Parrot: Efficient Serving of LLM-based Applications with Semantic Variable

0
Sign in to get full access
Overview
- This paper introduces Parrot, a system that aims to serve Large Language Model (LLM)-based applications more efficiently.
- Parrot uses a technique called "semantic variables" to improve the performance and scalability of LLM-based applications.
- The paper presents the design and implementation of Parrot, as well as experimental results demonstrating its benefits.
Plain English Explanation
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable is a research paper that describes a system called Parrot, which is designed to make it easier and more efficient to run applications that use large language models (LLMs). LLMs are powerful AI models that can understand and generate human-like text, and they are becoming increasingly important in a wide range of applications, from chatbots to device language models to voice-based user interfaces.
However, running LLM-based applications can be challenging, as these models are computationally intensive and can be slow to respond. Parrot aims to address this problem by using a technique called "semantic variables" to improve the performance and scalability of LLM-based applications. Semantic variables are a way of representing the meaning of the input to an LLM, rather than just the literal text. This can help the LLM process the input more efficiently and generate more relevant and coherent responses.
The paper describes the design and implementation of Parrot, and presents experimental results showing that it can significantly improve the performance of LLM-based applications, especially in scenarios where the input is complex or the application needs to handle multiple turns of conversation. This could be particularly useful for marketing applications that rely on LLMs to engage with customers, or for multi-turn instruction-following applications where the user needs to provide a series of commands or instructions.
Technical Explanation
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable introduces a system called Parrot that aims to improve the performance and scalability of applications that use large language models (LLMs). The key innovation in Parrot is the use of "semantic variables" to represent the meaning of the input to the LLM, rather than just the literal text.
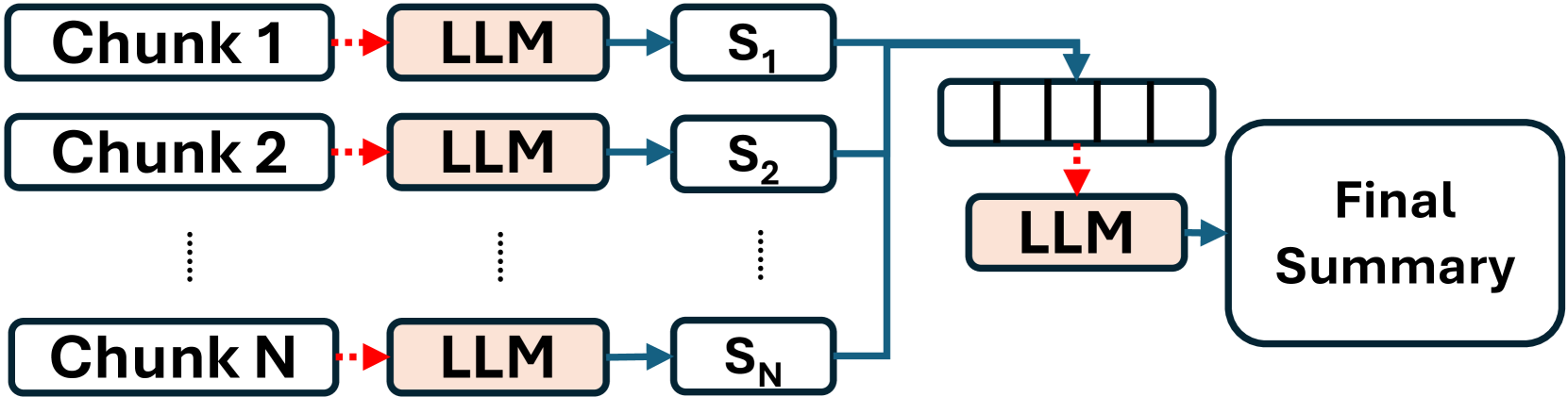
The paper first provides background on the challenges of running LLM-based applications, which can be computationally intensive and slow to respond, particularly in scenarios where the input is complex or the application needs to handle multiple turns of conversation. The authors then present the design and architecture of Parrot, which includes a module for extracting semantic variables from the input, a module for managing the state of the conversation, and a module for efficiently serving the LLM-based application.
The experimental results presented in the paper demonstrate that Parrot can significantly improve the performance of LLM-based applications, with up to a 5x reduction in latency and a 3x increase in throughput compared to a baseline system. The authors also show that Parrot is particularly beneficial for multi-turn instruction-following applications, where the user needs to provide a series of commands or instructions.
Critical Analysis
The Parrot system presented in this paper is a promising approach to improving the efficiency and performance of LLM-based applications. The use of semantic variables to represent the meaning of the input is an interesting idea that could have broader applications beyond the specific use case explored in this paper.
