ParaFusion: A Large-Scale LLM-Driven English Paraphrase Dataset Infused with High-Quality Lexical and Syntactic Diversity
2404.12010
0
0
Abstract
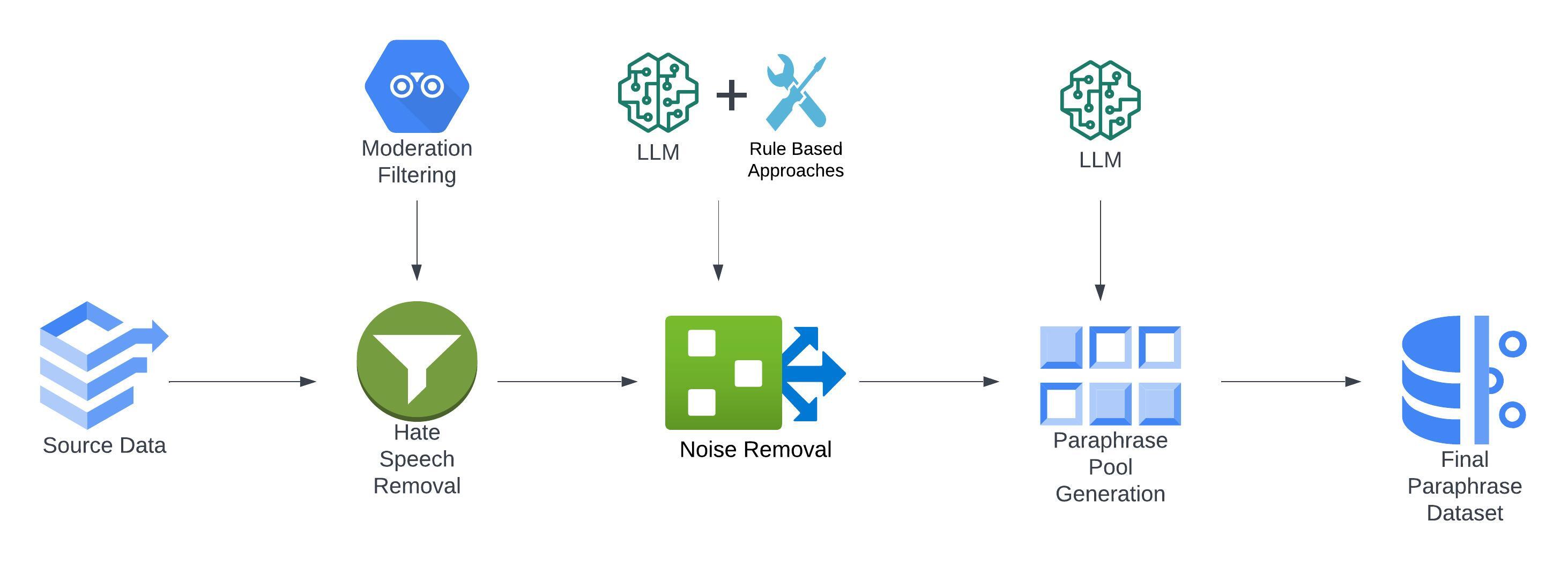
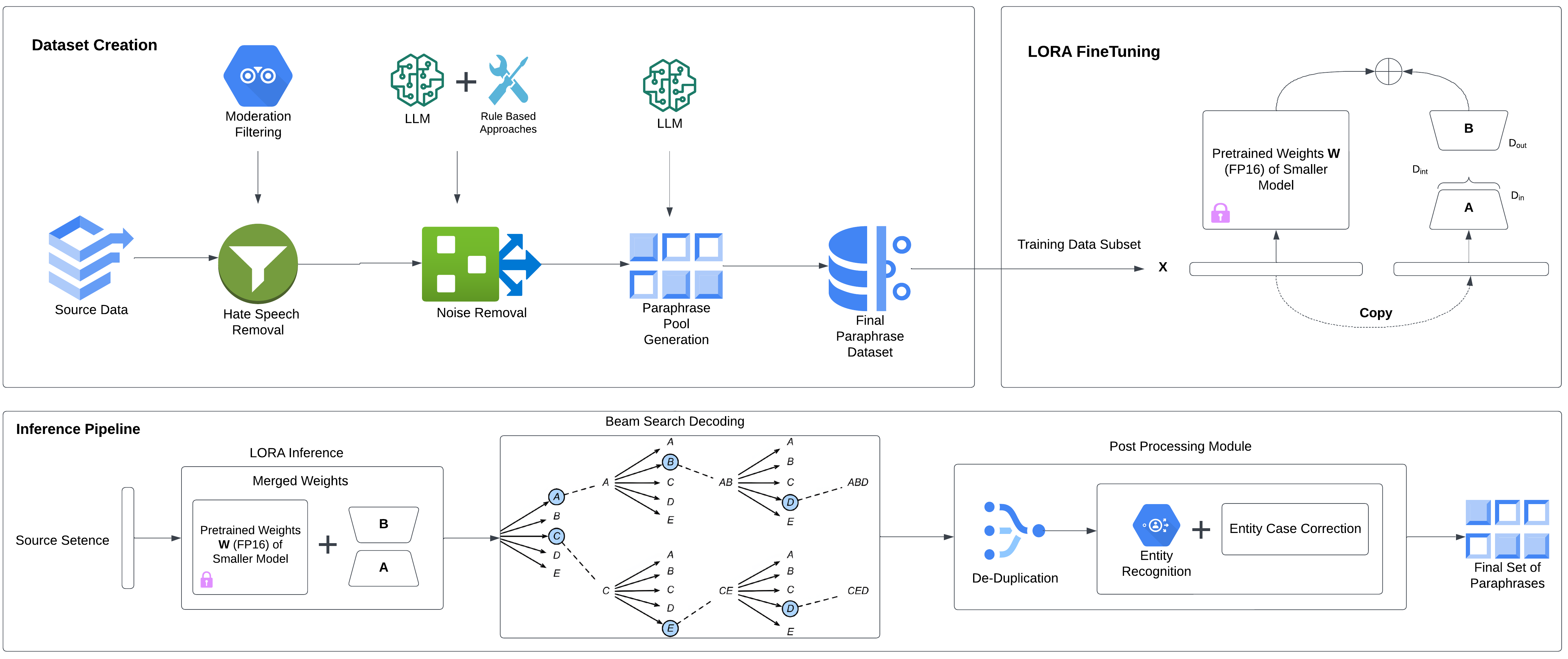
Paraphrase generation is a pivotal task in natural language processing (NLP). Existing datasets in the domain lack syntactic and lexical diversity, resulting in paraphrases that closely resemble the source sentences. Moreover, these datasets often contain hate speech and noise, and may unintentionally include non-English language sentences. This research introduces ParaFusion, a large-scale, high-quality English paraphrase dataset developed using Large Language Models (LLM) to address these challenges. ParaFusion augments existing datasets with high-quality data, significantly enhancing both lexical and syntactic diversity while maintaining close semantic similarity. It also mitigates the presence of hate speech and reduces noise, ensuring a cleaner and more focused English dataset. Results show that ParaFusion offers at least a 25% improvement in both syntactic and lexical diversity, measured across several metrics for each data source. The paper also aims to set a gold standard for paraphrase evaluation as it contains one of the most comprehensive evaluation strategies to date. The results underscore the potential of ParaFusion as a valuable resource for improving NLP applications.
Create account to get full access
Overview
- This paper introduces ParaFusion, a large-scale English paraphrase dataset generated using large language models (LLMs).
- The dataset is designed to have high-quality lexical and syntactic diversity, making it useful for training and evaluating natural language generation models.
- The authors leverage the power of LLMs to generate diverse, high-quality paraphrases for a broad range of input sentences.
Plain English Explanation
