Meta4XNLI: A Crosslingual Parallel Corpus for Metaphor Detection and Interpretation
2404.07053
0
0

Abstract
Metaphors, although occasionally unperceived, are ubiquitous in our everyday language. Thus, it is crucial for Language Models to be able to grasp the underlying meaning of this kind of figurative language. In this work, we present Meta4XNLI, a novel parallel dataset for the tasks of metaphor detection and interpretation that contains metaphor annotations in both Spanish and English. We investigate language models' metaphor identification and understanding abilities through a series of monolingual and cross-lingual experiments by leveraging our proposed corpus. In order to comprehend how these non-literal expressions affect models' performance, we look over the results and perform an error analysis. Additionally, parallel data offers many potential opportunities to investigate metaphor transferability between these languages and the impact of translation on the development of multilingual annotated resources.
Create account to get full access
Overview
- This paper introduces a new crosslingual parallel corpus called Meta4XNLI for metaphor detection and interpretation.
- The corpus contains over 30,000 sentence pairs in 7 languages, with metaphorical and literal versions of the same sentences.
- The dataset is designed to support research on crosslingual metaphor processing and enable better evaluation of multilingual language models.
Plain English Explanation
The paper presents a new dataset called Meta4XNLI that can be used to study how metaphors are understood across different languages. Metaphors are figures of speech where a word or phrase is used to represent something else, like saying "time is money." The researchers created over 30,000 sentence pairs in 7 languages, where each pair has a metaphorical version and a literal version of the same sentence.
For example, a metaphorical sentence might be "She is drowning in work," while the literal version would be "She has a lot of work to do." This dataset allows researchers to investigate how people process and interpret metaphors in different languages. It can also be used to evaluate how well AI language models can handle metaphorical language.
The key innovation of this dataset is that it is "crosslingual," meaning the metaphorical and literal versions are translated across multiple languages. This enables researchers to study how metaphors are understood and expressed differently in various cultures and languages. It's an important resource for developing multilingual AI systems that can accurately process metaphorical language.
Technical Explanation
The researchers created the Meta4XNLI dataset by first collecting a set of English metaphorical sentences from existing metaphor datasets. They then hired professional translators to translate these sentences into 6 other languages: Chinese, French, German, Italian, Portuguese, and Spanish. For each translated sentence, the translators also provided a literal version that expressed the same meaning without any metaphorical language.
This process resulted in a parallel corpus of over 30,000 sentence pairs across the 7 languages. Each pair contains a metaphorical sentence and its literal counterpart. The researchers release this dataset publicly to support research on crosslingual metaphor processing and the evaluation of multilingual language models.
Critical Analysis
The Meta4XNLI dataset is a valuable resource for advancing research on metaphor understanding and crosslingual language processing. However, the authors acknowledge some limitations. The dataset is focused on a specific set of metaphorical expressions, and the literal versions may not always capture the full nuance and connotations of the original metaphorical meaning.
Additionally, the quality of the translations could impact the usefulness of the dataset for certain research tasks. The authors state they used professional translators, but there may still be some inconsistencies or idiomatic differences across the language versions.
Further research could explore expanding the dataset to include a wider range of metaphorical expressions, as well as investigating the impact of translation quality on downstream applications like crosslingual named entity recognition. Overall, the Meta4XNLI dataset represents an important step forward in supporting multilingual AI research on metaphor processing.
Conclusion
The Meta4XNLI dataset introduces a new crosslingual parallel corpus for studying metaphor detection and interpretation. By providing metaphorical and literal sentence pairs across 7 languages, the dataset enables researchers to better understand how metaphors are expressed and understood across different cultures and linguistic contexts.
This resource has significant potential to advance the development of more robust and nuanced multilingual language models, which is critical as AI systems become more widely deployed in global applications. Further research building on the Meta4XNLI dataset can lead to breakthroughs in crosslingual natural language processing and help create AI assistants that can fluently navigate metaphorical language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

XNLIeu: a dataset for cross-lingual NLI in Basque
Maite Heredia, Julen Etxaniz, Muitze Zulaika, Xabier Saralegi, Jeremy Barnes, Aitor Soroa
0
0
XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses.
4/11/2024

New!A Recipe of Parallel Corpora Exploitation for Multilingual Large Language Models
Peiqin Lin, Andr'e F. T. Martins, Hinrich Schutze
0
0
Recent studies have highlighted the potential of exploiting parallel corpora to enhance multilingual large language models, improving performance in both bilingual tasks, e.g., machine translation, and general-purpose tasks, e.g., text classification. Building upon these findings, our comprehensive study aims to identify the most effective strategies for leveraging parallel corpora. We investigate the impact of parallel corpora quality and quantity, training objectives, and model size on the performance of multilingual large language models enhanced with parallel corpora across diverse languages and tasks. Our analysis reveals several key insights: (i) filtering noisy translations is essential for effectively exploiting parallel corpora, while language identification and short sentence filtering have little effect; (ii) even a corpus containing just 10K parallel sentences can yield results comparable to those obtained from much larger datasets; (iii) employing only the machine translation objective yields the best results among various training objectives and their combinations; (iv) larger multilingual language models benefit more from parallel corpora than smaller models due to their stronger capacity for cross-task transfer. Our study offers valuable insights into the optimal utilization of parallel corpora to enhance multilingual large language models, extending the generalizability of previous findings from limited languages and tasks to a broader range of scenarios.
7/2/2024