One potential limitation of the Parrot system is that it may require additional effort to integrate with existing LLM-based applications, as it introduces a new abstraction layer and requires the application to be designed with Parrot in mind. The paper does not address how easy or difficult this integration process might be, which could be an important consideration for potential users of the system.
Additionally, the experimental results presented in the paper are based on a specific set of LLM-based applications and datasets. It would be interesting to see how Parrot performs on a wider range of applications and datasets, particularly in real-world scenarios where the input may be more diverse and complex.
Overall, the Parrot system represents an interesting and potentially valuable contribution to the field of LLM-based application serving. However, further research and evaluation would be needed to fully assess its strengths, weaknesses, and broader applicability.
Conclusion
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable introduces a system called Parrot that aims to improve the performance and scalability of applications that use large language models (LLMs). Parrot uses a technique called "semantic variables" to represent the meaning of the input to the LLM, rather than just the literal text, which can help the LLM process the input more efficiently and generate more relevant and coherent responses.
The experimental results presented in the paper demonstrate that Parrot can significantly improve the performance of LLM-based applications, with up to a 5x reduction in latency and a 3x increase in throughput compared to a baseline system. This could be particularly useful for a wide range of applications, from device language models to voice-based user interfaces to marketing applications that rely on LLMs to engage with customers.
Overall, the Parrot system represents an interesting and potentially valuable contribution to the field of LLM-based application serving, and could help to make these powerful AI models more accessible and practical for a wider range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, Lili Qiu
The rise of large language models (LLMs) has enabled LLM-based applications (a.k.a. AI agents or co-pilots), a new software paradigm that combines the strength of LLM and conventional software. Diverse LLM applications from different tenants could design complex workflows using multiple LLM requests to accomplish one task. However, they have to use the over-simplified request-level API provided by today's public LLM services, losing essential application-level information. Public LLM services have to blindly optimize individual LLM requests, leading to sub-optimal end-to-end performance of LLM applications. This paper introduces Parrot, an LLM service system that focuses on the end-to-end experience of LLM-based applications. Parrot proposes Semantic Variable, a unified abstraction to expose application-level knowledge to public LLM services. A Semantic Variable annotates an input/output variable in the prompt of a request, and creates the data pipeline when connecting multiple LLM requests, providing a natural way to program LLM applications. Exposing Semantic Variables to the public LLM service allows it to perform conventional data flow analysis to uncover the correlation across multiple LLM requests. This correlation opens a brand-new optimization space for the end-to-end performance of LLM-based applications. Extensive evaluations demonstrate that Parrot can achieve up to an order-of-magnitude improvement for popular and practical use cases of LLM applications.
Read more5/31/2024
0
Parrot: Multilingual Visual Instruction Tuning
Hai-Long Sun, Da-Wei Zhou, Yang Li, Shiyin Lu, Chao Yi, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
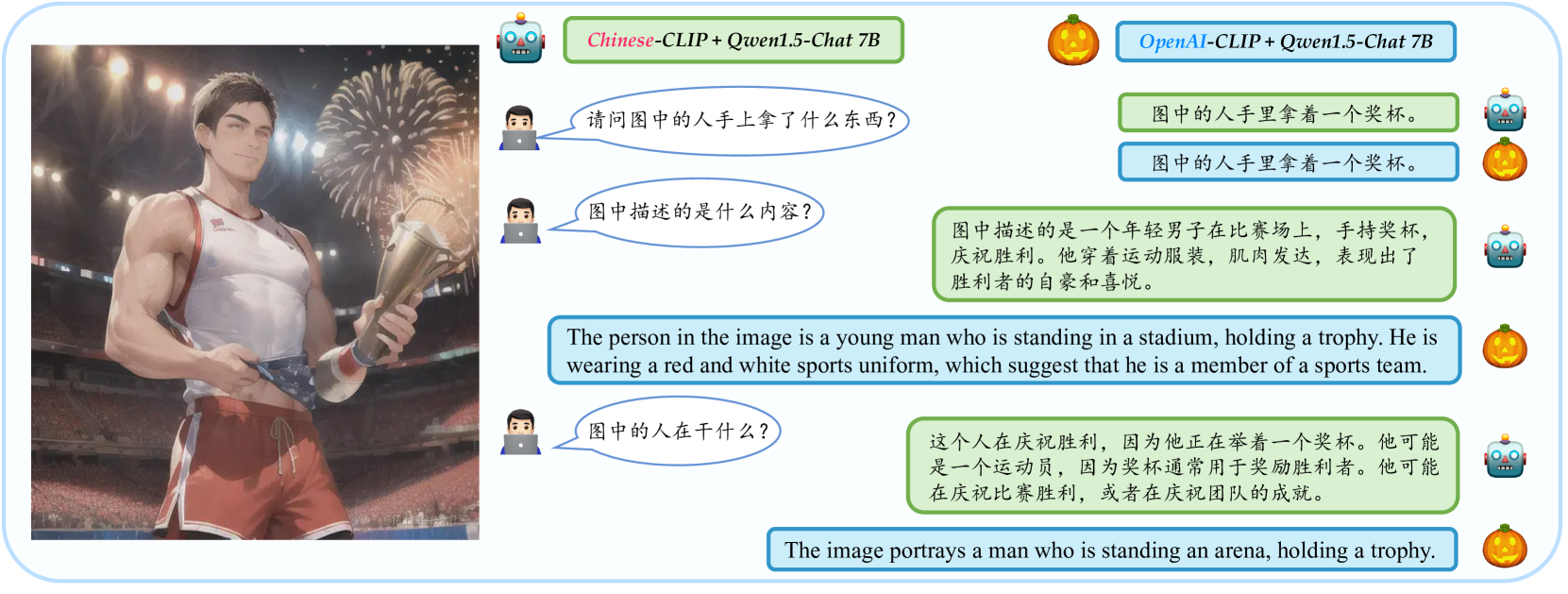
