Bridging Vision and Language Spaces with Assignment Prediction
2404.09632
0
0
Abstract
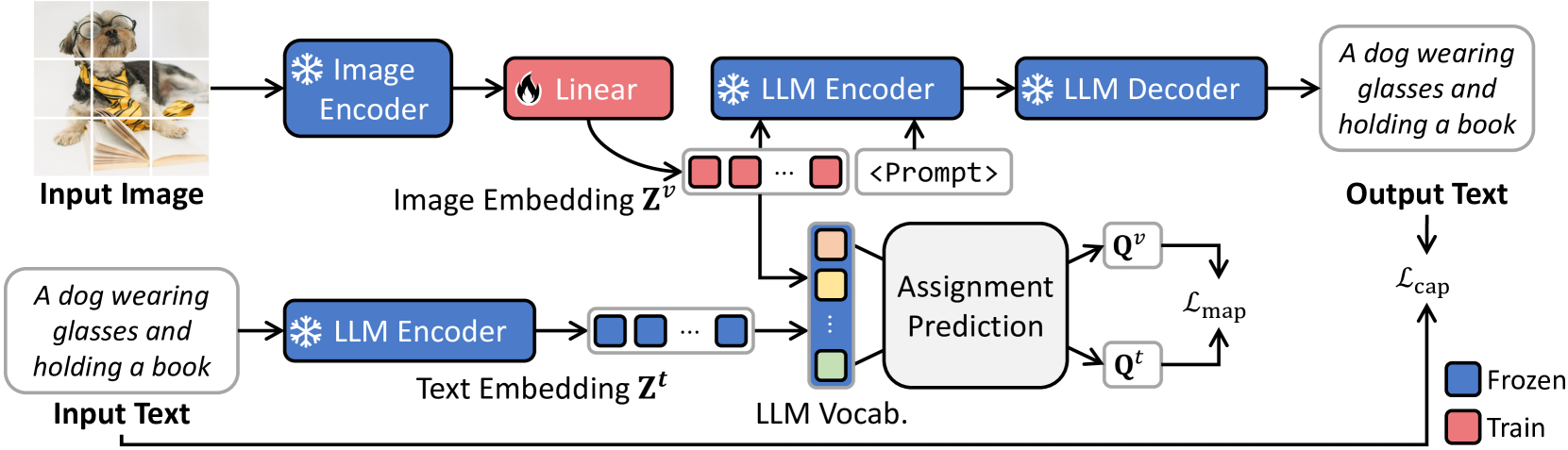
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
Create account to get full access
Overview
- The paper explores a novel approach for bridging the gap between vision and language models by predicting visual-linguistic assignments.
- The proposed method aims to learn a shared representation between visual and textual data, enabling more effective cross-modal understanding and generation.
- The researchers design an assignment prediction task to align visual and language spaces, leveraging both supervised and unsupervised learning signals.
- Experiments demonstrate the model's ability to outperform state-of-the-art methods on a range of vision-language tasks, including image captioning, visual question answering, and zero-shot classification.
Plain English Explanation
The paper presents a new way to connect visual and language models, which are two important types of artificial intelligence (AI) systems. Visual models process and understand images, while language models work with text. The researchers developed a technique to link these two types of models together by predicting how visual elements (like objects in an image) should be assigned to linguistic concepts (like words describing those objects).
By learning this connection between vision and language, the model can better understand the relationship between what it sees and what it reads. This allows the model to perform tasks that require understanding both visual and textual information, like describing images with captions or answering questions about images.
The researchers show that their model outperforms other state-of-the-art approaches on a variety of these vision-language tasks. This suggests their bridging technique is an effective way to combine the strengths of visual and language models, leading to more capable and well-rounded AI systems.
Technical Explanation
The paper introduces a novel assignment prediction task to align visual and language representations. The model is trained to predict which visual elements (e.g., objects, attributes) should be assigned to which linguistic concepts (e.g., words, phrases) based on their semantic and visual similarity.
This assignment prediction task is formulated as a supervised learning problem, where the model learns to map visual features to language tokens. The researchers also incorporate unsupervised learning signals, such as contrastive loss, to further refine the joint embedding space.
