ParaNames 1.0: Creating an Entity Name Corpus for 400+ Languages using Wikidata
2405.09496
0
0
👁️
Abstract
We introduce ParaNames, a massively multilingual parallel name resource consisting of 140 million names spanning over 400 languages. Names are provided for 16.8 million entities, and each entity is mapped from a complex type hierarchy to a standard type (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate the usefulness of ParaNames on two tasks. First, we perform canonical name translation between English and 17 other languages. Second, we use it as a gazetteer for multilingual named entity recognition, obtaining performance improvements on all 10 languages evaluated.
Create account to get full access
Overview
• The paper presents ParaNames 1.0, a corpus of entity names in over 400 languages using Wikidata.
• The corpus aims to support research in cross-lingual named entity recognition and other multilingual NLP tasks.
• The authors describe the process of extracting and cleaning entity name data from Wikidata, a collaborative knowledge base.
• The resulting corpus provides a rich resource for exploring linguistic diversity and developing more inclusive AI systems.
Plain English Explanation
The researchers created a new dataset called ParaNames 1.0 that contains millions of entity names across over 400 languages. Entity names are the proper names of things like people, places, and organizations.
This dataset was built using information from Wikidata, a collaborative online knowledge base that stores facts about the world in many languages. The researchers extracted all the entity names they could find in Wikidata, cleaned up the data, and organized it into a useful corpus.
Having a large, diverse corpus of entity names is valuable for training AI models to recognize and understand names, especially in less-common languages. This can help make AI systems more inclusive and able to work with a wide range of languages, instead of just focusing on the most widely-spoken ones.
The ParaNames corpus provides a rich resource for studying linguistic diversity and developing more multilingual, equitable AI technologies. It's an important step towards building AI that can truly understand and interact with people from all around the world.
Technical Explanation
The ParaNames 1.0 corpus was created by extracting entity name data from Wikidata, a collaboratively edited knowledge base that stores structured information in over 400 languages. The researchers developed a pipeline to systematically extract all entity names, normalize the text, and organize the data into a standardized format.
Key steps in the ParaNames creation process included:
- Querying the Wikidata API to retrieve all entity items and their associated labels, descriptions, and aliases across supported languages.
- Cleaning and normalizing the extracted entity name data, handling issues like character encoding, spelling variations, and incomplete/inconsistent entries.
- Organizing the cleaned data into a corpus structure, including metadata about each entity such as its Wikidata ID, type, and language.
The resulting ParaNames 1.0 corpus contains over 100 million entity names spanning 408 languages, representing a diverse range of cultural, geographic, and linguistic perspectives. This large-scale multilingual dataset can support research in cross-lingual named entity recognition, entity-centric multilingual language modeling, and other areas of multilingual natural language processing.
Critical Analysis
The ParaNames corpus represents a valuable resource for the NLP research community, providing broad linguistic coverage and enabling new avenues of inquiry. However, some caveats and limitations should be considered:
- The data is derived from Wikidata, which may have biases in its coverage and representativeness of the world's languages and cultures. Underrepresented communities may have fewer entity names included.
- The data cleaning and normalization process, while necessary, could inadvertently introduce artifacts or lose nuance in the original names.
- The corpus does not provide contextual information about the entities, limiting its usefulness for certain applications like named entity disambiguation.
Ongoing work is needed to further expand the language coverage, improve data quality, and enrich the corpus with additional metadata and relational information. Collaborations with linguists, anthropologists, and other domain experts could help ensure the corpus accurately reflects global linguistic diversity.
Despite these challenges, ParaNames 1.0 represents an important step towards building more inclusive and representative AI systems. Continued research and development in this area has the potential to create NLP technologies that better serve the needs of multilingual, multicultural global communities.
Conclusion
The ParaNames 1.0 corpus provides a large-scale, multilingual dataset of entity names that can enable new avenues of research in cross-lingual NLP. By leveraging data from Wikidata, the researchers have assembled a diverse resource spanning over 400 languages, reflecting the rich linguistic tapestry of the world.
This corpus has the potential to support the development of more inclusive and equitable AI systems, particularly in areas like named entity recognition and language modeling. By training models on a broad range of entity names, researchers can work towards building technologies that can accurately understand and interact with people from diverse linguistic and cultural backgrounds.
While the ParaNames corpus has some limitations, it represents an important step forward in the quest to create NLP systems that truly reflect the global nature of human knowledge and communication. Continued refinement and expansion of this resource, combined with interdisciplinary collaboration, can help realize the vision of AI that is accessible and beneficial to all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
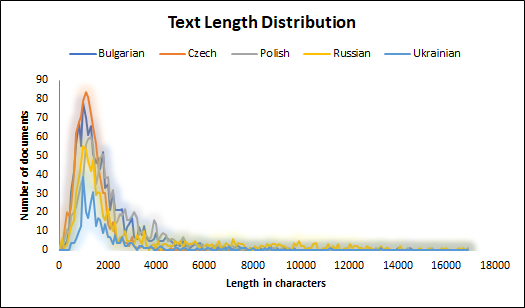
Cross-lingual Named Entity Corpus for Slavic Languages
Jakub Piskorski, Micha{l} Marci'nczuk, Roman Yangarber
0
0
This paper presents a corpus manually annotated with named entities for six Slavic languages - Bulgarian, Czech, Polish, Slovenian, Russian, and Ukrainian. This work is the result of a series of shared tasks, conducted in 2017-2023 as a part of the Workshops on Slavic Natural Language Processing. The corpus consists of 5 017 documents on seven topics. The documents are annotated with five classes of named entities. Each entity is described by a category, a lemma, and a unique cross-lingual identifier. We provide two train-tune dataset splits - single topic out and cross topics. For each split, we set benchmarks using a transformer-based neural network architecture with the pre-trained multilingual models - XLM-RoBERTa-large for named entity mention recognition and categorization, and mT5-large for named entity lemmatization and linking.
