ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
2403.01139
0
0

Abstract
Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
Create account to get full access
Overview
- This paper introduces ParallelPARC, a scalable pipeline for generating high-quality natural-language analogies.
- Analogies are a fundamental cognitive ability that allows humans to reason by drawing parallels between concepts. However, existing analogy datasets are limited in size and diversity.
- ParallelPARC addresses this gap by leveraging large language models and parallel computing to efficiently generate a large and diverse dataset of natural-language analogies.
Plain English Explanation
Analogies are a way of understanding new concepts by comparing them to things we already know. For example, we might say "life is like a journey" to help explain the idea of life having different stages and experiences.
The ParallelPARC paper introduces a new system that can automatically generate a large number of high-quality analogies. This is useful because existing analogy datasets are quite small and don't cover a wide range of topics.
The key innovation in ParallelPARC is that it uses powerful language models and parallel computing to quickly create thousands of analogies. This allows researchers and developers to have access to a much richer set of analogies to work with, which could in turn improve AI systems that rely on analogical reasoning.
The paper demonstrates that ParallelPARC can generate analogies on diverse topics like paraphrasing, code generation, visual reasoning, and natural language inference. This shows the broad applicability of the ParallelPARC approach.
Technical Explanation
The ParallelPARC paper describes a scalable pipeline for generating high-quality natural-language analogies. The key components are:
-
Analogy Template Generation: The system starts by automatically generating a large set of analogy templates, which provide the general structure for the analogies (e.g. "X is to Y as A is to B").
-
Slot Filling: These templates are then populated with concrete concepts using a large language model, which selects relevant and coherent filler terms to create complete analogy pairs.
-
Parallel Processing: To scale the generation process, the authors leverage parallel computing to simultaneously create thousands of analogies in a distributed manner.
The authors evaluate the quality of the generated analogies through human evaluation, showing that ParallelPARC can produce analogies that are on par with human-authored examples. They also demonstrate the utility of the generated dataset by using it to improve performance on a variety of downstream NLP tasks, including paraphrasing, code generation, visual reasoning, and natural language inference.
Critical Analysis
The ParallelPARC approach is a promising step towards generating large-scale, high-quality analogy datasets. However, the paper does acknowledge a few limitations:
-
Template Quality: The quality of the generated analogies is ultimately bounded by the quality of the initial analogy templates. The authors note that more sophisticated template generation techniques could further improve the results.
-
Topical Bias: While the dataset covers a wide range of topics, there may still be biases towards certain domains that are more represented in the underlying language model's training data.
-
Semantic Coherence: The authors mention that some of the generated analogies, while syntactically well-formed, may not exhibit the desired semantic coherence and parallelism. Addressing this could be an area for future research.
Additionally, it would be interesting to see how ParallelPARC's performance compares to other analogy generation approaches, such as those based on knowledge-informed models or few-shot learning. This could help contextualize the strengths and weaknesses of the ParallelPARC method.
Conclusion
The ParallelPARC paper presents a scalable and effective pipeline for generating high-quality natural-language analogies. By leveraging large language models and parallel computing, the authors are able to create a diverse dataset of analogies that can benefit a wide range of NLP applications.
While the approach has some limitations, the results demonstrate the potential of ParallelPARC to significantly expand the available resources for developing and evaluating AI systems that rely on analogical reasoning. As the field of natural language processing continues to evolve, tools like ParallelPARC may play an important role in advancing our understanding of how humans use analogies to make sense of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
ARN: Analogical Reasoning on Narratives
Zhivar Sourati, Filip Ilievski, Pia Sommerauer, Yifan Jiang
0
0
As a core cognitive skill that enables the transferability of information across domains, analogical reasoning has been extensively studied for both humans and computational models. However, while cognitive theories of analogy often focus on narratives and study the distinction between surface, relational, and system similarities, existing work in natural language processing has a narrower focus as far as relational analogies between word pairs. This gap brings a natural question: can state-of-the-art large language models (LLMs) detect system analogies between narratives? To gain insight into this question and extend word-based relational analogies to relational system analogies, we devise a comprehensive computational framework that operationalizes dominant theories of analogy, using narrative elements to create surface and system mappings. Leveraging the interplay between these mappings, we create a binary task and benchmark for Analogical Reasoning on Narratives (ARN), covering four categories of far (cross-domain)/near (within-domain) analogies and disanalogies. We show that while all LLMs can largely recognize near analogies, even the largest ones struggle with far analogies in a zero-shot setting, with GPT4.0 scoring below random. Guiding the models through solved examples and chain-of-thought reasoning enhances their analogical reasoning ability. Yet, since even in the few-shot setting, the best model only performs halfway between random and humans, ARN opens exciting directions for computational analogical reasoners.