MMTE: Corpus and Metrics for Evaluating Machine Translation Quality of Metaphorical Language
Shun Wang, Ge Zhang, Han Wu, Tyler Loakman, Wenhao Huang, Chenghua Lin
0
0
Machine Translation (MT) has developed rapidly since the release of Large Language Models and current MT evaluation is performed through comparison with reference human translations or by predicting quality scores from human-labeled data. However, these mainstream evaluation methods mainly focus on fluency and factual reliability, whilst paying little attention to figurative quality. In this paper, we investigate the figurative quality of MT and propose a set of human evaluation metrics focused on the translation of figurative language. We additionally present a multilingual parallel metaphor corpus generated by post-editing. Our evaluation protocol is designed to estimate four aspects of MT: Metaphorical Equivalence, Emotion, Authenticity, and Quality. In doing so, we observe that translations of figurative expressions display different traits from literal ones.
6/21/2024
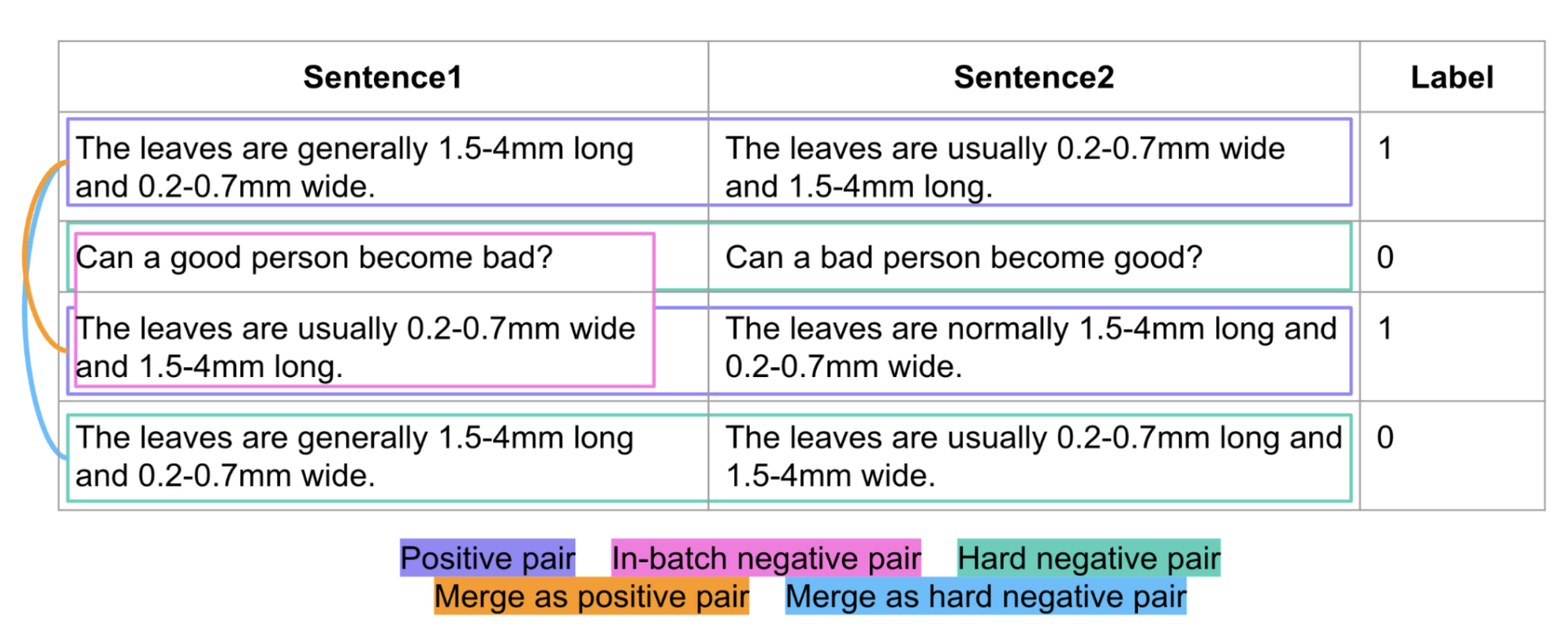
Cross-lingual paraphrase identification
Inessa Fedorova, Aleksei Musatow
0
0
The paraphrase identification task involves measuring semantic similarity between two short sentences. It is a tricky task, and multilingual paraphrase identification is even more challenging. In this work, we train a bi-encoder model in a contrastive manner to detect hard paraphrases across multiple languages. This approach allows us to use model-produced embeddings for various tasks, such as semantic search. We evaluate our model on downstream tasks and also assess embedding space quality. Our performance is comparable to state-of-the-art cross-encoders, with only a minimal relative drop of 7-10% on the chosen dataset, while keeping decent quality of embeddings.
6/24/2024