Parameter-Efficient Fine-Tuning via Circular Convolution

0

Sign in to get full access
Overview
- The paper introduces a novel parameter-efficient fine-tuning method called Circular Convolution (CC).
- CC aims to improve the performance of fine-tuning large language models on downstream tasks while using fewer trainable parameters.
- The method involves applying a circular convolution operation to the base model's weights, which enables efficient updating of the model's parameters.
Plain English Explanation
The paper proposes a new way to fine-tune large language models, like those used for tasks such as text generation or question answering. Fine-tuning is the process of updating a pre-trained model to perform well on a specific task, but it can often require a lot of new trainable parameters, which can be computationally expensive and time-consuming.
The Circular Convolution (CC) method aims to address this by using a special type of mathematical operation called circular convolution. This allows the model to be fine-tuned with fewer new parameters, while still achieving good performance on the target task. The key idea is that the circular convolution operation can efficiently update the model's existing weights, rather than requiring the addition of many new parameters.
Technical Explanation
The paper presents the Circular Convolution (CC) method for parameter-efficient fine-tuning of large language models. The authors first provide an overview of related work in the area of parameter-efficient fine-tuning techniques, such as LoRA, Batched Low-Rank Adaptation, and MORA.
The Circular Convolution (CC) method involves applying a circular convolution operation to the base model's weights during fine-tuning. This allows the model to be updated with a small number of new trainable parameters, while still achieving good performance on the target task. The authors provide a detailed explanation of the CC method, including the mathematical formulation and how it can be efficiently implemented.
The paper also includes extensive experiments evaluating the performance of CC on a variety of language tasks, including text classification, question answering, and natural language inference. The results demonstrate that CC can match or outperform other parameter-efficient fine-tuning methods while using significantly fewer trainable parameters.
Critical Analysis
The paper provides a thorough and well-designed evaluation of the Circular Convolution (CC) method, including comparisons to a range of related techniques. However, the authors do not discuss potential limitations or caveats of the approach.
One area that could be explored further is the impact of the circular convolution operation on the model's interpretability and understanding of the underlying task. It is possible that the efficient parameter updating mechanism could lead to less transparent or intuitive model behavior, which would be an important consideration for real-world applications.
Additionally, the paper focuses on language tasks, but it would be valuable to investigate the performance of CC on other domains, such as computer vision or speech recognition, to assess its broader applicability.
Conclusion
