VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks

0
Sign in to get full access
Overview
- This paper introduces VLSM-Adapter, a novel approach to efficiently fine-tune vision-language segmentation models using lightweight adapter blocks.
- The key idea is to add small, task-specific adapter modules to a pre-trained vision-language model like CLIP, enabling efficient fine-tuning for downstream vision-language segmentation tasks.
- The VLSM-Adapter approach is shown to outperform full fine-tuning of the entire model, while requiring significantly fewer parameters and training steps.
- Experiments on medical imaging and urban scene segmentation tasks demonstrate the effectiveness of VLSM-Adapter in leveraging large pre-trained vision-language models for efficient transfer learning.
Plain English Explanation
Vision-language segmentation models are AI systems that can analyze images and associate relevant text or captions with different regions of the image. These models are powerful tools for tasks like medical image analysis or urban planning, but they can be complex and expensive to train from scratch.
The VLSM-Adapter approach introduced in this paper provides a way to efficiently fine-tune these vision-language segmentation models for new tasks and datasets. Instead of retraining the entire model, VLSM-Adapter adds small, specialized "adapter" blocks that can be trained on the new task while leaving the core model unchanged.
This adapter-based approach has several key advantages. First, it requires far fewer parameters to train compared to fine-tuning the entire model. This makes the process more efficient and reduces the computational resources needed. Second, the adapter blocks can be trained much faster than retraining the full model. This allows the model to be quickly adapted to new tasks or datasets.
The paper demonstrates the effectiveness of VLSM-Adapter on medical imaging and urban scene segmentation tasks. By leveraging large, pre-trained vision-language models like CLIP, the VLSM-Adapter approach is able to achieve strong performance while requiring far less training data and computational power than training a new model from scratch.
Technical Explanation
The VLSM-Adapter approach builds on the success of large pre-trained vision-language models like CLIP and FLORA for efficient transfer learning. Rather than fine-tuning the entire model, VLSM-Adapter introduces small, task-specific adapter modules that can be trained on downstream vision-language segmentation tasks.
The key components of VLSM-Adapter are:
- Backbone Model: A pre-trained vision-language model like CLIP is used as the backbone for the segmentation task.
- Adapter Modules: Small, lightweight adapter blocks are added to the backbone model. These adapter modules contain a few additional layers that can be trained on the new task, while the backbone model remains fixed.
- Training Procedure: During fine-tuning, only the adapter modules are trained, while the backbone model parameters are frozen. This allows for efficient training with far fewer parameters compared to full fine-tuning.
The paper evaluates VLSM-Adapter on two vision-language segmentation benchmarks:
- Medical Imaging: Fine-tuning for segmentation of anatomical structures in medical images.
- Urban Scenes: Segmenting semantic elements (e.g., buildings, roads, vehicles) in urban scene images.
Experiments show that VLSM-Adapter outperforms full fine-tuning approaches in terms of segmentation performance, while requiring significantly fewer training parameters and steps. This demonstrates the effectiveness of the adapter-based approach for efficient transfer learning in vision-language segmentation tasks.
Critical Analysis
The VLSM-Adapter paper presents a promising approach for efficient fine-tuning of vision-language segmentation models, but there are a few potential limitations and areas for further research:
-
Generalization to Other Tasks: While the paper demonstrates the effectiveness of VLSM-Adapter on medical imaging and urban scene segmentation, it's unclear how well the approach would generalize to other vision-language tasks, such as image captioning or visual question answering. Additional experiments on a broader range of tasks would help validate the broader applicability of the VLSM-Adapter approach.
-
Architectural Design Choices: The paper does not explore the impact of different adapter module architectures or placement within the backbone model. Further research could investigate how the adapter design and integration affect the fine-tuning performance and efficiency.
-
Scalability to Larger Datasets: The experiments in the paper were conducted on relatively small datasets, which may limit the generalization to larger-scale real-world vision-language segmentation problems. Evaluating VLSM-Adapter on larger datasets would provide a better understanding of its scalability.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of the VLSM-Adapter approach may be opaque. Investigating ways to improve the interpretability and explainability of the model's decision-making process could enhance trust and adoption in critical domains like medical imaging.
Overall, the VLSM-Adapter paper presents an interesting and valuable contribution to the field of efficient transfer learning for vision-language segmentation tasks. The adapter-based approach is a promising direction for leveraging large, pre-trained models while minimizing the computational and data requirements for fine-tuning.
Conclusion
The VLSM-Adapter paper introduces an efficient approach for fine-tuning vision-language segmentation models using lightweight adapter modules. By leveraging pre-trained vision-language models like CLIP and FLORA, VLSM-Adapter can achieve strong segmentation performance while requiring far fewer training parameters and steps compared to full fine-tuning.
The demonstrated effectiveness of VLSM-Adapter on medical imaging and urban scene segmentation tasks highlights its potential for efficient transfer learning in a wide range of vision-language applications. As large pre-trained models like CLIP and FLORA continue to advance, the VLSM-Adapter approach provides a promising pathway for leveraging these powerful models in a computationally and data-efficient manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
Manish Dhakal, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning. The source code is available at: https://github.com/naamiinepal/vlsm-adapter.