Experiments are conducted on a range of vision-language benchmarks, including image captioning, visual question answering, and zero-shot classification. The proposed approach demonstrates state-of-the-art performance, outperforming previous methods that rely on separate vision and language models or more simplistic alignment techniques.
The key innovation of this work is the use of assignment prediction as a self-supervised pretraining task to bridge the gap between visual and language representations. This allows the model to learn richer cross-modal associations, which can then be leveraged for downstream vision-language applications.
Critical Analysis
The paper presents a compelling approach for aligning visual and language models, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The performance of the model may be influenced by biases present in the training datasets used for the various benchmarks. It would be valuable to assess the model's robustness to out-of-distribution samples or alternative datasets.
-
Interpretability: While the assignment prediction task provides a mechanism for linking visual and language spaces, the interpretability of the learned associations could be further explored. Providing more insight into the model's reasoning could help users understand and trust the model's outputs.
-
Generalization to Novel Concepts: The paper focuses on evaluating the model's performance on existing visual and linguistic concepts. It would be interesting to investigate its ability to generalize to novel, unseen concepts through zero-shot or few-shot learning.
-
Real-world Applications: While the benchmarks used in the paper are well-established, exploring the model's performance in more realistic, end-user applications could provide additional insights and guide future research directions.
Overall, the paper presents an innovative approach that demonstrates the potential of bridging vision and language models to unlock more powerful and versatile AI systems. Further research on the proposed method's limitations and real-world implications could lead to even more impactful advancements in this field.
Conclusion
The paper introduces a novel assignment prediction task to align visual and language representations, enabling more effective cross-modal understanding and generation. The proposed approach outperforms state-of-the-art methods on a range of vision-language benchmarks, showcasing the potential of connecting visual and language models to create more capable and versatile AI systems.
While the paper presents a promising solution, there are opportunities for further research to address potential limitations, such as dataset bias, model interpretability, and generalization to novel concepts. Exploring the real-world applications of this technique could also lead to impactful advancements in the field of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
0
0
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
5/28/2024
💬
PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter
Junfei Xiao, Zheng Xu, Alan Yuille, Shen Yan, Boyu Wang
0
0
This paper demonstrates that a progressively aligned language model can effectively bridge frozen vision encoders and large language models (LLMs). While the fundamental architecture and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters vary significantly across recent works. Our research undertakes a thorough exploration of the state-of-the-art perceiver resampler architecture and builds a strong baseline. However, we observe that the vision-language alignment with perceiver resampler exhibits slow convergence and limited scalability with a lack of direct supervision. To address this issue, we propose PaLM2-VAdapter, employing a progressively aligned language model as the vision-language adapter. Compared to the strong baseline with perceiver resampler, our method empirically shows faster convergence, higher performance, and stronger scalability. Extensive experiments across various Visual Question Answering (VQA) and captioning tasks on both images and videos demonstrate that our model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, our method achieves these advancements with 30~70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
6/4/2024
💬
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh
0
0
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
5/31/2024

Where Visual Speech Meets Language: VSP-LLM Framework for Efficient and Context-Aware Visual Speech Processing
Jeong Hun Yeo, Seunghee Han, Minsu Kim, Yong Man Ro
0
0
In visual speech processing, context modeling capability is one of the most important requirements due to the ambiguous nature of lip movements. For example, homophenes, words that share identical lip movements but produce different sounds, can be distinguished by considering the context. In this paper, we propose a novel framework, namely Visual Speech Processing incorporated with LLMs (VSP-LLM), to maximize the context modeling ability by bringing the overwhelming power of LLMs. Specifically, VSP-LLM is designed to perform multi-tasks of visual speech recognition and translation, where the given instructions control the type of task. The input video is mapped to the input latent space of an LLM by employing a self-supervised visual speech model. Focused on the fact that there is redundant information in input frames, we propose a novel deduplication method that reduces the embedded visual features by employing visual speech units. Through the proposed deduplication and Low Rank Adaptation (LoRA), VSP-LLM can be trained in a computationally efficient manner. In the translation dataset, the MuAViC benchmark, we demonstrate that VSP-LLM trained on just 30 hours of labeled data can more effectively translate lip movements compared to the recent model trained with 433 hours of data.
5/15/2024