Parrot: Multilingual Visual Instruction Tuning

0
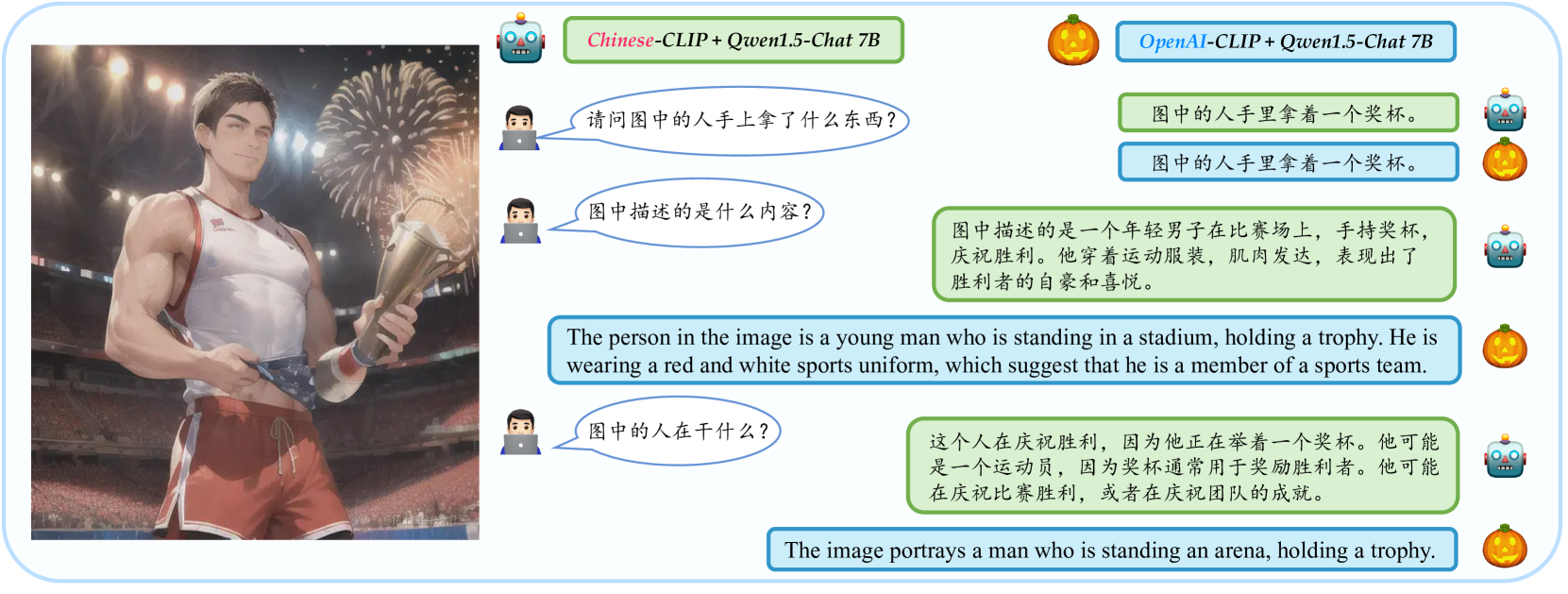
Sign in to get full access
Overview
- The paper presents "Parrot", a multilingual visual instruction tuning model that can follow instructions in multiple languages across various tasks and datasets.
- The researchers introduce "MMMB", a large-scale multilingual multimodal benchmark dataset to evaluate Parrot and other models.
- Parrot achieves state-of-the-art performance on MMMB, outperforming existing models on cross-lingual and cross-modal instruction following tasks.
Plain English Explanation
Parrot is a machine learning model that can understand and carry out instructions given in multiple languages, along with visual information. The researchers created a large dataset called MMMB, which contains instructions and corresponding task completion in over 100 languages. They used this dataset to train Parrot, which learns to comprehend the language and visual cues together to complete the requested tasks.
Compared to other existing models, Parrot demonstrates superior performance on these cross-lingual and cross-modal instruction following tasks. This means Parrot can more accurately interpret and execute instructions that involve both language and visual elements, even when the instructions are given in languages it wasn't specifically trained on.
The significance of this work is that it advances the capabilities of artificial intelligence systems to understand and interact with humans in a more natural, multilingual, and multimodal way. This could have applications in areas like virtual assistants, interactive robotics, and language learning.
Technical Explanation
The key components of the Parrot model are:
- A large pre-trained multilingual language model, similar to AlignGPT, that can understand instructions in over 100 languages.
- A visual encoder that can process images and other visual inputs.
- A cross-modal fusion module that integrates the language and visual information to generate an understanding of the complete instruction.
- A task-specific prediction head that translates the fused representation into actions to complete the instructed task.
The researchers train and evaluate Parrot on the MMMB dataset, which contains over 1 million multilingual, multimodal instruction-following examples spanning a diverse set of tasks like navigation, manipulation, and QA. Parrot sets new state-of-the-art results on MMMB, outperforming prior models like M-PLUG that were not designed for the same level of cross-lingual and cross-modal generalization.