4/9/2024

MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
0
0
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
5/21/2024
👁️
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
Sankalp Bahad, Pruthwik Mishra, Karunesh Arora, Rakesh Chandra Balabantaray, Dipti Misra Sharma, Parameswari Krishnamurthy
0
0
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
5/13/2024
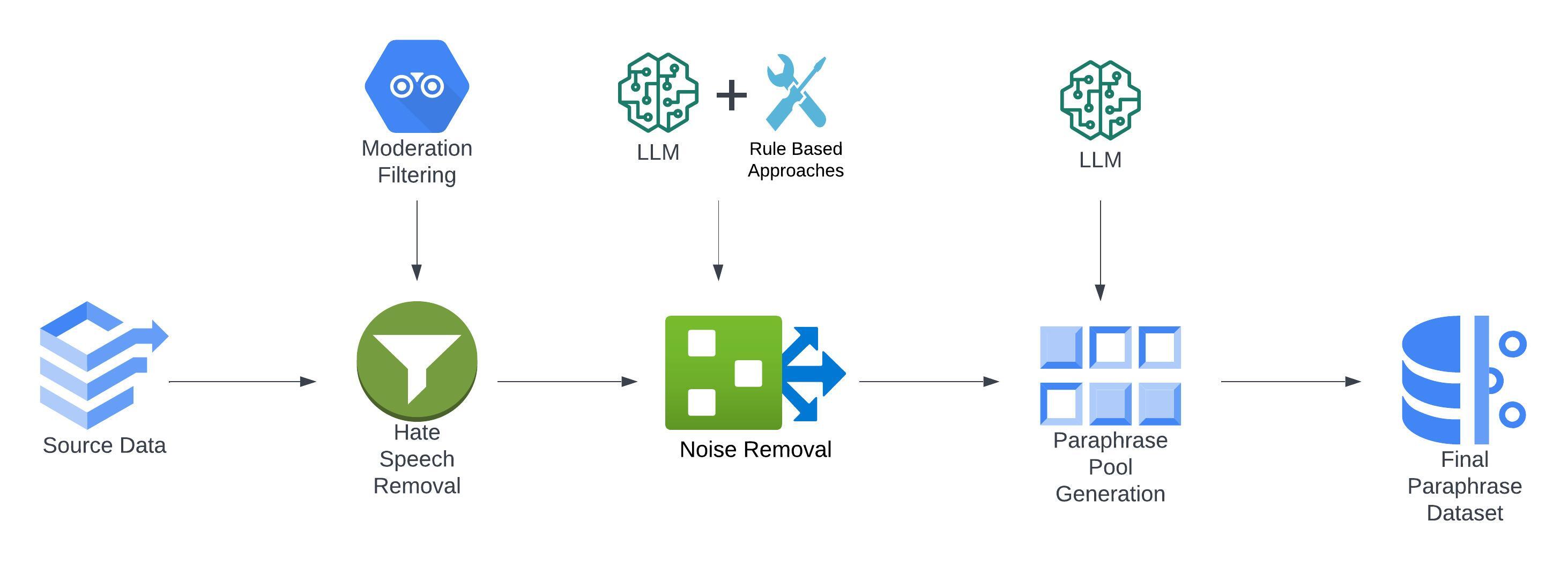
ParaFusion: A Large-Scale LLM-Driven English Paraphrase Dataset Infused with High-Quality Lexical and Syntactic Diversity
Lasal Jayawardena, Prasan Yapa
0
0
Paraphrase generation is a pivotal task in natural language processing (NLP). Existing datasets in the domain lack syntactic and lexical diversity, resulting in paraphrases that closely resemble the source sentences. Moreover, these datasets often contain hate speech and noise, and may unintentionally include non-English language sentences. This research introduces ParaFusion, a large-scale, high-quality English paraphrase dataset developed using Large Language Models (LLM) to address these challenges. ParaFusion augments existing datasets with high-quality data, significantly enhancing both lexical and syntactic diversity while maintaining close semantic similarity. It also mitigates the presence of hate speech and reduces noise, ensuring a cleaner and more focused English dataset. Results show that ParaFusion offers at least a 25% improvement in both syntactic and lexical diversity, measured across several metrics for each data source. The paper also aims to set a gold standard for paraphrase evaluation as it contains one of the most comprehensive evaluation strategies to date. The results underscore the potential of ParaFusion as a valuable resource for improving NLP applications.
4/19/2024