Read more6/28/2024
🔄
0
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Kanchan Poudel, Manish Dhakal, Prasiddha Bhandari, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
Medical image segmentation allows quantifying target structure size and shape, aiding in disease diagnosis, prognosis, surgery planning, and comprehension.Building upon recent advancements in foundation Vision-Language Models (VLMs) from natural image-text pairs, several studies have proposed adapting them to Vision-Language Segmentation Models (VLSMs) that allow using language text as an additional input to segmentation models. Introducing auxiliary information via text with human-in-the-loop prompting during inference opens up unique opportunities, such as open vocabulary segmentation and potentially more robust segmentation models against out-of-distribution data. Although transfer learning from natural to medical images has been explored for image-only segmentation models, the joint representation of vision-language in segmentation problems remains underexplored. This study introduces the first systematic study on transferring VLSMs to 2D medical images, using carefully curated $11$ datasets encompassing diverse modalities and insightful language prompts and experiments. Our findings demonstrate that although VLSMs show competitive performance compared to image-only models for segmentation after finetuning in limited medical image datasets, not all VLSMs utilize the additional information from language prompts, with image features playing a dominant role. While VLSMs exhibit enhanced performance in handling pooled datasets with diverse modalities and show potential robustness to domain shifts compared to conventional segmentation models, our results suggest that novel approaches are required to enable VLSMs to leverage the various auxiliary information available through language prompts. The code and datasets are available at https://github.com/naamiinepal/medvlsm.
Read more6/21/2024
0
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
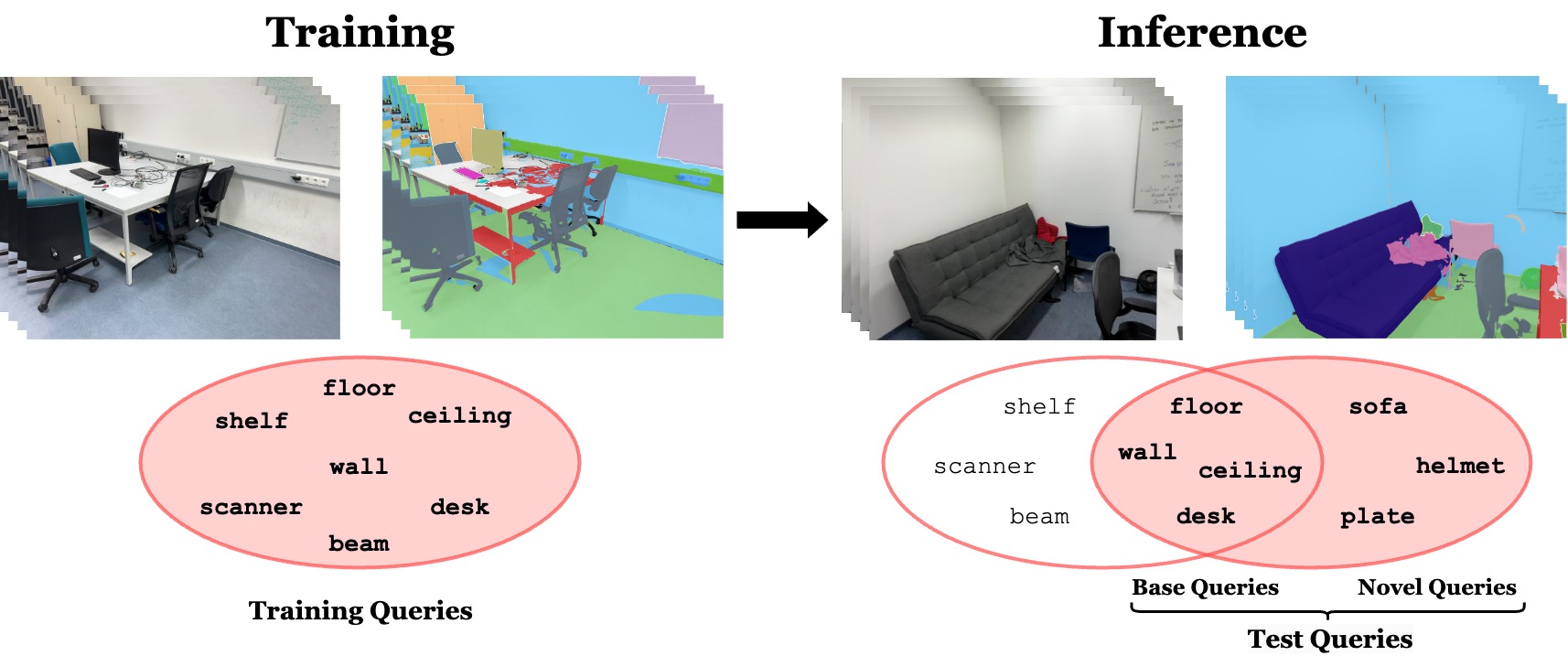
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
Read more5/31/2024

0
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Amaia Cardiel, Eloi Zablocki, Oriane Sim'eoni, Elias Ramzi, Matthieu Cord
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.
Read more9/19/2024