) and image captioning. They found that their approach achieved state-of-the-art results, while using 30-70% fewer parameters than other large vision-language models. This makes it a more efficient and practical solution for real-world applications.
Technical Explanation
The paper explores the challenge of bridging the gap between frozen vision encoders and large language models (LLMs). While the fundamental architectures and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters vary significantly across recent works.
The authors first undertake a thorough exploration of the state-of-the-art perceiver resampler architecture and build a strong baseline. However, they observe that the vision-language alignment with perceiver resampler exhibits slow convergence and limited scalability, with a lack of direct supervision.
To address these issues, the researchers propose PaLM2-VAdapter, which employs a progressively aligned language model as the vision-language adapter. Compared to the perceiver resampler baseline, their method empirically shows faster convergence, higher performance, and stronger scalability.
The authors conduct extensive experiments across various Visual Question Answering (VQA) and captioning tasks on both images and videos. Their results demonstrate that the PaLM2-VAdapter model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, the proposed method achieves these advancements with 30-70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
Critical Analysis
The paper provides a thorough exploration of the challenges and limitations of existing vision-language adapter architectures, such as the perceiver resampler. The authors' insights into the slow convergence and limited scalability of these approaches are valuable contributions to the field.
While the PaLM2-VAdapter method represents a significant advancement, the paper does not delve into the potential drawbacks or limitations of this approach. For example, it would be helpful to understand the trade-offs in terms of computational complexity, training time, or potential biases that may arise from the progressive alignment technique.
Additionally, the paper could have provided more details on the specific architectural choices and training strategies employed in the PaLM2-VAdapter model. This information would allow other researchers to better understand the key innovations and potentially build upon or replicate the results.
Overall, the paper presents a compelling solution to the vision-language alignment problem and demonstrates impressive performance gains. However, a more comprehensive discussion of the method's limitations and potential areas for further research would strengthen the critical analysis and help readers evaluate the work more holistically.
Conclusion
This paper introduces a novel approach called PaLM2-VAdapter that effectively bridges the gap between frozen vision encoders and large language models (LLMs). By employing a progressively aligned language model as the vision-language adapter, the researchers were able to achieve faster convergence, higher performance, and stronger scalability compared to the state-of-the-art perceiver resampler architecture.
The paper's key contribution is the development of a more efficient and effective way to combine powerful vision and language models, which has significant implications for a wide range of multimodal AI applications, such as visual question answering and image captioning. By achieving state-of-the-art results with 30-70% fewer parameters than other large vision-language models, the PaLM2-VAdapter method represents an important step forward in creating more practical and scalable multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
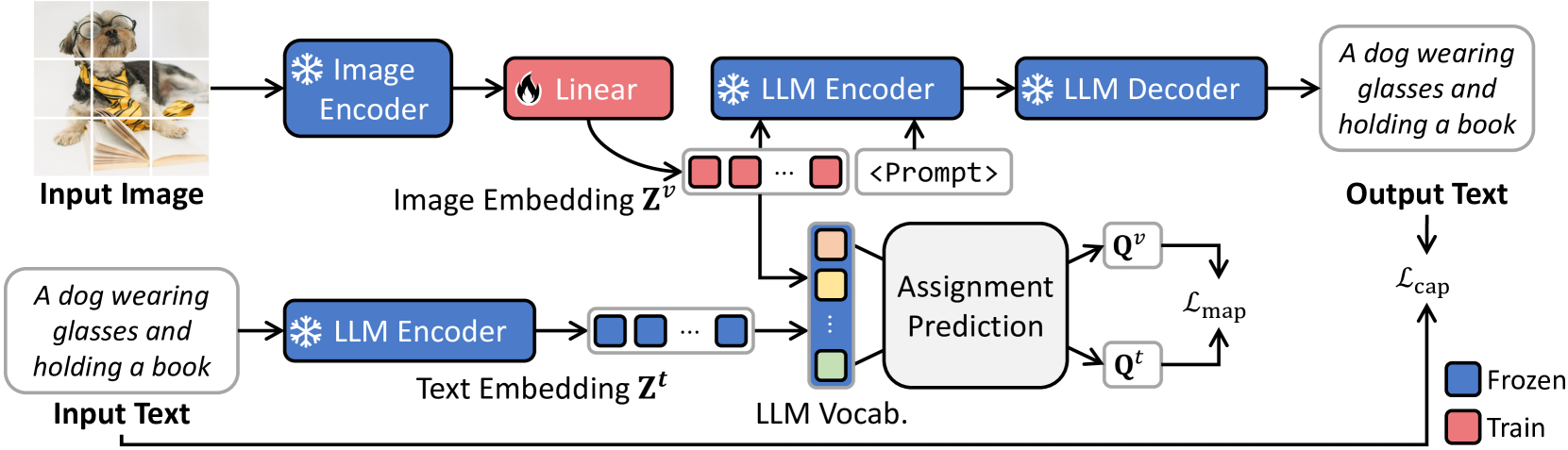
Bridging Vision and Language Spaces with Assignment Prediction
Jungin Park, Jiyoung Lee, Kwanghoon Sohn
0
0
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
4/16/2024

Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models
Juncheng Yang, Zuchao Li, Shuai Xie, Weiping Zhu, Wei Yu, Shijun Li
0
0
Adapter-based parameter-efficient transfer learning has achieved exciting results in vision-language models. Traditional adapter methods often require training or fine-tuning, facing challenges such as insufficient samples or resource limitations. While some methods overcome the need for training by leveraging image modality cache and retrieval, they overlook the text modality's importance and cross-modal cues for the efficient adaptation of parameters in visual-language models. This work introduces a cross-modal parameter-efficient approach named XMAdapter. XMAdapter establishes cache models for both text and image modalities. It then leverages retrieval through visual-language bimodal information to gather clues for inference. By dynamically adjusting the affinity ratio, it achieves cross-modal fusion, decoupling different modal similarities to assess their respective contributions. Additionally, it explores hard samples based on differences in cross-modal affinity and enhances model performance through adaptive adjustment of sample learning intensity. Extensive experimental results on benchmark datasets demonstrate that XMAdapter outperforms previous adapter-based methods significantly regarding accuracy, generalization, and efficiency.
4/22/2024

VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Wenhai Wang, Zhe Chen, Xizhou Zhu, Lewei Lu, Tong Lu, Ping Luo, Yu Qiao, Jifeng Dai
0
0
We present VisionLLM v2, an end-to-end generalist multimodal large model (MLLM) that unifies visual perception, understanding, and generation within a single framework. Unlike traditional MLLMs limited to text output, VisionLLM v2 significantly broadens its application scope. It excels not only in conventional visual question answering (VQA) but also in open-ended, cross-domain vision tasks such as object localization, pose estimation, and image generation and editing. To this end, we propose a new information transmission mechanism termed super link, as a medium to connect MLLM with task-specific decoders. It not only allows flexible transmission of task information and gradient feedback between the MLLM and multiple downstream decoders but also effectively resolves training conflicts in multi-tasking scenarios. In addition, to support the diverse range of tasks, we carefully collected and combed training data from hundreds of public vision and vision-language tasks. In this way, our model can be joint-trained end-to-end on hundreds of vision language tasks and generalize to these tasks using a set of shared parameters through different user prompts, achieving performance comparable to task-specific models. We believe VisionLLM v2 will offer a new perspective on the generalization of MLLMs.
6/17/2024
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
Manish Dhakal, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
0
0
Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning. The source code is available at: https://github.com/naamiinepal/vlsm-adapter.
6/28/2024