PARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
2406.15053
0
0

Abstract
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
Create account to get full access
Overview
• This paper presents Pariksha, a large-scale investigation of the agreement between human evaluators and large language models (LLMs) on multilingual and multicultural data.
• The researchers aimed to assess the reliability and validity of using LLMs as substitutes for human evaluators, particularly in cross-cultural and multilingual settings.
Plain English Explanation
• Pariksha is a study that looks at how well human evaluators and LLMs agree when assessing things like the quality of text or the abilities of an AI system.
• The researchers wanted to see if LLMs could be used instead of human evaluators, especially when dealing with content in different languages or from different cultures.
• They gathered a large dataset of evaluations from both humans and LLMs on a variety of tasks, and then analyzed how much the two groups agreed with each other.
Technical Explanation
• The researchers collected a diverse dataset of over 1 million evaluations from human raters and LLMs across 8 languages and 16 cultural contexts.
• They used a range of LLM models, including [models discussed in related papers like METAL, Beyond Metrics, MegaVerse, Judging Judges, etc.], and had both human raters and LLMs evaluate tasks like text quality, translation accuracy, and cultural appropriateness.
• The team analyzed the level of agreement between human and LLM evaluations using metrics like Cohen's kappa and Pearson correlation. They also looked at how factors like language, culture, and task type impacted the agreement levels.
Critical Analysis
• The paper acknowledges limitations in the diversity of human raters and cultural contexts represented in the dataset, which could impact the generalizability of the findings.
• There are open questions around the suitability of using LLMs as substitutes for human evaluators, given potential biases and limitations in LLM capabilities, especially for nuanced cultural assessments.
• Further research is needed to better understand the conditions under which LLM evaluations can reliably approximate human judgments, and to identify specific tasks or domains where they may be most suitable as replacements.
Conclusion
• Pariksha provides important insights into the challenges of using LLMs for cross-cultural and multilingual evaluation tasks, and highlights the need for careful validation before deploying such systems in high-stakes applications.
• The findings underscore the complexity of human evaluation and the difficulty in fully automating such processes, especially when dealing with diverse linguistic and cultural contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024
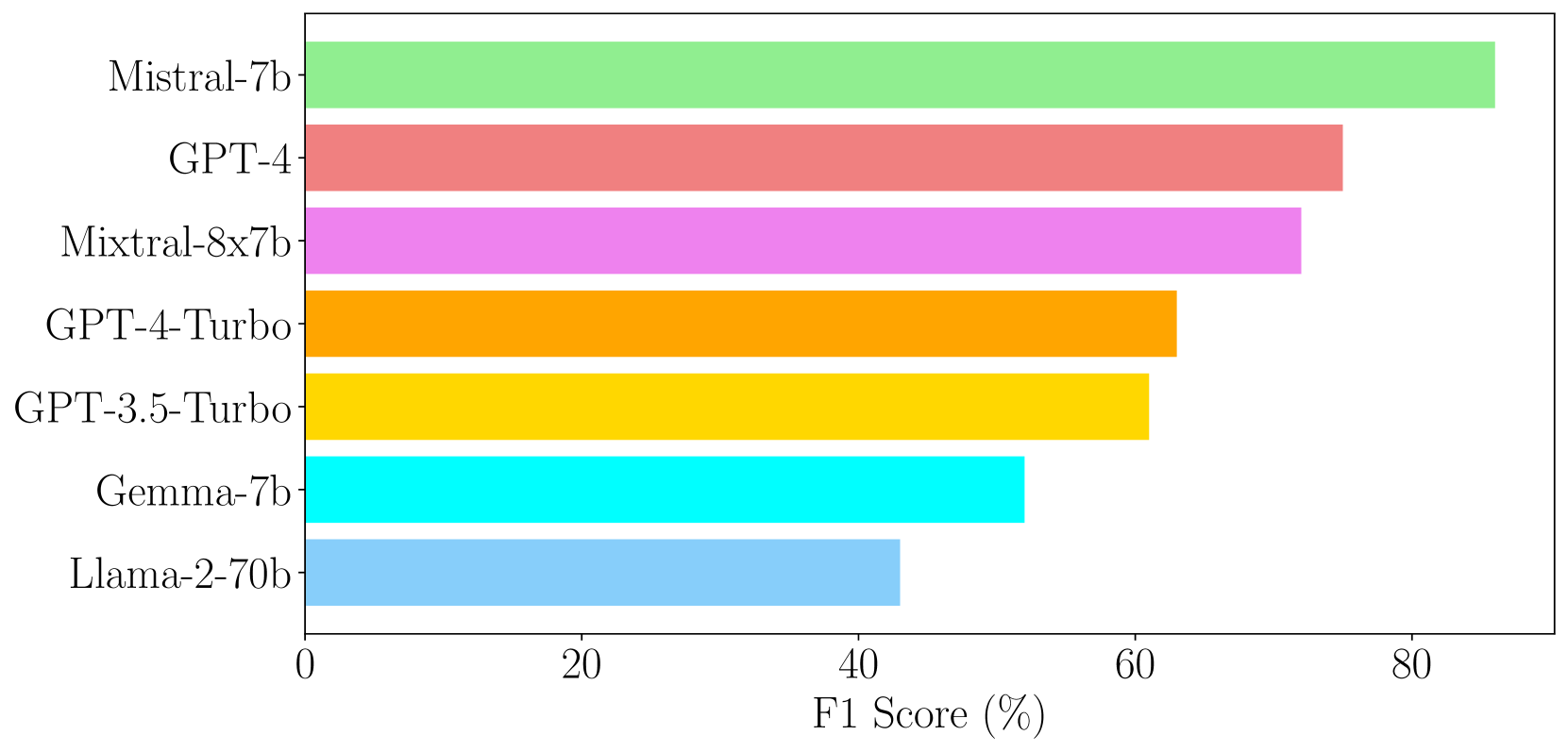
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
0
0
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
6/14/2024

Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
0
0
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
6/19/2024