Critical Analysis
One potential limitation of the Parrot model is that it may struggle with very rare or low-resource languages that are underrepresented in the training data. The researchers acknowledge this and suggest further dataset collection and model scaling as ways to address this.
Additionally, the paper does not provide a detailed analysis of the model's performance on specific subsets of the MMMB dataset, such as the most challenging or ambiguous instruction-following tasks. A more nuanced evaluation could reveal areas where Parrot still has room for improvement.
Overall, the Parrot model represents a significant advance in multilingual, multimodal AI systems. However, as with any research, it is important to interpret the results cautiously and continue to push the boundaries of what these models can achieve.
Conclusion
The Parrot model, trained on the MMMB dataset, demonstrates state-of-the-art performance on cross-lingual and cross-modal instruction following tasks. This work advances the field of multilingual, multimodal AI by enabling systems to understand and execute instructions involving both language and visual information, even in low-resource languages.
The potential applications of this technology include more natural and intuitive virtual assistants, interactive robots, and language learning tools. As the research continues to evolve, we can expect to see increasingly capable and versatile AI systems that can seamlessly interact with humans in our diverse, multimodal world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Parrot: Multilingual Visual Instruction Tuning
Hai-Long Sun, Da-Wei Zhou, Yang Li, Shiyin Lu, Chao Yi, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
The rapid development of Multimodal Large Language Models (MLLMs) like GPT-4V has marked a significant step towards artificial general intelligence. Existing methods mainly focus on aligning vision encoders with LLMs through supervised fine-tuning (SFT) to endow LLMs with multimodal abilities, making MLLMs' inherent ability to react to multiple languages progressively deteriorate as the training process evolves. We empirically find that the imbalanced SFT datasets, primarily composed of English-centric image-text pairs, lead to significantly reduced performance in non-English languages. This is due to the failure of aligning the vision encoder and LLM with multilingual tokens during the SFT process. In this paper, we introduce Parrot, a novel method that utilizes textual guidance to drive visual token alignment at the language level. Parrot makes the visual tokens condition on diverse language inputs and uses Mixture-of-Experts (MoE) to promote the alignment of multilingual tokens. Specifically, to enhance non-English visual tokens alignment, we compute the cross-attention using the initial visual features and textual embeddings, the result of which is then fed into the MoE router to select the most relevant experts. The selected experts subsequently convert the initial visual tokens into language-specific visual tokens. Moreover, considering the current lack of benchmarks for evaluating multilingual capabilities within the field, we collect and make available a Massive Multilingual Multimodal Benchmark which includes 6 languages, 15 categories, and 12,000 questions, named as MMMB. Our method not only demonstrates state-of-the-art performance on multilingual MMBench and MMMB, but also excels across a broad range of multimodal tasks. Both the source code and the training dataset of Parrot will be made publicly available. Code is available at: https://github.com/AIDC-AI/Parrot.
Read more8/13/2024
💬
0
Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models
Yuchong Sun, Che Liu, Kun Zhou, Jinwen Huang, Ruihua Song, Wayne Xin Zhao, Fuzheng Zhang, Di Zhang, Kun Gai
Humans often interact with large language models (LLMs) in multi-turn interaction to obtain desired answers or more information. However, most existing studies overlook the multi-turn instruction following ability of LLMs, in terms of training dataset, training method, and evaluation benchmark. In this paper, we introduce Parrot, a solution aiming to enhance multi-turn instruction following for LLMs. First, we introduce an efficient but effective method for collecting multi-turn instructions that feature human-like queries, such as anaphora and ellipsis. Second, we propose a context-aware preference optimization strategy to further enhance LLMs for complex queries in multi-turn interaction. Moreover, to quantitatively evaluate LLMs in multi-turn instruction following, we manually build a multi-turn benchmark derived from existing ones. Extensive experiments show that Parrot improves current LLMs by up to 7.2% in multi-turn instruction following. Our dataset and codes will be open-sourced to facilitate future research.
Read more5/24/2024
💬
0
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
Fei Zhao, Taotian Pang, Chunhui Li, Zhen Wu, Junjie Guo, Shangyu Xing, Xinyu Dai
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
Read more5/24/2024

0
Wings: Learning Multimodal LLMs without Text-only Forgetting
Yi-Kai Zhang, Shiyin Lu, Yang Li, Yanqing Ma, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, the MLLM catastrophically forgets the text-only instructions, which do not include images and can be addressed within the initial LLM. In this paper, we present Wings, a novel MLLM that excels in both text-only dialogues and multimodal comprehension. Analyzing MLLM attention in multimodal instructions reveals that text-only forgetting is related to the attention shifts from pre-image to post-image text. From that, we construct extra modules that act as the boosted learner to compensate for the attention shift. The complementary visual and textual learners, like wings on either side, are connected in parallel within each layer's attention block. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Textual learners are later collaboratively integrated with attention-based routing to blend the outputs of the visual and textual learners. We design the Low-Rank Residual Attention (LoRRA) to guarantee high efficiency for learners. Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. On a newly constructed Interleaved Image-Text (IIT) benchmark, Wings exhibits superior performance from text-only-rich to multimodal-rich question-answering tasks.
Read more6/6/2024