The researchers behind this paper have created a new dataset called ParaFusion that contains a large number of English sentences and their paraphrased versions. Paraphrasing is the process of rephrasing a sentence while preserving its meaning. The researchers used powerful language models, known as large language models (LLMs), to generate these paraphrased sentences in a way that captures a lot of diversity in the vocabulary and sentence structure.
This dataset is valuable because it can be used to train and test machine learning models that are designed to generate natural-sounding language. By having access to a large number of high-quality paraphrases, these models can learn to produce diverse and fluent text that conveys the same meaning in different ways. This can be useful for applications like automatic text summarization, language translation, and image captioning.
Technical Explanation
The authors of this paper developed a novel approach to create the ParaFusion dataset. They first collected a large corpus of English sentences from various sources, including books, websites, and social media. They then used advanced language models, such as GPT-3, to generate multiple paraphrased versions of each input sentence.
To ensure the quality and diversity of the paraphrases, the authors implemented several techniques. They used reinforcement learning to train the language models to generate paraphrases that preserve the original meaning while exhibiting a wide range of lexical and syntactic variations. They also applied filtering and validation steps to remove low-quality or repetitive paraphrases.
The final ParaFusion dataset contains over 3 million unique paraphrase pairs, making it one of the largest high-quality paraphrase datasets available. The authors conducted several experiments to demonstrate the usefulness of ParaFusion for training and evaluating natural language generation models. They showed that models trained on ParaFusion can generate more diverse and natural-sounding paraphrases compared to models trained on other existing datasets.