4/24/2024
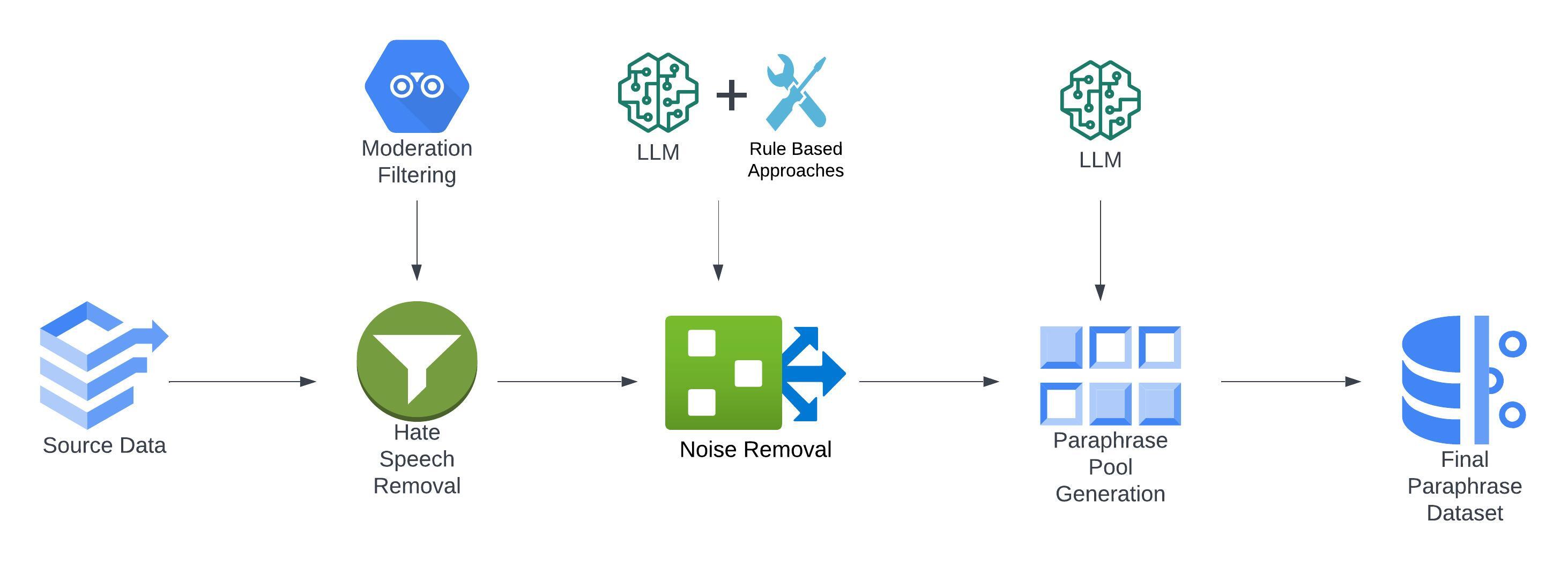
ParaFusion: A Large-Scale LLM-Driven English Paraphrase Dataset Infused with High-Quality Lexical and Syntactic Diversity
Lasal Jayawardena, Prasan Yapa
0
0
Paraphrase generation is a pivotal task in natural language processing (NLP). Existing datasets in the domain lack syntactic and lexical diversity, resulting in paraphrases that closely resemble the source sentences. Moreover, these datasets often contain hate speech and noise, and may unintentionally include non-English language sentences. This research introduces ParaFusion, a large-scale, high-quality English paraphrase dataset developed using Large Language Models (LLM) to address these challenges. ParaFusion augments existing datasets with high-quality data, significantly enhancing both lexical and syntactic diversity while maintaining close semantic similarity. It also mitigates the presence of hate speech and reduces noise, ensuring a cleaner and more focused English dataset. Results show that ParaFusion offers at least a 25% improvement in both syntactic and lexical diversity, measured across several metrics for each data source. The paper also aims to set a gold standard for paraphrase evaluation as it contains one of the most comprehensive evaluation strategies to date. The results underscore the potential of ParaFusion as a valuable resource for improving NLP applications.
4/19/2024
💬
Can Large Language Models Write Parallel Code?
Daniel Nichols, Joshua H. Davis, Zhaojun Xie, Arjun Rajaram, Abhinav Bhatele
0
0
Large language models are increasingly becoming a popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for complex programs. In this paper, we study the capabilities of state-of-the-art language models to generate parallel code. In order to evaluate language models, we create a benchmark, ParEval, consisting of prompts that represent 420 different coding tasks related to scientific and parallel computing. We use ParEval to evaluate the effectiveness of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for evaluating the performance of generated code, and use them to explore how well each large language model performs for 12 different computational problem types and six different parallel programming models.
5/15/2024
💬
ANALOGYKB: Unlocking Analogical Reasoning of Language Models with A Million-scale Knowledge Base
Siyu Yuan, Jiangjie Chen, Changzhi Sun, Jiaqing Liang, Yanghua Xiao, Deqing Yang
0
0
Analogical reasoning is a fundamental cognitive ability of humans. However, current language models (LMs) still struggle to achieve human-like performance in analogical reasoning tasks due to a lack of resources for model training. In this work, we address this gap by proposing ANALOGYKB, a million-scale analogy knowledge base (KB) derived from existing knowledge graphs (KGs). ANALOGYKB identifies two types of analogies from the KGs: 1) analogies of the same relations, which can be directly extracted from the KGs, and 2) analogies of analogous relations, which are identified with a selection and filtering pipeline enabled by large language models (LLMs), followed by minor human efforts for data quality control. Evaluations on a series of datasets of two analogical reasoning tasks (analogy recognition and generation) demonstrate that ANALOGYKB successfully enables both smaller LMs and LLMs to gain better analogical reasoning capabilities.
5/20/2024