The Circular Convolution (CC) method presented in this paper offers a promising approach for parameter-efficient fine-tuning of large language models. By leveraging a circular convolution operation, the method can update a model's weights with a small number of trainable parameters, while maintaining strong performance on a variety of language tasks.
The efficiency and flexibility of CC could make it a valuable tool for researchers and practitioners working with large-scale language models, particularly in resource-constrained environments or when rapid fine-tuning is required. The technique's broader applicability and potential impact on model interpretability warrant further investigation, but the paper's findings suggest it is a significant contribution to the field of parameter-efficient fine-tuning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Parameter-Efficient Fine-Tuning via Circular Convolution
Aochuan Chen, Jiashun Cheng, Zijing Liu, Ziqi Gao, Fugee Tsung, Yu Li, Jia Li
Low-Rank Adaptation (LoRA) has gained popularity for fine-tuning large foundation models, leveraging low-rank matrices $mathbf{A}$ and $mathbf{B}$ to represent weight changes (i.e., $Delta mathbf{W} = mathbf{B} mathbf{A}$). This method reduces trainable parameters and mitigates heavy memory consumption associated with full delta matrices by sequentially multiplying $mathbf{A}$ and $mathbf{B}$ with the activation. Despite its success, the intrinsic low-rank characteristic may limit its performance. Although several variants have been proposed to address this issue, they often overlook the crucial computational and memory efficiency brought by LoRA. In this paper, we propose Circular Convolution Adaptation (C$^3$A), which not only achieves high-rank adaptation with enhanced performance but also excels in both computational power and memory utilization. Extensive experiments demonstrate that C$^3$A consistently outperforms LoRA and its variants across various fine-tuning tasks.
Read more8/22/2024
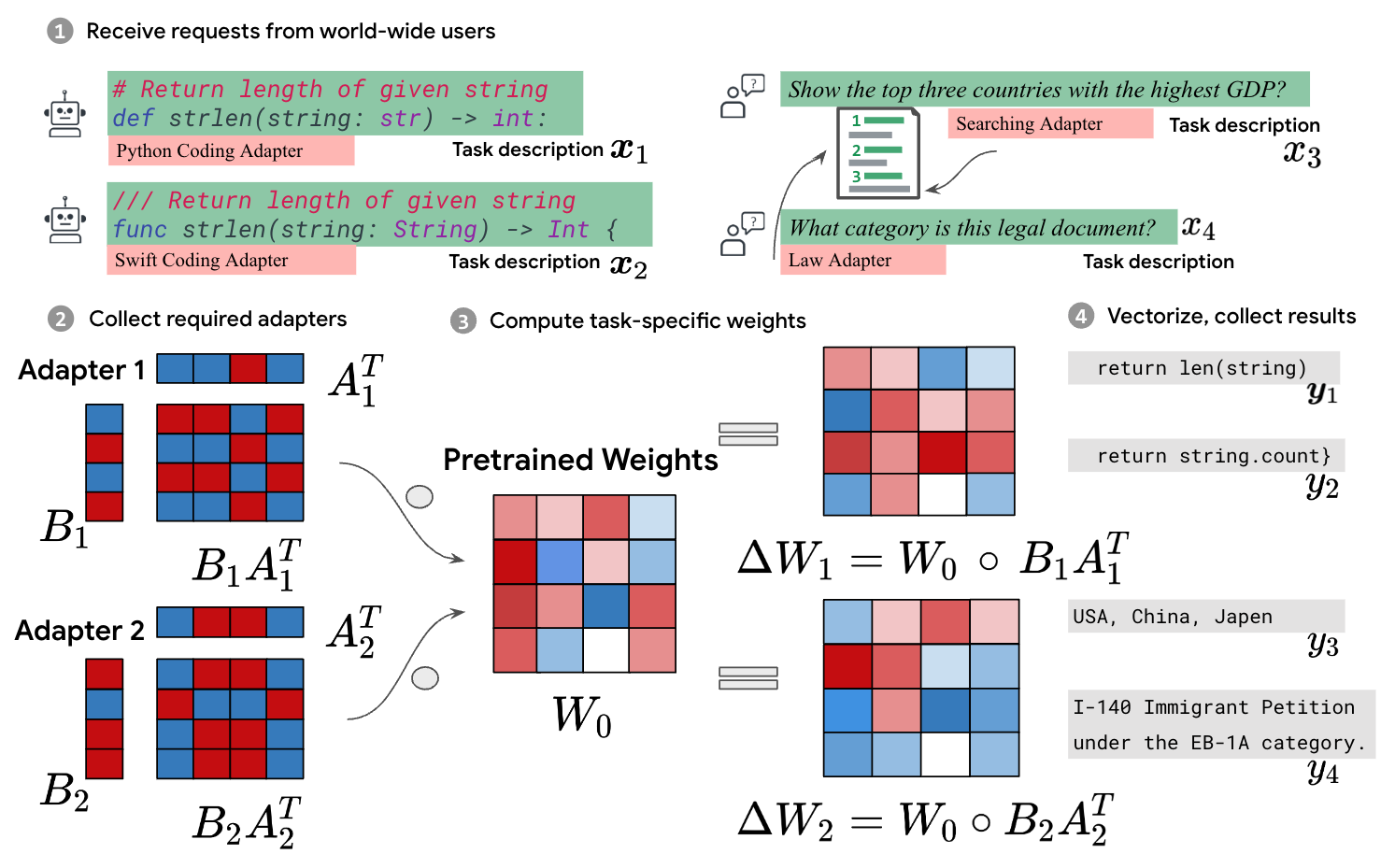
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024

2
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Ting Jiang, Shaohan Huang, Shengyue Luo, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, Fuzhen Zhuang
Low-rank adaptation is a popular parameter-efficient fine-tuning method for large language models. In this paper, we analyze the impact of low-rank updating, as implemented in LoRA. Our findings suggest that the low-rank updating mechanism may limit the ability of LLMs to effectively learn and memorize new knowledge. Inspired by this observation, we propose a new method called MoRA, which employs a square matrix to achieve high-rank updating while maintaining the same number of trainable parameters. To achieve it, we introduce the corresponding non-parameter operators to reduce the input dimension and increase the output dimension for the square matrix. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes our method can be deployed like LoRA. We perform a comprehensive evaluation of our method across five tasks: instruction tuning, mathematical reasoning, continual pretraining, memory and pretraining. Our method outperforms LoRA on memory-intensive tasks and achieves comparable performance on other tasks.
Read more5/21/2024