Critical Analysis
The ParaFusion dataset represents a significant advancement in the field of paraphrase generation and natural language processing. By leveraging the power of large language models, the authors have been able to create a dataset that captures a wide range of lexical and syntactic diversity, which is a crucial factor for training robust language generation models.
However, the authors also acknowledge some limitations of their approach. The dataset may still contain some low-quality or unnatural paraphrases, despite the filtering and validation steps. Additionally, the authors note that the ParaFusion dataset is primarily focused on English and may not capture the nuances of other languages.
Further research could explore ways to expand the ParaFusion dataset to include more languages, or to develop techniques for generating even higher-quality and more diverse paraphrases. Additionally, exploring the use of controllable text generation methods could lead to even more targeted and useful paraphrase datasets.
Conclusion
The ParaFusion dataset represents a significant contribution to the field of natural language processing. By providing a large-scale, high-quality dataset of paraphrased sentences, the researchers have enabled the development of more robust and versatile language generation models. This, in turn, can lead to improved performance in a wide range of applications, such as translation, summarization, and dialogue systems. As the field of AI continues to advance, datasets like ParaFusion will play an increasingly important role in pushing the boundaries of what is possible in natural language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
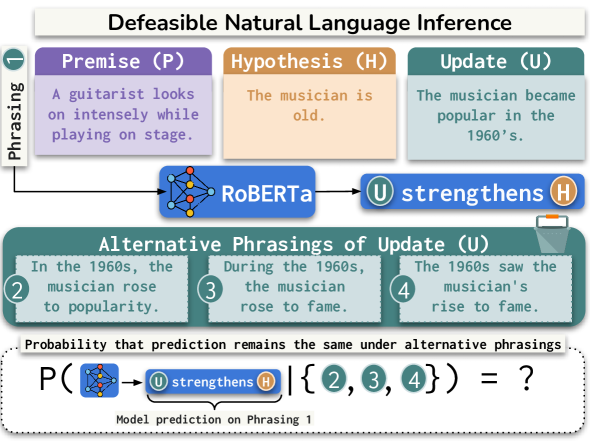
How often are errors in natural language reasoning due to paraphrastic variability?
Neha Srikanth, Marine Carpuat, Rachel Rudinger
0
0
Large language models have been shown to behave inconsistently in response to meaning-preserving paraphrastic inputs. At the same time, researchers evaluate the knowledge and reasoning abilities of these models with test evaluations that do not disaggregate the effect of paraphrastic variability on performance. We propose a metric for evaluating the paraphrastic consistency of natural language reasoning models based on the probability of a model achieving the same correctness on two paraphrases of the same problem. We mathematically connect this metric to the proportion of a model's variance in correctness attributable to paraphrasing. To estimate paraphrastic consistency, we collect ParaNLU, a dataset of 7,782 human-written and validated paraphrased reasoning problems constructed on top of existing benchmark datasets for defeasible and abductive natural language inference. Using ParaNLU, we measure the paraphrastic consistency of several model classes and show that consistency dramatically increases with pretraining but not finetuning. All models tested exhibited room for improvement in paraphrastic consistency.
4/19/2024

PlagBench: Exploring the Duality of Large Language Models in Plagiarism Generation and Detection
Jooyoung Lee, Toshini Agrawal, Adaku Uchendu, Thai Le, Jinghui Chen, Dongwon Lee
0
0
Recent literature has highlighted potential risks to academic integrity associated with large language models (LLMs), as they can memorize parts of training instances and reproduce them in the generated texts without proper attribution. In addition, given their capabilities in generating high-quality texts, plagiarists can exploit LLMs to generate realistic paraphrases or summaries indistinguishable from original work. In response to possible malicious use of LLMs in plagiarism, we introduce PlagBench, a comprehensive dataset consisting of 46.5K synthetic plagiarism cases generated using three instruction-tuned LLMs across three writing domains. The quality of PlagBench is ensured through fine-grained automatic evaluation for each type of plagiarism, complemented by human annotation. We then leverage our proposed dataset to evaluate the plagiarism detection performance of five modern LLMs and three specialized plagiarism checkers. Our findings reveal that GPT-3.5 tends to generates paraphrases and summaries of higher quality compared to Llama2 and GPT-4. Despite LLMs' weak performance in summary plagiarism identification, they can surpass current commercial plagiarism detectors. Overall, our results highlight the potential of LLMs to serve as robust plagiarism detection tools.
6/26/2024
Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
Lasal Jayawardena, Prasan Yapa
0
0
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
4/22/2024

ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
Oren Sultan, Yonatan Bitton, Ron Yosef, Dafna Shahaf
0
0
Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
5/15/2024