The rapid development of Multimodal Large Language Models (MLLMs) like GPT-4V has marked a significant step towards artificial general intelligence. Existing methods mainly focus on aligning vision encoders with LLMs through supervised fine-tuning (SFT) to endow LLMs with multimodal abilities, making MLLMs' inherent ability to react to multiple languages progressively deteriorate as the training process evolves. We empirically find that the imbalanced SFT datasets, primarily composed of English-centric image-text pairs, lead to significantly reduced performance in non-English languages. This is due to the failure of aligning the vision encoder and LLM with multilingual tokens during the SFT process. In this paper, we introduce Parrot, a novel method that utilizes textual guidance to drive visual token alignment at the language level. Parrot makes the visual tokens condition on diverse language inputs and uses Mixture-of-Experts (MoE) to promote the alignment of multilingual tokens. Specifically, to enhance non-English visual tokens alignment, we compute the cross-attention using the initial visual features and textual embeddings, the result of which is then fed into the MoE router to select the most relevant experts. The selected experts subsequently convert the initial visual tokens into language-specific visual tokens. Moreover, considering the current lack of benchmarks for evaluating multilingual capabilities within the field, we collect and make available a Massive Multilingual Multimodal Benchmark which includes 6 languages, 15 categories, and 12,000 questions, named as MMMB. Our method not only demonstrates state-of-the-art performance on multilingual MMBench and MMMB, but also excels across a broad range of multimodal tasks. Both the source code and the training dataset of Parrot will be made publicly available. Code is available at: https://github.com/AIDC-AI/Parrot.
Read more8/13/2024
💬
0
Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models
Yuchong Sun, Che Liu, Kun Zhou, Jinwen Huang, Ruihua Song, Wayne Xin Zhao, Fuzheng Zhang, Di Zhang, Kun Gai
Humans often interact with large language models (LLMs) in multi-turn interaction to obtain desired answers or more information. However, most existing studies overlook the multi-turn instruction following ability of LLMs, in terms of training dataset, training method, and evaluation benchmark. In this paper, we introduce Parrot, a solution aiming to enhance multi-turn instruction following for LLMs. First, we introduce an efficient but effective method for collecting multi-turn instructions that feature human-like queries, such as anaphora and ellipsis. Second, we propose a context-aware preference optimization strategy to further enhance LLMs for complex queries in multi-turn interaction. Moreover, to quantitatively evaluate LLMs in multi-turn instruction following, we manually build a multi-turn benchmark derived from existing ones. Extensive experiments show that Parrot improves current LLMs by up to 7.2% in multi-turn instruction following. Our dataset and codes will be open-sourced to facilitate future research.
Read more5/24/2024
0
Octopus: On-device language model for function calling of software APIs
Wei Chen, Zhiyuan Li, Mingyuan Ma
In the rapidly evolving domain of artificial intelligence, Large Language Models (LLMs) play a crucial role due to their advanced text processing and generation abilities. This study introduces a new strategy aimed at harnessing on-device LLMs in invoking software APIs. We meticulously compile a dataset derived from software API documentation and apply fine-tuning to LLMs with capacities of 2B, 3B and 7B parameters, specifically to enhance their proficiency in software API interactions. Our approach concentrates on refining the models' grasp of API structures and syntax, significantly enhancing the accuracy of API function calls. Additionally, we propose textit{conditional masking} techniques to ensure outputs in the desired formats and reduce error rates while maintaining inference speeds. We also propose a novel benchmark designed to evaluate the effectiveness of LLMs in API interactions, establishing a foundation for subsequent research. Octopus, the fine-tuned model, is proved to have better performance than GPT-4 for the software APIs calling. This research aims to advance automated software development and API integration, representing substantial progress in aligning LLM capabilities with the demands of practical software engineering applications.
Read more4/3/2024